
There’s a pattern to how AI news gets covered: a flashy announcement drops, the internet erupts, hyperbolic takes flood social media, and then — within days — the next thing arrives and everyone moves on. The result is a public understanding of AI that’s simultaneously overinflated in some areas and dangerously underinformed in others.
So let’s do something different. Instead of chasing individual headlines, this piece pulls back the lens and looks at the full picture of where AI actually stands right now — in mid-2026 — across models, deployment, hardware, regulation, jobs, law, and philosophy. Every section is backed by current data. None of it is speculation dressed up as insight.
Whether you’re a business leader trying to figure out where to deploy resources, a professional worried about your role, a policy watcher tracking regulation, or simply someone who wants to separate signal from noise — this is the briefing you actually need.
The AI story of 2026 isn’t about any single model or any single company. It’s about a technology that has decisively moved from experimentation into production — and a world that is only beginning to reckon with what that means.

The Model Wars: GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro Go Head-to-Head
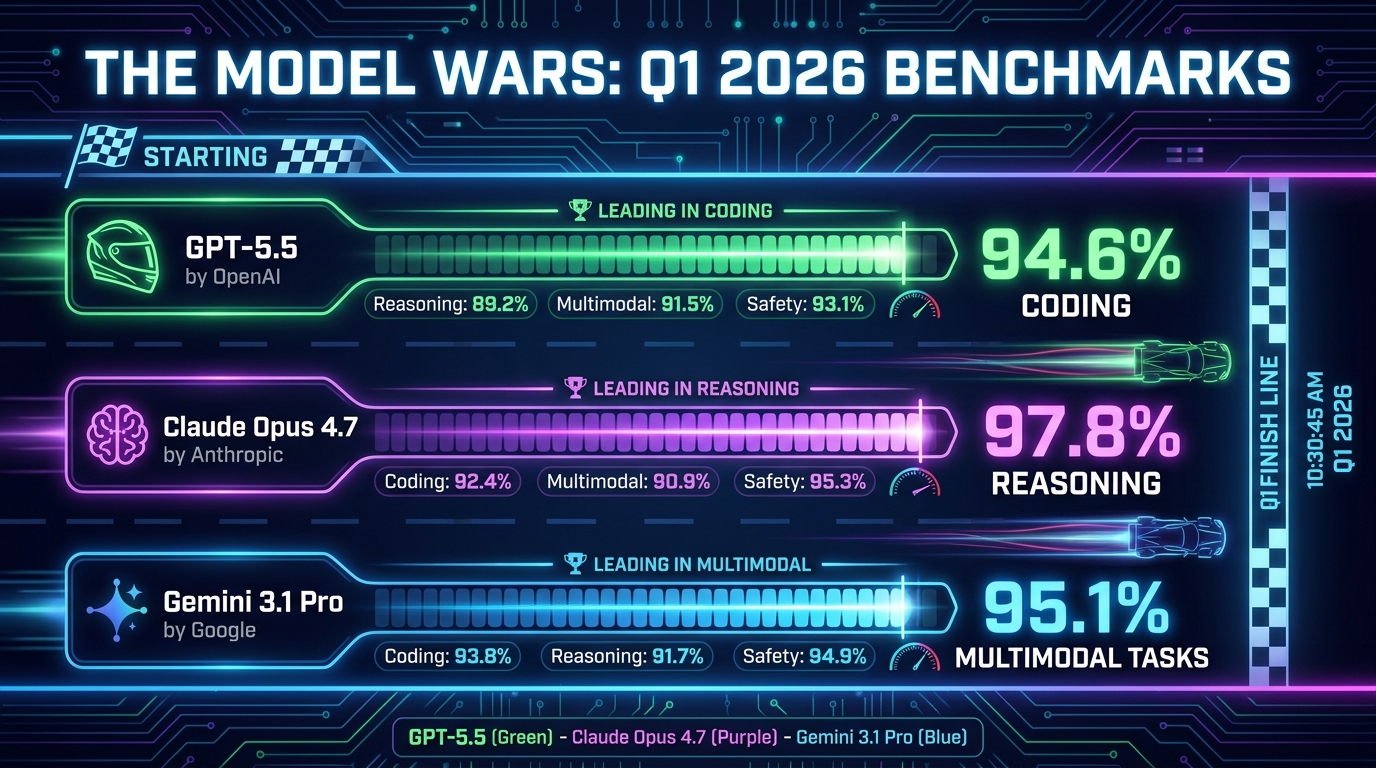
The top of the AI model stack looks nothing like it did even twelve months ago. The pace of releases in Q1 2026 has been extraordinary, with OpenAI, Anthropic, and Google all shipping significant capability updates within weeks of each other — and the benchmark numbers are, frankly, difficult to contextualize without standing back and asking: what are we actually measuring?
OpenAI: GPT-5.4, GPT-5.5, and the Road to “Spud”
OpenAI’s current flagship lineup includes GPT-5.4, which introduced configurable reasoning depth, a 1 million token context window, and meaningfully improved tool use for agentic applications. On coding benchmarks, GPT-5.4 Pro scores 94.6% — a number that would have seemed science fiction two years ago. The model also claims a 30% reduction in hallucination rates compared to its predecessors, which matters enormously for enterprise deployments where accuracy isn’t optional.
Hot on its heels is GPT-5.5, internally codenamed “Spud,” which has completed pretraining and focuses specifically on agentic operating system interaction and long-term memory. The model is designed not just to answer questions but to operate within software environments — opening files, running code, navigating browsers — with sustained context over extended sessions. This is a meaningful architectural distinction from chatbot-style models, and it signals where OpenAI sees the real commercial opportunity: not in conversations, but in autonomous workflows.
It’s also worth noting that OpenAI’s model family now spans from GPT-5 Nano (priced at $0.05 per million tokens, built for edge device inference) all the way to GPT-5.4 Pro. This tiered architecture reflects a maturation of the business model — different price points and capability levels for different use cases, rather than one size fits all.
Anthropic: Claude Opus 4.7 and the Reasoning Lead
Anthropic’s Claude Opus 4.7 is currently the top performer in reasoning-focused benchmarks, scoring between 83.5% and 97.8% across various evaluations depending on the task type. The range reflects a key reality: these models don’t dominate uniformly. They have distinct strengths.
Where Claude consistently pulls ahead is in nuanced prose, safety-constrained outputs, and tasks requiring careful multi-step reasoning with low tolerance for error. Anthropic has also unveiled several significant features alongside the Opus 4.x series: self-healing memory (the ability to recognize and correct inconsistencies in its own prior outputs), an agentic system called KAIROS, and a feature called Undercover Mode designed to reduce social desirability bias in outputs — meaning the model is less likely to tell you what it thinks you want to hear.
This last feature is particularly interesting from an enterprise standpoint. AI systems that are optimized for user approval can be subtly dangerous: they agree too readily, soften bad news, and reinforce poor decisions. Anthropic’s explicit effort to counter this reflects a growing sophistication in how frontier labs think about deployment quality versus raw performance metrics.
Google: Gemini 3.1 Pro and the Multimodal Advantage
Google’s Gemini 3.1 Pro is natively multimodal in a way that its competitors are still working toward — meaning it doesn’t process text, images, audio, and video through separate modules bolted together, but through a unified architecture. This gives it a measurable edge in tasks requiring cross-modal reasoning: describing what’s happening in a video clip, interpreting charts, or answering questions that combine text with visual data.
Gemini 3.1 Pro also carries a 2 million token context window, the largest currently available in a production model. This enables use cases like analyzing entire legal case files, codebases, or multi-year financial histories in a single pass — without the information loss that comes from chunking and summarizing.
Beyond the raw model, Google has aggressively integrated Gemini into its product ecosystem. In its March 2026 update push, Google expanded Gemini’s role in Search Live, Google Maps (conversational navigation), Docs, Sheets, Slides, and Drive. The strategy is clearly to make Gemini invisible infrastructure — so deeply embedded in tools people already use that adoption becomes friction-free. It’s a different go-to-market from OpenAI’s more standalone product approach, and it may ultimately be more durable.
The key takeaway here: No single model “wins” in 2026. GPT-5.5 leads in coding and agentic tasks. Claude Opus 4.7 leads in reasoning and safety. Gemini 3.1 Pro leads in multimodal and long-context applications. The smart move for any organization is selecting models based on task type, not brand loyalty.
Agentic AI Is No Longer a Concept — 51% of Enterprises Are Running It Live
For the last two years, “agentic AI” has been the buzzword of every conference keynote and vendor pitch deck. It referred to AI systems capable of taking autonomous action — not just answering prompts, but planning sequences of steps, using tools, and completing multi-part tasks without constant human intervention. The narrative was always future-tense: this is coming, this will change everything.
In 2026, it’s present-tense. 51% of organizations are now running agentic AI systems in production. That’s not a pilot. That’s not a POC. That’s live deployment, in real business processes, affecting real outputs and real customers.
What the ROI Numbers Actually Show
The business case for agentic AI is no longer theoretical. Enterprise deployments are showing an average ROI of 171%, rising to 192% among U.S.-based firms specifically. More striking: 74% of executives are seeing returns within the first year of deployment — a breakeven timeline that’s faster than most traditional software investments, let alone hardware capital expenditure.
McKinsey’s current estimates put agentic AI’s annual value addition potential at $2.6 to $4.4 trillion across industries. Organizations running it at scale are reporting 72% operational efficiency gains and 52% cost reductions in the workflows where it’s deployed. These numbers are real, but they require important context: they represent the upside of successful deployments, not the average across all attempts.
Gartner’s counterpoint is equally important: more than 40% of agentic AI projects are at risk of failure by 2027, primarily due to governance gaps rather than technical failures. The systems work. The organizational infrastructure to manage them often doesn’t.
Real-World Deployments Worth Watching
The most instructive examples of agentic AI at scale come from firms that have moved beyond the experimental phase entirely. JPMorgan Chase is running over 450 production AI agents that handle investment banking presentations (reducing creation time from hours to 30 seconds), M&A memo drafting, trade settlement, and fraud detection — serving more than 200,000 daily users internally.
Walmart has deployed an agentic end-to-end supply chain workflow, enabling autonomous coordination across procurement, inventory, and logistics. TELUS reports saving 40 minutes per customer service interaction through agentic automation. These aren’t edge cases or cherry-picked wins — they’re systematic deployments at companies large enough to have sophisticated measurement and accountability frameworks.
Why Governance Is the Real Bottleneck
The consistent pattern across organizations that struggle with agentic AI is the same: the technical implementation succeeds, but the surrounding governance doesn’t scale. Questions that seemed abstract — who is accountable when an AI agent makes an error? how do you audit a decision chain involving 12 autonomous steps? what happens when two agents give conflicting instructions? — become urgent operational problems in production environments.
The organizations pulling ahead in 2026 are the ones that treated governance design as a prerequisite, not an afterthought. They built human-in-the-loop checkpoints at appropriate risk thresholds, defined clear ownership for AI-driven decisions, and created audit trails before deployment rather than scrambling to retrofit them after. That discipline is, increasingly, the actual competitive differentiator — not which model you chose or how quickly you deployed.
The Hardware Arms Race: Nvidia’s Vera Rubin and the $1 Trillion Forecast

AI’s software story gets most of the attention, but the hardware story is just as consequential — and in some ways, more immediately constraining. The physical infrastructure required to train and run frontier models is growing faster than most organizations’ ability to procure it, and the economics of that scarcity are shaping which companies can move fast and which ones can’t.
Nvidia’s Vera Rubin Platform: What Was Announced and Why It Matters
At GTC 2026 in March, Nvidia unveiled the Vera Rubin AI Platform — the successor to its Blackwell architecture. The platform integrates seven new chips in full production: the Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 SuperNIC, BlueField-4 DPU, Spectrum-6 Ethernet switch, and Groq 3 LPU. The headline performance claim is up to 15x faster token generation and support for models 10 times larger than what current infrastructure can handle.
To put the 15x number in context: it doesn’t just mean AI responses arrive faster. It means that tasks which currently require a purpose-built AI server can eventually run on smaller, more distributed hardware. It means real-time inference at the edge — in vehicles, medical devices, industrial equipment — becomes computationally feasible. The architectural implication is a shift from centralized cloud AI to embedded, always-on AI that doesn’t need a network connection to function.
CEO Jensen Huang projects $1 trillion in AI hardware demand through 2027. That figure, which would have seemed absurd three years ago, now looks conservative to some analysts. The demand-side pressure comes not just from model training — which is already extraordinarily compute-intensive — but from the inference requirements of running those models at scale, 24 hours a day, across millions of simultaneous sessions.
IBM and Quantum: The Hybrid Architecture Play
Nvidia’s GTC announcements included a significant expansion of its collaboration with IBM, integrating Nvidia’s Blackwell Ultra GPUs on IBM Cloud (slated for Q2 2026), and connecting IBM’s watsonx.data platform with GPU-native analytics. More philosophically significant is the growing investment in quantum-classical hybrid architectures.
IBM reached a genuine milestone in 2026: demonstrating quantum computing outperforming classical systems on specific problem types. The caveat — and it matters — is that “specific problem types” doesn’t mean “general purpose.” Quantum computers in 2026 excel at optimization problems, certain simulation tasks, and cryptographic operations. They are not general AI accelerators yet. But the trajectory matters. The combination of GPU compute (for training and inference) with quantum compute (for specific optimization layers) is where the most ambitious researchers are pointing.
Nvidia also launched NemoClaw, a specialized platform for agentic AI workflows, and is forecasting that the next wave of hardware demand comes specifically from the inference side — not training. This distinction is important for businesses: the cost of building a model is a one-time capital expenditure for the labs, but the cost of running a model at scale is an ongoing operational expense for everyone deploying it. Inference efficiency, not training speed, is increasingly where competitive advantage lives.
The Energy Problem Nobody Wants to Talk About
AI data centers now consume power at a scale that is measurably straining regional grids in parts of the United States, Europe, and Asia. Nvidia’s platform announcements at GTC 2026 included explicit references to energy efficiency and what the company calls “AI factory” DSX designs that optimize for power consumption per unit of compute. This isn’t altruistic — it’s driven by the practical reality that data centers in 2026 are bumping up against power availability limits that no amount of capital spending can immediately solve.
For businesses evaluating AI infrastructure decisions, energy cost is becoming a first-order consideration. The economics of on-premise AI hardware versus cloud compute are shifting as power costs factor in, and geography increasingly matters — data centers in areas with cheap renewable energy are becoming valuable not just for their connectivity but for their kilowatt pricing.
The Jobs Math That Nobody Wants to Do

The AI-and-jobs conversation has spent years trapped in a binary debate: either “AI will take all the jobs” or “AI creates more jobs than it destroys, don’t worry.” Both framings are too blunt. The actual data in 2026 is more granular and more uncomfortable than either camp wants to admit.
The Current Net Numbers
According to Goldman Sachs analysis of current U.S. labor market data, AI is displacing approximately 25,000 jobs per month through direct substitution — tasks previously done by humans that are now automated entirely. Against that, AI augmentation (AI tools that enhance worker output, enabling firms to do more with the same headcount rather than hiring) is creating or preserving roughly 9,000 jobs per month. The net: -16,000 jobs per month in the U.S. alone.
Across the first half of 2025, 77,999 tech sector jobs were cut with AI cited as a contributing factor. That number has accelerated into 2026. The sectors most affected are administrative roles, entry-level data work, customer service, and certain categories of white-collar professional work — legal document review, financial analysis, routine coding, content moderation.
Who’s Getting Hit Hardest — and Why It Matters
The demographic pattern of displacement is specific and worth naming: Gen Z workers and entry-level employees in tech, administrative, and professional services roles are bearing a disproportionate share of the impact. This isn’t an accident. AI systems are particularly good at the types of structured, well-defined tasks that entry-level jobs have historically consisted of — the exact work that earlier generations used as the on-ramp to building careers in their fields.
The long-term implication is serious and under-discussed. When entry-level roles disappear, the traditional path from junior employee to senior practitioner becomes structurally more difficult to navigate. The question of how people develop genuine expertise in fields where the routine work is now automated is one that organizations and educational institutions haven’t yet answered satisfactorily.
The IMF estimates that 40-60% of jobs globally face significant AI exposure — higher in advanced economies where knowledge work predominates. Goldman Sachs’s longer-range estimate suggests AI could automate tasks equivalent to 300 million full-time jobs worldwide, though the crucial distinction is “tasks equivalent” rather than “jobs eliminated.” Most jobs involve a mix of automatable and non-automatable tasks; the realistic near-term scenario is role transformation rather than mass disappearance.
The Jobs Being Created — and the Gap Between Them
World Economic Forum projections indicate that by 2027, 83 to 92 million roles will be displaced globally while 69 to 170 million new ones will be created. The wide range on the creation side reflects genuine uncertainty about which new roles emerge and how quickly. The net is projected to be positive — more jobs created than lost — but the transition period creates what economists call a skills mismatch problem at enormous scale.
New AI-adjacent roles — AI trainers, prompt engineers, machine learning operations specialists, AI governance officers, model auditors — require skills that existing displaced workers often don’t have and that formal education systems are only beginning to build programs around. Retraining at the scale required is a multi-year, multi-trillion-dollar undertaking that neither governments nor employers are currently funding at the necessary level.
For workers navigating this: the roles showing greatest durability against AI displacement share a common thread — they require sustained human judgment in ambiguous, high-stakes, emotionally complex situations. Care work, crisis management, complex negotiation, creative direction, hands-on technical trades. None of these are immune, but all of them involve dimensions of human interaction that AI systems in 2026 can assist with, not replace.
Physical AI and Robotics: From Warehouses to Operating Rooms

Most public AI discourse focuses on software — chatbots, language models, generative tools. But one of the most consequential shifts happening in 2026 is the acceleration of physical AI: systems that don’t just process language and generate text, but perceive, reason about, and act in the three-dimensional physical world.
What “Physical AI” Actually Means
The technical term is vision-language-action (VLA) models. Unlike traditional industrial robots that follow pre-programmed sequences, VLA-powered robots combine computer vision (seeing and interpreting their environment), natural language processing (receiving and understanding instructions), and motor control (translating plans into physical action) through a unified model rather than separate, brittle subsystems.
The practical difference this makes is significant. A traditional warehouse robot trained to pick up red cylindrical objects fails when the objects are arranged differently than expected, or when the lighting changes, or when a new product variant is introduced. A VLA-powered system adapts — it understands what it’s looking at in context, reasons about how to approach the task, and adjusts its actions accordingly. This is why physical AI is advancing rapidly in environments that were previously too unpredictable for robotic automation.
Industry-Specific Deployment in 2026
The manufacturing sector is seeing the widest physical AI deployment. Smart robotic systems equipped with combined touch and vision sensors are now performing precision assembly, welding, and painting while responding dynamically to design changes — without requiring extensive reprogramming. Siemens unveiled a Digital Twin Composer at CES 2026 that uses AI agents to simulate entire supply chain processes before physical deployment, dramatically reducing the cost and time of factory reconfiguration.
In healthcare, surgical robotics with multi-agent coordination are beginning early-stage clinical deployment. These systems don’t operate autonomously — they work alongside surgeons — but they bring AI precision to minimally invasive procedures, compensating for hand tremor, providing real-time tissue analysis, and flagging anomalies that human visual perception might miss during long procedures. The liability and regulatory questions around surgical AI remain complex, but the clinical data from 2025-2026 pilots is positive enough that broader rollout appears likely within the next 18 to 24 months.
Logistics and supply chain applications are the most commercially mature. Walmart’s agentic supply chain workflow, mentioned earlier, includes physical components — automated sorting and inventory systems coordinated by AI that adjusts priorities in real time based on demand signals, weather, and supplier data. The global physical AI and robotics market is projected at €430 billion by 2030, with automotive (€171 billion) and industrial automation (€69 billion) representing the largest segments.
The Surprising Use Cases
Beyond the well-publicized warehouse and factory applications, some of the most interesting physical AI deployments in 2026 are in places you wouldn’t expect. Cash-in-transit fleet management systems are using real-time sensor data and AI route optimization to identify the safest and most efficient paths for armored vehicle fleets. Agricultural AI systems using tactile sensors can assess produce ripeness beyond what visual inspection captures — determining softness, density, and moisture content through touch sensors that outperform human graders in consistency. In construction, AI-guided inspection drones are using LiDAR and computer vision to flag structural anomalies in large infrastructure projects faster and more completely than human inspection teams.
Chinese robotics company AGIBOT made a significant announcement in April 2026, unveiling eight foundational robotic models under a “One Robotic Body, Three Intelligences” architecture — separating locomotion intelligence, manipulation intelligence, and interaction intelligence into distinct but coordinated model layers. Their BFM model enables instant task imitation from video demonstration — a robot watches a human perform a task once and can replicate it. The competitive implications for global robotics manufacturing are considerable.
The Regulatory Divergence: The US Deregulates While the EU Accelerates

If you want to understand the geopolitical dimension of AI in 2026, the most important thing to track isn’t model benchmarks or chip announcements. It’s the regulatory divergence between the world’s two largest AI markets — and what it means for every organization operating across both.
The European Union: Full Enforcement on the Horizon
The EU AI Act reaches full applicability on August 2, 2026 — the date when the majority of its provisions, including obligations for high-risk AI systems, come into force. The framework uses a risk-tiered approach: outright bans on “unacceptable-risk” AI systems (like real-time public biometric surveillance and social scoring systems) took effect in February 2025, while the GPAI transparency rules for general-purpose AI models have been applying since August 2025.
However, 2026 has brought significant uncertainty to the enforcement timeline. The European Commission has proposed a one-year delay for many high-risk AI system obligations, potentially pushing full compliance from August 2026 to mid-2027. This proposal is part of a broader Digital Omnibus regulation that also includes efforts to streamline cybersecurity requirements and relax personal data use restrictions for AI training — the latter representing a notable softening of positions that the Commission held firmly just 18 months ago.
For businesses, the practical implication is ongoing compliance uncertainty. The EU AI Act’s requirements — risk assessments, technical documentation, human oversight mechanisms, transparency disclosures — represent significant operational overhead, particularly for organizations that classify their AI systems as high-risk. The one-year delay proposal provides breathing room, but it also creates a planning environment where the goalposts have moved enough times that some organizations have adopted a “build for compliance and wait” posture rather than committing fully to either timeline.
The United States: Federal Deregulation, State-Level Fragmentation
The U.S. approach in 2026 represents a near-inversion of the EU’s framework. Following Trump’s December 2025 executive order centralizing federal authority over AI policy and blocking state laws that conflict with federal deregulation goals, the administration released a National Policy Framework for AI on March 20, 2026. The framework is non-binding legislative guidance that prioritizes child safety, free speech protection, innovation acceleration, workforce readiness, and — critically — federal preemption of state AI laws.
The carveouts in the preemption framework are telling: state laws related to child safety, AI infrastructure, and state procurement are explicitly exempted. This means states retain authority in areas with the most visible political salience, while being blocked from broader AI consumer protection legislation. Colorado’s February 2026 enforcement of its state AI law — the first state-level enforcement action of its kind in the U.S. — has already been flagged as potentially conflicting with the federal framework, setting up a legal challenge that will have significant precedent implications.
The CHATBOT Act, a bipartisan Senate bill led by Senators Ted Cruz and Brian Schatz, would require family accounts and parental consent for minors to use AI chatbots — one of the few areas where significant cross-partisan consensus exists in AI policy. It’s a narrow bill addressing a specific harm, but its bipartisan support suggests it has a more realistic path to passage than broader AI legislation.
What This Divergence Means in Practice
For multinational organizations, the EU-US regulatory divergence creates a genuine compliance challenge. Systems that are fully permissible under the U.S. federal framework may require significant modification to meet EU AI Act standards — different transparency disclosures, different audit documentation, different human oversight mechanisms. The risk-based classification that the EU uses doesn’t map cleanly onto American risk assessment frameworks, which means compliance teams are essentially maintaining two parallel frameworks.
The strategic response for most large organizations has been to build to the higher standard — designing AI systems that would satisfy EU AI Act requirements even in markets where those requirements don’t legally apply. The logic is that compliance retrofitting after deployment is more expensive than building it in from the start, and that regulatory convergence over a 3-5 year horizon is more likely than permanent divergence. Whether that logic proves correct depends largely on the political stability of both regulatory environments — which, in 2026, is not guaranteed in either direction.
The Musk vs. Altman Trial — What’s Really at Stake for the AI Industry
On April 27, 2026, a federal courthouse in Oakland, California became the setting for what may be the most consequential legal proceeding in AI industry history — not because of its immediate financial stakes, but because of the structural questions it forces into the public record.
The Core Allegations
Elon Musk, who co-founded OpenAI in 2015 and donated approximately $38 million to the organization between 2015 and 2017 before departing in 2018, is suing OpenAI CEO Sam Altman, President Greg Brockman, and Microsoft over what he characterizes as a betrayal of OpenAI’s founding charitable mission. The specific allegation is that Altman and Brockman engineered the conversion of OpenAI from a nonprofit research organization into a for-profit enterprise, enriching themselves personally while abandoning the commitment to develop AI for humanity’s benefit rather than shareholder value.
The legal stakes are significant. Musk is seeking over $150 billion in damages, along with the removal of Altman and Brockman from their positions. He is also seeking a reversal of OpenAI’s 2019 restructuring and its October 2025 recapitalization into a public benefit corporation — a move that left the nonprofit with a 26% stake in the for-profit entity.
Why This Trial Matters Beyond the Two Principals
Strip away the personalities — and in this case, the personalities are genuinely distracting — and the Musk v. Altman trial poses a foundational question that the AI industry has collectively avoided confronting: can an organization credibly maintain a public-benefit mission while operating as a commercial enterprise competing for capital in one of the most investment-intensive technology sectors in history?
OpenAI has raised billions of dollars from investors including Microsoft and SoftBank. It has a valuation exceeding $300 billion. It is building products that generate commercial revenue and are designed to be competitive in the marketplace. The nonprofit governance structure that Musk argues was central to the founding commitment exists today as a minority stakeholder in a commercial corporation, with a board that has already demonstrated, in its brief November 2023 drama, just how much governance tension exists between the two missions.
The Wall Street Journal reported in April 2026 that OpenAI missed internal targets for reaching one billion weekly active ChatGPT users by year-end 2025, and that CFO Sarah Friar has expressed concerns about IPO plans and data center spending under Altman. These internal tensions compound the external legal ones and raise legitimate questions about whether OpenAI’s commercial execution can match the ambition of its stated research mission.
Regardless of how the trial resolves legally, it is forcing a level of scrutiny on the relationship between AI’s stated idealistic goals and its actual commercial incentives that the industry would otherwise have been happy to sidestep indefinitely.
The Broader Governance Question
The trial has also elevated attention on AI governance structures more broadly. Several other major AI research organizations — including Anthropic and DeepMind, both of which have structural commitments to safety and benefit — are watching the proceedings carefully. If the court finds that nonprofit structures create legally enforceable obligations that limit commercial restructuring, it could constrain how these organizations evolve. If it finds the opposite, it may accelerate the commercial consolidation of AI development with fewer structural safety guardrails.
One Google DeepMind researcher recently published a paper titled “The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness” — arguing that phenomenal consciousness is a physical state, not a software artifact. After the paper was reported on by media, DeepMind removed its letterhead from the document, adding a disclaimer that it represented the author’s personal views. That small, quietly awkward episode is itself illustrative of the governance pressures facing AI labs in 2026: researchers pushing into philosophical territory that makes institutions nervous, and institutions scrambling to maintain plausible deniability on the most sensitive questions.
The Consciousness Question Gets Serious — DeepMind Hires a Philosopher
In mid-April 2026, Google DeepMind hired philosopher Henry Shevlin — an Oxford-educated cognitive scientist — to research machine consciousness, human-AI relationships, and AGI readiness. On its own, a single hiring decision wouldn’t merit much attention. In context, it’s significant.
Why AI Labs Are Taking Consciousness Seriously Now
The short answer is that the systems have become complex enough that the question is no longer purely academic. When Anthropic estimates a 0.15% to 15% probability of consciousness in models like Claude — a range so wide it reflects genuine uncertainty rather than confident dismissal — and when researchers at the same organization are developing frameworks for what they call “model welfare,” the philosophical territory has become practically relevant.
To be clear: no credible researcher believes that current AI systems are conscious in the way humans are. The 2023 Butlin et al. report — the most cited academic treatment of the question — concluded that no current AI systems meet the criteria for consciousness under any major theoretical framework. But it also concluded that there are no technical barriers to conscious AI in principle — the question is architectural and philosophical, not a fundamental limit of computation.
DeepMind’s March 2026 release of “Measuring Progress Toward AGI: A Cognitive Taxonomy” outlined ten distinct cognitive abilities — including perception, reasoning, metacognition, and social cognition — as a framework for evaluating progress toward general intelligence. The framework is deliberately agnostic on consciousness; it measures functional capabilities rather than subjective experience. But the act of building systematic measurement frameworks for AGI progress signals that DeepMind is treating the arrival of more-than-human AI capability as a planning horizon, not a philosophical abstraction.
The Practical Stakes of Getting This Wrong
If you’re inclined to dismiss consciousness research as interesting-but-irrelevant to real-world AI decision-making, consider the governance implications of two different error types:
If AI systems have morally relevant inner states and we treat them as pure tools, we may be creating the conditions for harms we’re not currently accounting for — and we’re certainly not building the safeguards that responsible treatment would require. If AI systems have no inner states whatsoever and we act as though they might, we introduce unnecessary constraints on development and deployment, and potentially create legal frameworks that protect non-existent interests.
Neither error is obviously more costly than the other, which is exactly why serious institutions are now investing in the research infrastructure to narrow the uncertainty. The hiring of Henry Shevlin at DeepMind, the welfare research at Anthropic, and the proliferating academic programs in AI ethics and consciousness are not signs that we’re approaching answers — they’re signs that the questions have become urgent enough that waiting for answers is no longer an option.
What AI Leaders Got Wrong in Early 2026 — and What They’re Correcting
It would be incomplete to survey 2026’s AI landscape without acknowledging the failures and course corrections underway. Not every trend line points up. Several assumptions that drove significant investment decisions in 2024-2025 have not survived contact with reality.
The Agent Reliability Problem
Agentic AI systems, as noted earlier, are now in production at 51% of enterprises — but the Gartner finding that 40%+ of projects are at failure risk isn’t just about governance. It also reflects a genuine technical limitation: agents fail in unpredictable ways that are different in character from the errors that simpler AI systems make.
When a language model hallucinates a fact, it’s a contained error — bad output in a single response. When an agentic system takes a wrong turn in step 3 of a 15-step autonomous workflow, the error compounds across subsequent steps, and by the time a human reviews the output, the downstream consequences can be significant. The “self-healing memory” feature that Anthropic built into Claude Opus 4.x is a direct response to this problem — an attempt to give the model the ability to recognize its own errors mid-workflow rather than requiring external human correction.
The Context Window Trap
The race to extend context windows — from 8K tokens to 128K to 1 million to 2 million — has produced some counterintuitive results. Models with very long context windows don’t automatically perform better on long-context tasks. Research published in early 2026 has confirmed what practitioners had been noticing empirically: performance on tasks in the middle of a very long context window degrades significantly compared to tasks at the beginning or end. This “lost in the middle” problem means that simply having a 2M token context window doesn’t guarantee useful retrieval from a 2M token document.
The practical response has been a renewed focus on context engineering — the discipline of structuring what information gets passed to a model, in what order, and with what formatting cues — as distinct from and more important than raw context length. IBM’s Granite model series and other domain-specific models have been optimized for context engineering at the enterprise level, which often outperforms throwing everything at a frontier model with a massive context window.
The Efficiency Turn
Perhaps the most important shift in 2026 AI development is a turn away from “bigger is better” as the dominant scaling philosophy. GPT-5 Nano, Microsoft’s Phi-4 small model series, and Anthropic’s efforts to maintain Claude’s reasoning capability while reducing inference cost all reflect the same underlying observation: the marginal capability gain from continued scaling of existing architectures is declining, while the cost of that scaling continues to increase.
Domain-specific models trained on high-quality, task-specific data are now regularly outperforming general frontier models on the tasks they were built for — often at a fraction of the compute cost. IBM’s Granite models in legal and financial domains are a prominent example. This is good news for businesses that have been priced out of frontier model API costs, and it suggests that the competitive moat of the large labs may be narrower than their valuations imply.
The Five Things Paying Attention to AI Right Now Actually Requires
After cataloging what’s happening, it’s worth being direct about what it demands from anyone trying to navigate this landscape intelligently — whether you’re running an organization, building a career, making policy, or simply trying to stay informed.
1. Stop Following Benchmarks as a Proxy for Capability
Benchmark scores — the “94.6% on coding tasks” and “97.8% on reasoning” numbers — measure specific, narrow, pre-defined tasks. Real-world performance depends on the specific task, the quality of the prompt, the supporting infrastructure, and the governance around the deployment. Two organizations using the same model can get radically different results. Stop asking “which model is best?” and start asking “which model is best for this specific task in this specific context?”
2. Treat Governance as a Capability, Not a Constraint
Every piece of evidence from 2026 enterprise deployments points to the same conclusion: governance is the differentiator between AI projects that deliver value and AI projects that fail or cause harm. This means audit trails, accountability frameworks, human oversight at appropriate thresholds, and clear escalation paths. It means treating AI outputs as institutional decisions, not oracle pronouncements. Organizations that build governance capability first deploy faster and recover from errors faster.
3. Watch the Physical World, Not Just the Software Stack
The most undercovered AI story of 2026 is physical AI. Language models get the headlines; robots get the changed economies. Supply chains, manufacturing, agriculture, healthcare — the sectors that physical AI is beginning to reshape are fundamental in ways that LLM improvements simply aren’t. If your industry involves physical production, physical logistics, or hands-on services, physical AI should be on your radar now, not in five years.
4. The Regulatory Gap Is Your Problem to Manage
Neither the EU nor the US regulatory framework is stable, complete, or coherent. If you’re operating across jurisdictions, building to the highest available standard and documenting your compliance rationale is the only defensible strategy. The cost of regulatory uncertainty falls on whoever hasn’t prepared for it — and in 2026, preparation means proactive engagement, not waiting for final rules.
5. The Human Side Isn’t a Side Issue
Every data point about AI’s workforce impact reflects real consequences for real people. Sixteen thousand net jobs lost per month isn’t an abstraction. The organizations that are navigating this responsibly — providing genuine retraining, being transparent about automation roadmaps with affected employees, thinking seriously about the entry-level pipeline they’re eliminating — are making choices that have moral weight, not just operational implications. AI capability decisions are workforce policy decisions. Treating them as purely technical limits what you’re able to see clearly about their consequences.
Conclusion: Past the Hype Cycle, Into the Accountability Era
The Gartner Hype Cycle model suggests that emerging technologies follow a predictable path: a peak of inflated expectations, a trough of disillusionment, and eventually a slope of enlightenment toward a plateau of productivity. AI, in 2026, is somewhere between the trough and the slope — past the most extravagant claims of its early advocates, not yet fully delivering on the sustainable value its commercial deployments are promising, but generating enough real-world evidence that the productivity plateau is genuinely visible from here.
What makes this moment different from earlier technology transitions is the breadth and speed of AI’s reach. The internet took a decade to reshape commerce at scale. Mobile took five years to restructure media and communication. AI is reshaping knowledge work, physical labor, scientific research, legal structures, and political economies simultaneously, with each of those domains accelerating the others in feedback loops that are difficult to predict and harder to manage.
The models are getting better faster than most institutions are adapting. The hardware is scaling faster than the governance frameworks designed to manage it. The commercial incentives are moving faster than the regulatory structures meant to channel them. And the philosophical questions — about consciousness, about accountability, about what we owe each other in a world where AI can increasingly do what humans have always done — are arriving at institutional doorsteps before most institutions have developed any vocabulary for engaging with them.
None of that is cause for panic. It is cause for seriousness. The AI story of 2026 is not primarily a technology story. It is a story about what kind of institutions, what kind of governance, and what kind of human choices will shape the technology that is already, irreversibly, shaping us back.
Pay attention. The headlines will keep coming. The underlying dynamics described here will matter longer.