

The compliance calendar that most legal and technology teams built their EU AI Act roadmaps around has shifted significantly. On 7 May 2026, the European Parliament and Council reached a provisional political agreement on the so-called Digital Omnibus on AI — a package of amendments that pushed several high-risk AI compliance deadlines by more than a year. For teams that had been sprinting toward August 2026, that might sound like breathing room. It is not.
The relief is selective, and misreading which obligations still apply — right now, without any extension — is one of the most consequential mistakes a compliance function can make going into the second half of 2026. Prohibited AI practices have been banned since February 2025. General-purpose AI model obligations have been in force since August 2025. And the full suite of transparency rules under Article 50 go live in August 2026, regardless of the Omnibus amendments.
This post is not a summary of the AI Act. It is a practical enforcement map — covering what has already shifted legally, which obligations are live versus delayed, how national market surveillance authorities actually investigate non-compliance, what the three-tier penalty structure means in commercial terms, and where most organisations have genuine documentation gaps that regulators will find first. The goal is to help compliance teams, legal counsel, and product owners build a credible, prioritised response — not a box-ticking exercise that looks good on paper and falls apart under audit.
The Omnibus Shift: Why August 2026 Is No Longer the Full Story
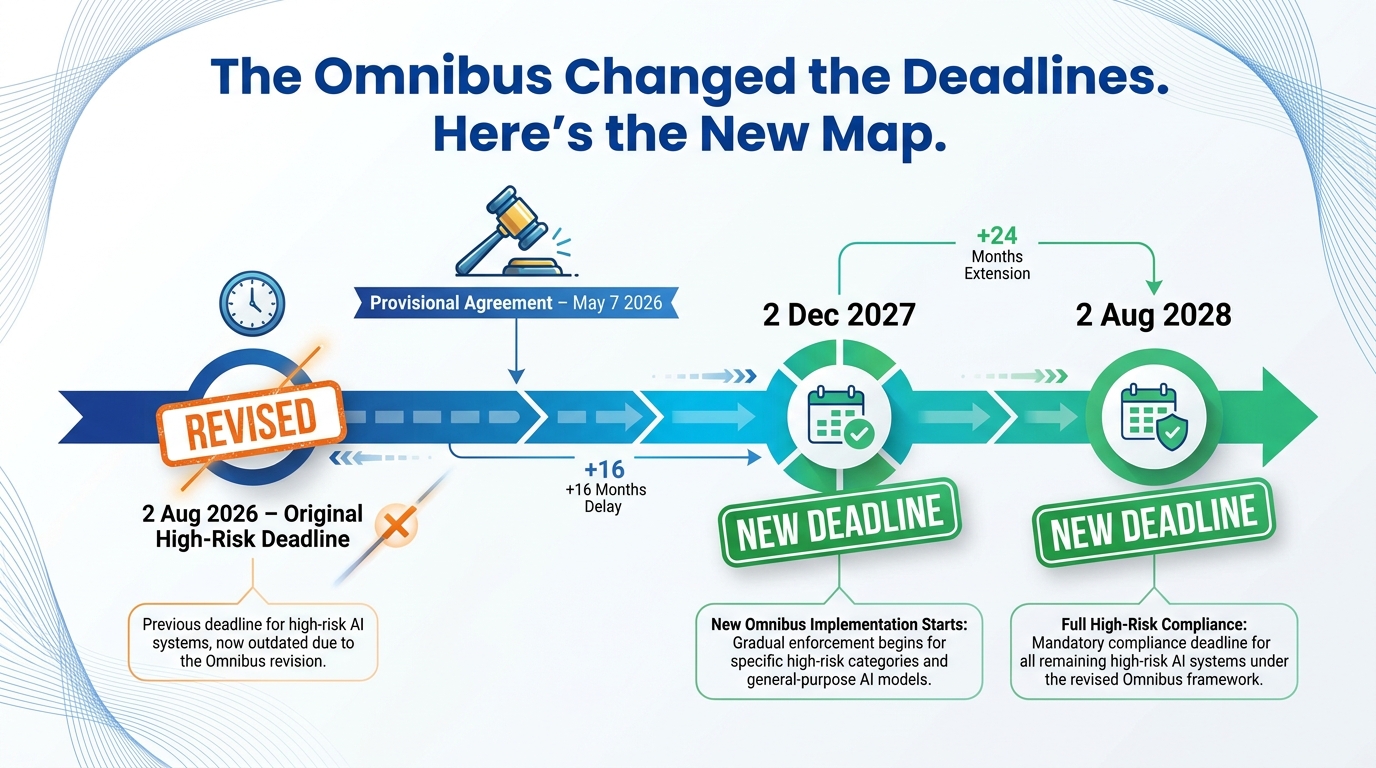
The Digital Omnibus on AI is part of a broader EU legislative simplification effort. Its primary practical effect on the AI Act is moving the application dates for high-risk AI systems. Under the provisional agreement reached in May 2026 — pending formal adoption, which is expected before the original 2 August deadline — the timelines look materially different from what most compliance teams planned for.
The Revised Deadline Map
For Annex III high-risk AI systems — stand-alone applications in sensitive domains such as employment screening, credit scoring, biometric identification, law enforcement tools, education, and critical infrastructure — the application date shifts from 2 August 2026 to 2 December 2027. That is a 16-month extension from the original date.
For Annex I high-risk AI systems — AI embedded in regulated products such as medical devices, vehicles, toys, and industrial machinery — the new deadline is 2 August 2028, a full two years beyond the original.
For most organisations, these extensions feel substantial. But there are three crucial caveats that make “we have until 2027” a dangerous framing to carry into board-level discussions.
What the Omnibus Does Not Change
First, the Omnibus is still pending formal legislative adoption as of mid-2026. Until it passes, the original August 2026 deadline remains the legally applicable one. Compliance teams that stop work based on a provisional agreement that could theoretically still change are taking a significant legal risk.
Second, the Omnibus does not affect the prohibited practices ban (in force since February 2025), GPAI model obligations (in force since August 2025), or the Article 50 transparency rules (due August 2026). These timelines are untouched.
Third, the extension does not mean enforcement posture relaxes. National market surveillance authorities will use the intervening months to build capability, issue guidance, and signal intent. Early enforcement actions — even against more minor transparency violations — will establish precedent for what the broader high-risk regime looks like in practice.
The Prudent Response to the Delay
The Omnibus grants additional calendar time for high-risk AI conformity assessments and technical documentation. It does not grant permission to delay internal governance work, AI system inventorying, vendor due diligence, or the training of human oversight functions. Organisations that use the extension productively will enter the 2027 enforcement window with mature governance frameworks. Those that treat it as a pause will find themselves in the same underprepared position they were in before the summer of 2026 — just 16 months later, with fewer excuses.
What Is Already Live: The Obligations in Force Right Now
Before examining what is coming, compliance teams need a clear-eyed view of what has already happened. The AI Act’s phased rollout means that significant obligations have been in effect for months, and enforcement exposure already exists for companies that have not addressed them.
Prohibited AI Practices (Since 2 February 2025)
Article 5 of the AI Act bans a set of AI applications outright, with no transition period and no grace for SMEs. These prohibitions cover: AI systems that use subliminal techniques to manipulate behaviour in ways that cause harm; systems that exploit vulnerabilities of specific groups (children, people with disabilities, the elderly); government or public authority social scoring systems; real-time remote biometric identification in publicly accessible spaces by law enforcement (with narrow exceptions); AI used to infer emotions in workplaces or educational settings; and AI systems that scrape facial recognition data from the internet or CCTV footage to build or expand identification databases.
Any organisation deploying systems that touch these categories — even tangentially — should have conducted a formal review of that exposure before February 2025. If that review has not happened, it should happen immediately. The penalty for a prohibited AI practice is up to €35 million or 7% of worldwide annual turnover, whichever is higher. There is no softer enforcement pathway for violations at this tier.
GPAI Model Obligations (Since 2 August 2025)
Providers of general-purpose AI models — any model trained on broad data that can perform a wide range of tasks and is placed on the EU market — have been subject to substantive obligations since August 2025. These obligations are not optional pending further guidance. They are in effect.
The core GPAI requirements include: maintaining detailed technical documentation covering model architecture, training methodology, performance benchmarks, and known limitations; providing downstream providers with sufficient information to integrate the model compliantly; publishing a summary of training data content; and complying with EU copyright law, including honouring text-and-data-mining opt-outs.
For providers of systemic-risk GPAI models — those trained on compute exceeding 10^25 FLOPs — there are additional obligations: notifying the AI Office, conducting adversarial testing, reporting serious incidents, and ensuring cybersecurity protections appropriate to the systemic risk they pose.
The Three-Tier Penalty Structure You Cannot Afford to Misread

Article 99 of the AI Act sets out three distinct penalty tiers. Understanding the structure — and more importantly, which behaviour triggers which tier — is not just legal housekeeping. It directly shapes how organisations should allocate their compliance investment.
Tier One: Prohibited AI Practices
The maximum fine for violating Article 5 (the banned practices) is €35 million or 7% of total worldwide annual turnover, whichever is higher. This is the steepest penalty tier in the AI Act, exceeding the maximum GDPR fine percentage. For a large enterprise with €5 billion in global revenue, the potential fine is €350 million. For a mid-sized technology company at €200 million in revenue, it is €14 million — still potentially catastrophic.
The “whichever is higher” mechanism matters enormously here. Unlike fixed-cap regimes, the AI Act links maximum penalties to commercial scale. A global company cannot escape large fines simply because its EU revenue is small.
Tier Two: High-Risk AI and GPAI Non-Compliance
For violations of requirements applicable to high-risk AI systems and most GPAI obligations — failing to maintain a risk management system, inadequate technical documentation, absence of human oversight mechanisms, non-compliant conformity assessments — the maximum is €15 million or 3% of worldwide annual turnover. This tier applies to the majority of substantive compliance failures that organisations with AI products in sensitive domains will face.
Tier Three: Procedural and Information Violations
Providing incorrect, incomplete, or misleading information to notified bodies and national authorities triggers the lowest penalty tier: up to €7.5 million or 1.5% of worldwide annual turnover. This matters because compliance teams often treat documentation and information requests as secondary to substantive technical obligations. Under the AI Act, providing inaccurate information to authorities is itself a separately prosecutable offense.
SME and Startup Proportionality
The AI Act acknowledges that these figures could be existential for very small organisations. National authorities and the AI Office are required to take into account the size, economic situation, and market position of the infringing party when setting actual fines. SMEs and startups are eligible for reduced fines that must not exceed the stated caps but may be set substantially lower in practice. This proportionality principle does not, however, reduce the obligation to comply — only the potential penalty scale if non-compliance is found.
Article 50: The Transparency Rules That Apply to Almost Every AI Product

If there is a single obligation that catches the broadest range of organisations off-guard — including many that do not think of themselves as AI companies — it is Article 50. It applies from August 2026. It is not limited to high-risk systems. And its scope covers a strikingly large share of modern digital products.
The Four Article 50 Triggers
Article 50 creates transparency obligations in four distinct situations:
- AI systems interacting with natural persons — chatbots, virtual assistants, automated phone systems, and AI agents must inform users they are interacting with AI, unless this is obvious from context. “Obvious from context” is a narrow exception, and regulators are expected to interpret it conservatively.
- AI-generated synthetic content — systems that generate audio, images, video, or text must mark that content in a machine-readable format as artificially generated. This includes large language model outputs, AI image generators, and voice synthesis tools.
- Deepfake and manipulated media — deployers using AI to generate or manipulate content that depicts people, places, or events in ways that appear real must disclose that the content is AI-generated. Limited exceptions exist for artistic or satirical work, provided the disclosure does not undermine the purpose.
- Emotion recognition and biometric categorisation — systems that detect or infer emotions, or that categorise people by protected characteristics, must inform subjects that they are being processed by such a system.
What Compliance Actually Looks Like
For most product teams, Article 50 compliance is not a single switch to flip. It requires reviewing every AI-powered user touchpoint in a product — not just the ones that were originally classified as “AI features.” Many organisations have embedded lightweight AI interactions into customer service flows, onboarding sequences, content generation tools, and internal HR platforms without ever formally classifying them as AI interactions for regulatory purposes.
The practical compliance tasks include: auditing all user-facing AI interactions; implementing disclosure mechanisms at the point of first contact (not buried in terms of service); implementing machine-readable marking for generated content, including exploration of standards like C2PA (Coalition for Content Provenance and Authenticity); and ensuring that disclosure language is clear, prominent, and not misleading.
Critically, Article 50 obligations fall on both providers (who build the AI system) and deployers (who use it in a product or service). A company using a third-party chatbot API is a deployer and may carry Article 50 obligations even if it did not build the underlying model. Supply chain AI governance is, therefore, a compliance issue — not just a vendor management one.
The Grey Zone: When Is Something “Obvious”?
The exemption from chatbot disclosure when “obvious from context” that the user is interacting with AI will be the source of significant enforcement debate. A robot icon and the name “Bot” on a chat widget is not necessarily sufficient. Regulators are likely to focus on cases where users could reasonably be misled into thinking they were speaking with a human — particularly in customer service, healthcare, legal advice, and financial guidance contexts. The prudent position is to disclose in every case where any ambiguity exists.
GPAI Model Obligations: What Providers Must Have Already Done
For organisations that develop and deploy general-purpose AI models — whether proprietary foundation models, fine-tuned derivatives, or open-weight releases — the August 2025 deadline has already passed. This section is not about preparing for a future obligation. It is about assessing whether existing compliance is adequate under a regime that has been live for nearly a year.
Technical Documentation: The Core Deliverable
The AI Act’s technical documentation requirements for GPAI models are extensive. Providers must maintain documentation covering: the general description of the model and its intended purposes; the training data used, including sources, filtering methodology, and data governance practices; training methodology and compute resources used; model performance on relevant benchmarks; known limitations, risks, and failure modes; and information about any post-training procedures such as RLHF or fine-tuning.
This documentation is not a one-time filing. It must be kept up to date and made available to the AI Office on request. For commercial GPAI providers, it also informs the information package that must be shared with downstream deployers — the developers and enterprises building applications on top of the model. If your API documentation is the sum total of your compliance information package for downstream users, that is almost certainly not sufficient.
Copyright and Training Data
One of the most actively debated GPAI obligations is the requirement to comply with EU copyright law in training data collection, specifically the requirement to honour text-and-data-mining opt-outs under the Digital Single Market Directive. Providers must document their approach to identifying and respecting opt-outs, and must publish a summary of training data content that is sufficiently detailed for downstream users to assess copyright risk.
This obligation has attracted significant attention from rights-holders and publishers. Organisations that trained models on broad internet data without implementing robust opt-out mechanisms should take legal advice on their current exposure — because the AI Office has both the mandate and the appetite to investigate copyright-adjacent GPAI compliance issues.
Systemic Risk Model Notification
Providers of GPAI models trained on more than 10^25 FLOPs are classified as systemic-risk models and must notify the AI Office. This notification triggers additional obligations: conducting model evaluations and adversarial testing (including red-teaming); reporting serious incidents or malfunctions to the AI Office; implementing cybersecurity measures commensurate with systemic risk; and maintaining a documented incident response framework.
The number of organisations meeting the compute threshold for systemic risk classification is small — this is primarily a concern for the largest AI labs and foundation model providers. But for those organisations, the obligations are materially more demanding than for standard GPAI providers.
High-Risk AI Systems: The New Conformity Assessment Roadmap
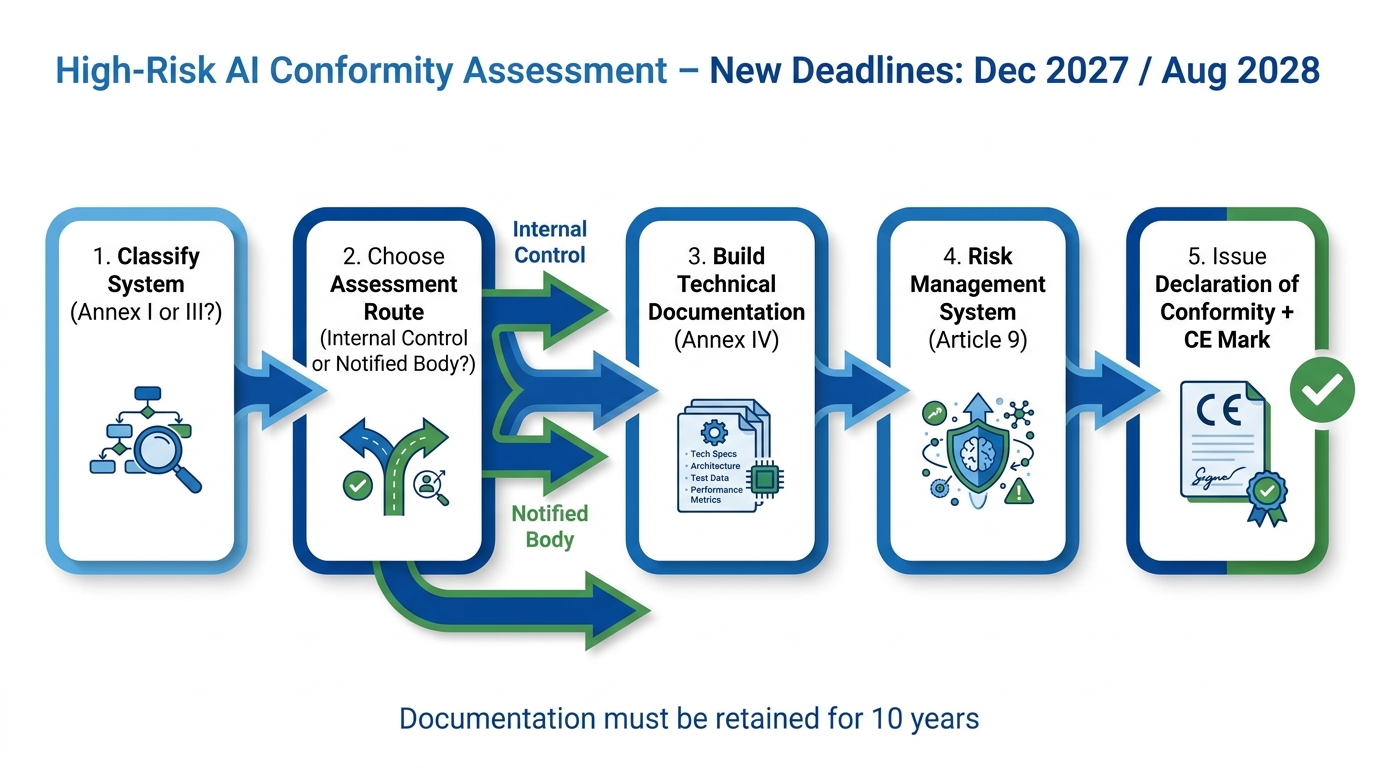
With the Omnibus extension moving high-risk AI compliance deadlines to December 2027 and August 2028, organisations with products in Annex III and Annex I categories have more runway. But the conformity assessment process is sufficiently complex that beginning substantive work now — rather than in 2027 — is the only realistic path to timely compliance.
Step One: Classification
The first step in any conformity assessment is determining whether your system actually qualifies as high-risk. Annex III lists the categories: biometric identification and categorisation of natural persons; management and operation of critical infrastructure; education and vocational training; employment, workers management, and access to self-employment; access to and enjoyment of essential private services and essential public services; law enforcement; migration, asylum, and border control management; and administration of justice and democratic processes.
Being in one of these domains does not automatically make a system high-risk. The AI Act provides that some systems in Annex III categories are not high-risk if they do not pose a significant risk of harm to health, safety, or fundamental rights of natural persons. The Commission guidance on this classification question — originally due in February 2026 — is a key input that compliance teams should track and apply retroactively to their system inventories.
Step Two: Choosing Your Assessment Route
Article 43 provides two main conformity assessment pathways for high-risk AI systems. Most Annex III systems can use Route A: internal control (Annex VI), where the provider conducts and documents its own conformity assessment against the legal requirements. This is analogous to self-declaration under product safety law and does not require a third party.
A smaller subset — primarily AI used for real-time remote biometric identification and certain Annex I product-safety systems — requires Route B: third-party assessment by a notified body (Annex VII). Notified bodies must be designated by member states, and the designation process is still maturing across the EU. Organisations expecting to need notified body involvement should begin identifying and engaging candidate bodies now, given capacity constraints that are likely to emerge as the 2027 deadline approaches.
Step Three: Technical Documentation Under Annex IV
Annex IV specifies the minimum content of technical documentation for high-risk AI systems. The requirements are detailed and include: a general description of the system including its purpose, the interaction with hardware or software components it relies on, and the version history; a description of the elements of the system and the development process; information on training methodology and datasets; a description of the risk management system; post-market monitoring plan; and evidence of testing results demonstrating conformity with the requirements.
Documentation must be created before the system is placed on the market, kept current throughout the system’s lifecycle, and retained for at least ten years after the last unit is placed on the market. For software-based AI systems that update frequently, maintaining current documentation across model versions is a genuine operational challenge that requires systematic processes — not ad hoc efforts.
Step Four: Risk Management System
Article 9 requires that high-risk AI providers maintain a risk management system as an ongoing iterative process, not a one-time assessment. This system must identify and analyse known and foreseeable risks; estimate and evaluate the risks that emerge during testing and from intended use; adopt risk mitigation and control measures; and test against those measures to ensure they work. The risk management system must remain operational throughout the lifecycle of the AI system, including post-deployment. This is a meaningful ongoing operational requirement, not a project to complete before market launch.
Step Five: Declaration of Conformity
Once conformity assessment is complete, providers issue a Declaration of Conformity (DoC) — a formal statement that the system meets all applicable requirements. For Annex I systems, this is accompanied by a CE marking. The DoC must identify the system, the provider, and the specific requirements the system has been assessed against. It must be kept on file and made available to market surveillance authorities on request. Providing a false or misleading DoC is itself a violation under the Article 99 penalty framework.
Market Surveillance Authorities: Who’s Watching and How They Investigate

Understanding enforcement architecture is not academic. It directly shapes where your first interaction with a regulator is likely to come from, how quickly an investigation could escalate, and what remediation process looks like in practice.
The Hybrid Model: EU Level and National Level
The EU AI Act operates through a hybrid enforcement model confirmed by the European Parliament’s Think Tank in March 2026. At the EU level, the European AI Office — housed within DG CONNECT — is responsible for supervising GPAI models, coordinating cross-border enforcement, and addressing systemic risks. It has direct investigatory powers over GPAI providers and can impose fines through the Commission.
At the national level, each member state must designate at least one market surveillance authority (MSA). MSAs are responsible for post-market monitoring of AI systems, investigating complaints and suspected non-compliance, requesting documentation from providers and deployers, ordering corrective actions and withdrawals, and imposing fines under national law. The AI Act requires MSAs to be independent, adequately resourced, and coordinated with the AI Office — though the resource adequacy requirement is proving difficult in practice, particularly for smaller member states.
How an Investigation Actually Starts
MSA investigations can be triggered in several ways: complaints from individuals, civil society organisations, or competitors; market sweeps initiated by the authority itself; incident reports submitted by providers; referrals from other regulatory bodies (such as data protection authorities or financial supervisors); and cross-border coordination from other member states’ MSAs via the AI Board’s coordination mechanisms.
An initial investigation typically involves a request for documentation — the technical file, risk management records, conformity assessment evidence, and any post-market monitoring logs. Organisations that cannot produce complete, organised documentation quickly find that an information request escalates into a formal investigation far more rapidly than those that have robust compliance infrastructure. Response time to documentation requests matters: delayed or incomplete responses are themselves procedural violations under the Tier Three penalty framework.
Cross-Border Cases and the AI Board
AI systems operating across multiple EU member states create multi-jurisdictional enforcement risk. The AI Board — composed of representatives from each member state’s competent authority — coordinates enforcement in cross-border cases and can refer matters to the AI Office where systemic risk or GPAI model issues are involved. For large technology companies with EU-wide products, the risk of simultaneous investigation by multiple national MSAs, coordinated by the AI Board, is real — and managing it requires a centralised compliance function with the ability to respond consistently across jurisdictions.
The SME Problem: Why Smaller Companies Face Disproportionate Risk
The AI Act’s proportionality provisions and SME-specific guidance give the impression that smaller organisations have a lighter regulatory burden. In practice, the opposite is often true — SMEs and scale-ups face disproportionate compliance challenges for reasons that have nothing to do with the legal text and everything to do with organisational capability.
The “Not Applicable” Mistake
The most common and most dangerous mistake that smaller organisations make is concluding too quickly that the AI Act does not apply to them. This error stems from two sources: a misunderstanding of the risk classification system, and a failure to recognise that “deployer” obligations apply even when you are using someone else’s model.
A startup that uses an off-the-shelf large language model to power a customer-facing chatbot for a financial services application may not think of itself as an “AI company.” But it is a deployer of an AI system in a potentially high-risk context (financial services access), and it carries Article 50 transparency obligations, plus potentially high-risk compliance obligations once those deadlines apply. The off-the-shelf nature of the underlying technology does not eliminate the deployer’s compliance exposure.
Vendor Due Diligence Is a Compliance Obligation
Under the AI Act’s supply chain model, deployers must receive sufficient information from providers to meet their own compliance obligations. If a GPAI provider is not supplying adequate technical documentation, training data summaries, or performance and limitation information, the deployer cannot meet its own obligations — and cannot pass compliance responsibility back to the provider simply by pointing to a contract clause.
SMEs should be actively reviewing their AI vendor contracts and technical documentation packages. Contracts should specify: what documentation the provider must supply; what notification process applies if the provider makes material changes to the model; and what remediation options exist if the provider’s non-compliance creates compliance risk for the deployer. This due diligence is substantive legal work, not a procurement checkbox.
AI Literacy as a Legal Obligation
One obligation that is already in force and affects all organisations, regardless of size, is the AI literacy requirement under Article 4. Providers and deployers must ensure that their staff have a sufficient level of AI literacy — appropriate to their roles and the context in which they use AI. This is not a training module. It is a documented organisational competency obligation. Regulators investigating a non-compliance case will ask how staff were trained to use and oversee AI systems. The answer must be substantive.
Building Your Internal Compliance Function: More Than Checklists
The most common framing of AI Act compliance work is as a checklist problem — gather the documentation, tick the boxes, issue the declaration. That framing consistently produces compliance programmes that look good on paper but collapse under the scrutiny of an actual investigation. Effective compliance is structural.
The AI Inventory: Your Compliance Foundation
You cannot manage compliance for AI systems you have not catalogued. The first substantive work any compliance function must complete is an AI system inventory — a structured register of every AI system the organisation uses or deploys, covering: what the system does; who built it; what data it processes; who it interacts with or makes decisions about; what risk category it falls under; and what obligations apply as a result.
For most organisations with more than a few years of AI adoption behind them, this inventory will surface surprises. AI integrations made at the business unit level that legal and compliance teams were never told about. API-based AI tools embedded in SaaS products the organisation uses as a deployer. AI-assisted decision processes in HR, finance, or operations that may qualify as high-risk under Annex III. The inventory is not a one-time exercise — it needs to be maintained as a living register, updated as new systems are deployed or existing ones change materially.
Role Clarity: Provider Versus Deployer
The AI Act assigns different obligations to providers (who develop and place AI systems on the market) and deployers (who use AI systems in a professional context). Many organisations are both simultaneously — developing and deploying proprietary AI while also using third-party AI in their products and operations.
Role clarity is not just a legal formality. It determines which compliance obligations the organisation owns directly, which it partially inherits from its providers, and which it can discharge through contractual requirements on the other party. Internal teams need clear ownership maps: who is accountable for provider obligations on proprietary systems, who manages deployer obligations for third-party systems, and where those two worlds overlap and create joint accountability.
Governance Structures That Withstand Scrutiny
Market surveillance authorities will look not just at whether documentation exists, but at whether the governance processes that generate and maintain that documentation are credible. That means: governance committees or review bodies with genuine oversight authority; escalation pathways that bring AI risk issues to appropriate decision-makers; documented processes for reviewing AI systems when they are substantially modified; and incident response procedures that include the obligation to report serious incidents to the AI Office or national authorities as required.
The human oversight requirement under Article 14 is particularly significant for high-risk AI systems. It is not satisfied by a single human in the loop who approves AI outputs without meaningful ability to understand or override them. Regulators will examine whether oversight mechanisms are real — whether the humans responsible have the training, access, and authority to actually intervene. Documentation of how human oversight is implemented, trained, and tested is a core component of any credible compliance programme.
The Documentation Gap: What Regulators Will Find First
Among the practical compliance failures that regulators and legal teams are identifying in 2026 audits, documentation gaps are by far the most prevalent. Organisations often have reasonable processes in place but have not documented them in the forms that the AI Act specifies. This creates a gap between what a company is actually doing and what it can demonstrate it is doing — and in enforcement, demonstration is what matters.
The Most Common Documentation Failures
Based on practitioner analysis of pre-enforcement compliance gaps, the most common documentation failures are:
- Incomplete or absent technical files. Annex IV specifies what technical documentation must contain, but many organisations’ technical files are a collection of internal engineering documents that do not map to the Annex IV structure. A regulator asking for your technical file should receive a document that is readable without prior knowledge of your internal systems and that directly addresses each Annex IV requirement.
- Undocumented risk management processes. The Article 9 risk management system must be an ongoing documented process. Meeting logs, risk registers, mitigation decisions, and testing results all form part of the required record. Undocumented risk management — even if the organisation is doing substantive risk work — will not satisfy an MSA investigation.
- Absent or outdated post-market monitoring logs. Article 72 requires high-risk AI providers to have a post-market monitoring system that collects and reviews data on the system’s performance after deployment. For most software AI systems, this means logging user feedback, error rates, model drift indicators, and incident data. These logs must exist, must be structured, and must be reviewed on a documented schedule.
- Missing supplier information packages. Deployers must receive sufficient information from GPAI providers to meet their own compliance obligations. Many deployers have not requested this information formally, and many providers have not supplied it in a structured way. Both sides of this transaction need to address the gap.
- No version control on technical documentation. AI systems change. Models are updated. Training data evolves. The technical documentation must reflect the current state of the system, not the state at initial deployment. Organisations without systematic documentation version control create a compliance gap every time they update their models.
Retention Requirements and Audit Readiness
Technical documentation for high-risk AI systems must be retained for ten years after the last unit is placed on the market. For software products with continuous update cycles, the retention clock may effectively never run out. Compliance teams need to establish document retention policies that reflect this requirement, with appropriate security controls and access management for stored documentation.
Audit readiness is a distinct capability from compliance. A company may be substantively compliant but operationally unable to demonstrate that compliance within the timeframes that an MSA investigation imposes. Building the systems to retrieve, compile, and present compliance evidence quickly is as important as building the compliance processes themselves.
Practical Compliance Checklist: Where to Start This Week
Compliance work under the EU AI Act is not a single project with a completion date. It is an ongoing operational function. But for teams that need to prioritise, the following represents the highest-return starting points — actions that address the most immediate enforcement exposure and build the foundation for longer-term compliance maturity.
Immediate Priorities (Before August 2026)
- Complete a prohibited practices audit. Review every AI system in use against the Article 5 ban list. If any system touches the banned categories — social scoring, emotion detection in workplaces, subliminal manipulation, indiscriminate biometric data scraping — get legal advice on exposure immediately. This obligation has been in force since February 2025.
- Assess Article 50 compliance for all user-facing AI. Map every touchpoint where AI interacts with users or generates content. Determine which ones require disclosure, implement that disclosure, and document the implementation decision for each system. August 2026 is not far off.
- Audit GPAI vendor documentation packages. If you use any large language model or other GPAI model in your products, request and review the provider’s technical documentation package. Confirm that it meets the AI Act’s information requirements. Flag any gaps to the provider in writing and keep the correspondence on file.
- Implement the Article 4 AI literacy requirement. Document the AI literacy baseline for staff who use or oversee AI systems in professional contexts. Create or commission role-appropriate training. Record completion. This is in force now.
- Start your AI system inventory. Even a basic structured spreadsheet identifying every AI system the organisation uses or deploys, with fields for role (provider/deployer), risk category assessment, and applicable obligations, is a materially better position than having no inventory at all.
Medium-Term Priorities (Before December 2027)
- Classify all AI systems against Annex III. For systems that may qualify as high-risk, complete a formal classification assessment referencing the Commission’s Article 6 guidance when published, and document the reasoning.
- Begin technical documentation under Annex IV. Do not wait until 2027 to start building technical files. The process surfaces compliance gaps in your AI systems that need engineering or process work to address — work that takes time.
- Design your Article 9 risk management system. Establish a documented, ongoing risk management process for each high-risk AI system. Define the review cycle, the responsible parties, the risk criteria, and the escalation thresholds.
- Build human oversight mechanisms into product design. The Article 14 requirement for human oversight must be implemented in the design of high-risk AI systems — it is not something that can be bolted on retrospectively without significant engineering work.
- Engage notified bodies early if required. For systems requiring Route B conformity assessment, begin identifying and engaging notified bodies now. Capacity constraints will be significant in 2027 as high-risk AI deadlines approach.
Conclusion: Compliance Is a Competitive Position, Not Just a Legal Obligation
The EU AI Act represents the most comprehensive attempt by any jurisdiction to regulate AI at scale. Its phased implementation, punctuated by the significant Omnibus amendments of May 2026, has created a compliance environment that is genuinely complex — with different obligations applying on different timelines to different categories of AI system, across a hybrid enforcement architecture involving both national authorities and the AI Office.
What makes that complexity manageable is approaching compliance not as a regulatory penalty avoidance exercise, but as an organisational capability. Companies with mature AI governance — documented risk management, comprehensive technical files, clear role accountability, functioning human oversight, and audit-ready documentation — are better-positioned not just for regulatory scrutiny, but for enterprise sales, procurement qualification, and the institutional trust that is increasingly required to deploy AI in sensitive domains.
The Omnibus extensions on high-risk AI deadlines are real. But the enforcement infrastructure — national MSAs, the AI Office, the AI Board — is being built in parallel. The investigations that will set early precedent for how the AI Act is enforced in practice will come before the 2027 deadlines, most likely from Article 50 transparency failures, GPAI documentation gaps, and prohibited practices violations that have already been in effect for over a year.
The organisations that will navigate this environment most effectively are those that treat the current compliance window not as permission to wait, but as an opportunity to build — governance frameworks, documentation processes, oversight mechanisms, and vendor relationships that will withstand the scrutiny that is, without question, coming.
Key Takeaway: The Omnibus moved the high-risk AI deadlines. It did not move the enforcement intent. Article 50, prohibited practices, and GPAI obligations are live now. Start there — then use the extended runway on high-risk conformity assessments to build something that will last.














