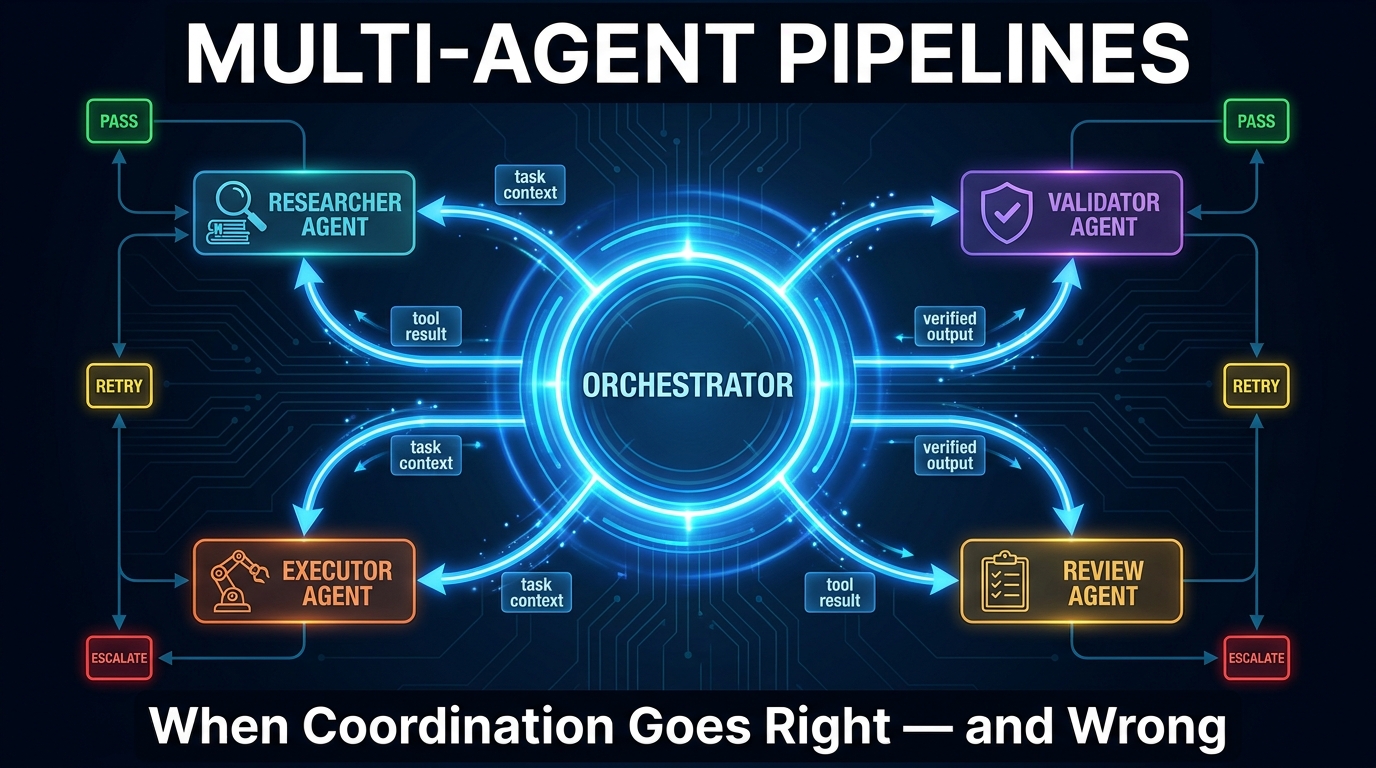
There is a moment every team hits, usually around their third or fourth agent in production, when the system stops behaving like software and starts behaving like a group of colleagues who haven’t been properly briefed. An agent hands off a half-baked result. Another agent accepts it without checking. A third goes quietly off-script. By the time anyone notices, the pipeline has produced something technically complete and factually wrong — and nobody can explain how.
This is the coordination tax. It doesn’t show up in demos. It doesn’t appear in benchmark scores. It surfaces in production, at scale, after you’ve already committed to the architecture.
The shift to multi-agent systems was supposed to solve problems that single agents couldn’t: parallelism, specialization, long-horizon task decomposition. And it does solve those things — when the orchestration layer is designed as carefully as the agents themselves. The trouble is that most teams spend 90% of their effort on the agents and about 10% on what happens between them.
This post is about that 10%. It covers the topology choices that determine how failure propagates, the state management patterns that make pipelines recoverable, the protocol stack that is rapidly becoming the enterprise standard for agent coordination, the six failure modes that quietly destroy multi-agent pipelines in production, and the observability and security work that most teams skip until something breaks badly enough to force them back to first principles.
If you’ve already deployed agentic workflows and found the complexity growing faster than the value, this is the engineering perspective you were missing at the start.
What “Post-Agentic” Actually Means — and Why the Terminology Matters
The phrase “post-agentic orchestration” is doing real conceptual work, not just following a naming trend. It marks a specific inflection point in how teams think about AI systems.
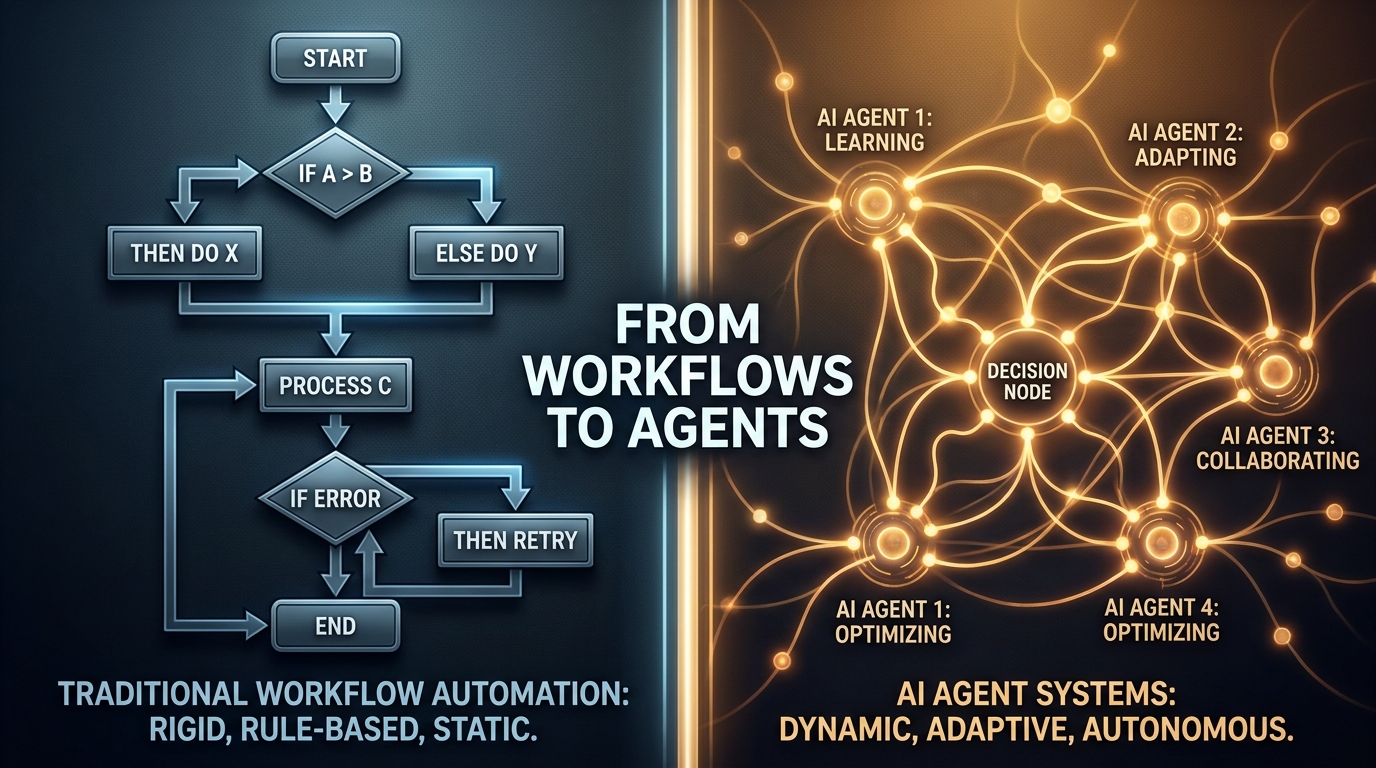
The first wave of agentic AI — roughly 2023 to mid-2025 — was characterized by what might charitably be called optimistic autonomy. Teams built agents and let them route their own decisions. The LLM chose the next tool. The LLM chose when to stop. The LLM decided which result was good enough to pass downstream. Frameworks like early LangChain made this easy to set up and very hard to reason about in production.
Post-agentic orchestration rejects that premise. It treats agents as specialized components inside a larger, explicitly governed workflow — not as autonomous actors that happen to share a pipeline. The LLM is still doing the hard cognitive work, but the control flow, the handoff logic, and the state transitions are defined in code, not inferred at runtime by a model.
The Distinction That Actually Changes Your Architecture
Anthropic’s engineering team captured this distinction cleanly in their work on building effective agents: workflows are systems where LLMs and tools are orchestrated through predefined code paths, while agents are systems where LLMs dynamically direct their own processes. Both are valid. The question is which one you need for a given task — and most teams reach for the autonomous agent when a well-structured workflow would be more reliable, cheaper to run, and easier to debug.
Post-agentic orchestration is the recognition that in most enterprise contexts, you want agents to be excellent at their specific tasks while the orchestrator — not the agent — decides what happens next. This isn’t a step backward from agentic AI. It’s what agentic AI looks like when it grows up.
Why the Terminology Matters Beyond Semantics
When you call something an “agent,” there’s an implicit expectation of autonomy and self-direction. When you frame it as a “component in an orchestrated pipeline,” the design questions change immediately: What inputs does this component require? What outputs does it guarantee? How does it signal failure? What authority does it have to make side effects?
These are not LLM questions. They are distributed systems questions — and that’s exactly the lens that 2026’s most reliable multi-agent pipelines are being built with. Production teams in 2026 are increasingly treating multi-agent pipelines less like prompt chains and more like distributed microservice architectures, applying the same engineering rigor around contracts, state, retries, and observability.
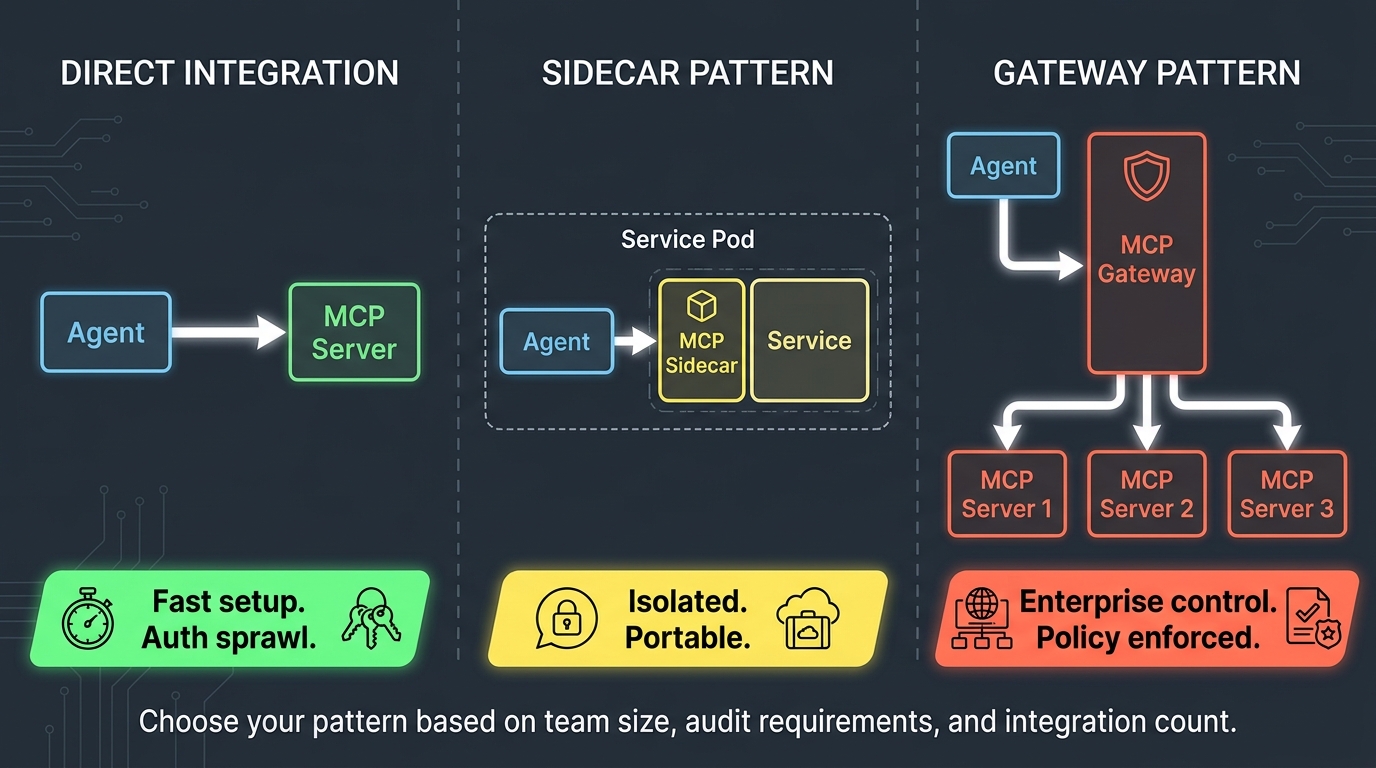
The Four Topology Choices — and When Each One Breaks
Before you write a single line of orchestration code, the most consequential decision you’ll make is your topology. How agents are connected determines how errors propagate, how context flows, how parallelism works, and ultimately how much you can recover when something goes wrong.
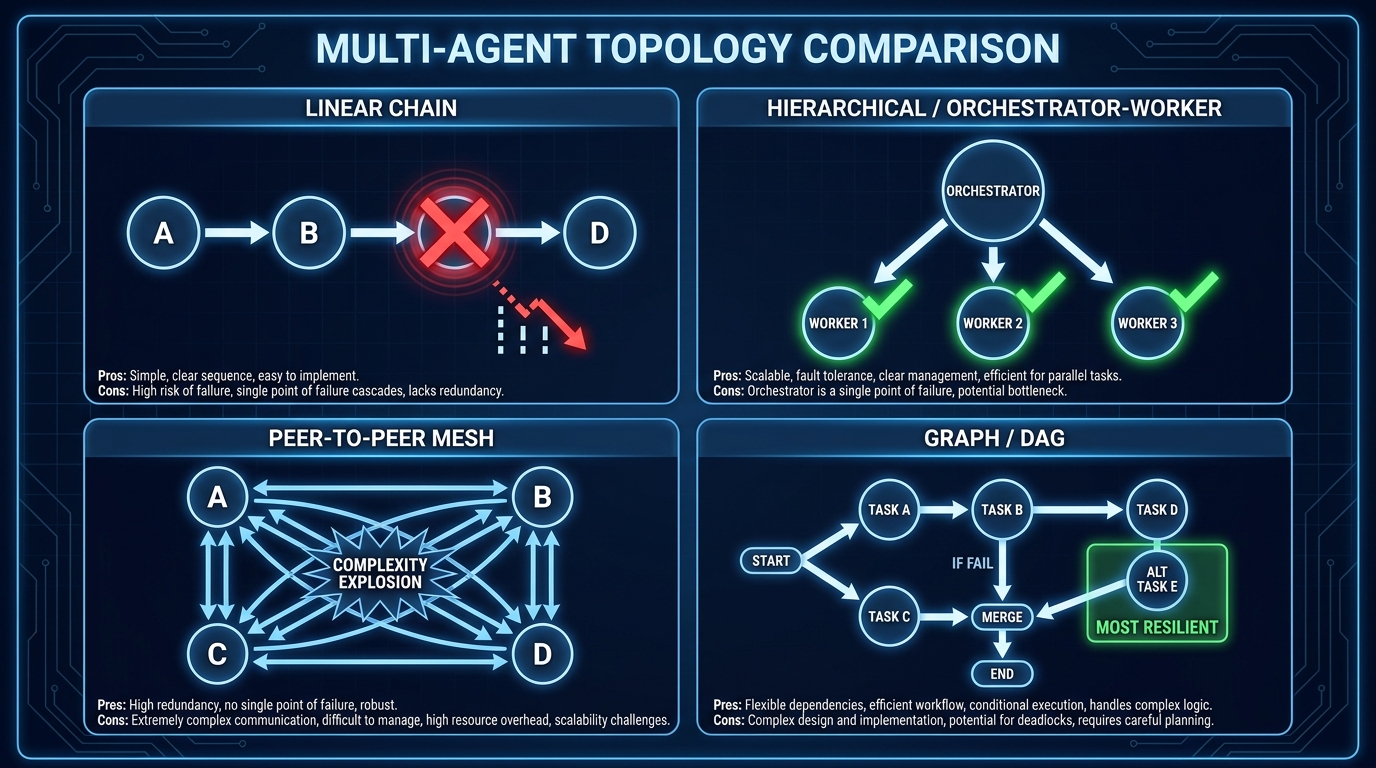
There are four dominant topologies in production multi-agent systems, and each has a specific failure profile that’s worth understanding before you commit.
Linear Chains: Simple to Build, Brittle to Operate
A linear chain is the default topology most teams reach for first. Agent A passes output to Agent B, which passes to Agent C, and so on. It’s intuitive, easy to reason about, and maps cleanly to sequential tasks like “research, then draft, then review.”
The problem is error propagation. In a linear chain, a degraded output from Agent B doesn’t just produce a worse result at step C — it actively misdirects Agent C, which may then produce a confident but incorrect output that propagates to D. Research from fault-injection studies on MetaGPT-style linear architectures shows near-total cascade collapse under certain failure modes, because there is no mechanism to intercept an error mid-chain without discarding all downstream work.
Linear chains are appropriate for tasks that decompose cleanly into sequential steps where each step is deterministic and the output of each step is easy to validate programmatically. When steps involve LLM judgment calls, you need gates — explicit programmatic checks that validate intermediate outputs before passing them downstream. Without gates, a linear chain is a cascade-failure machine waiting to be triggered.
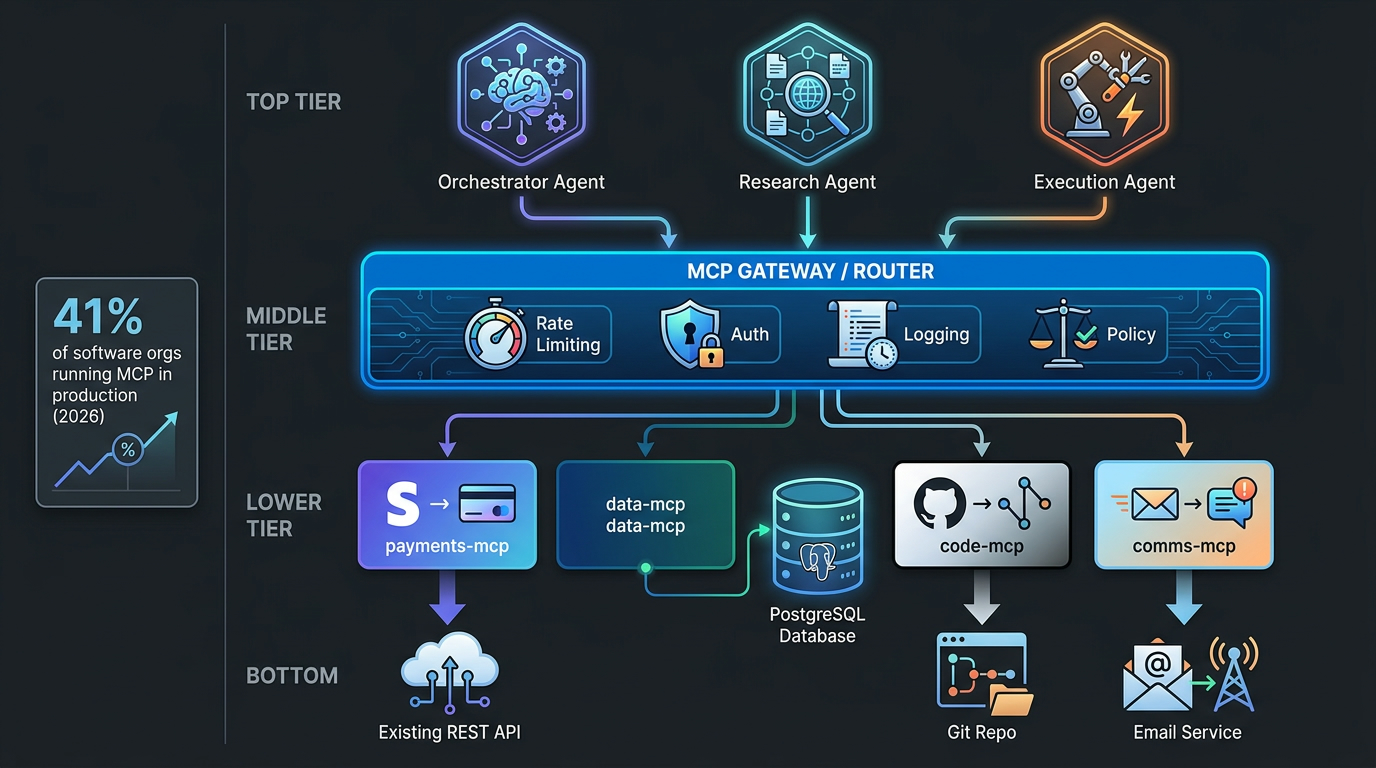
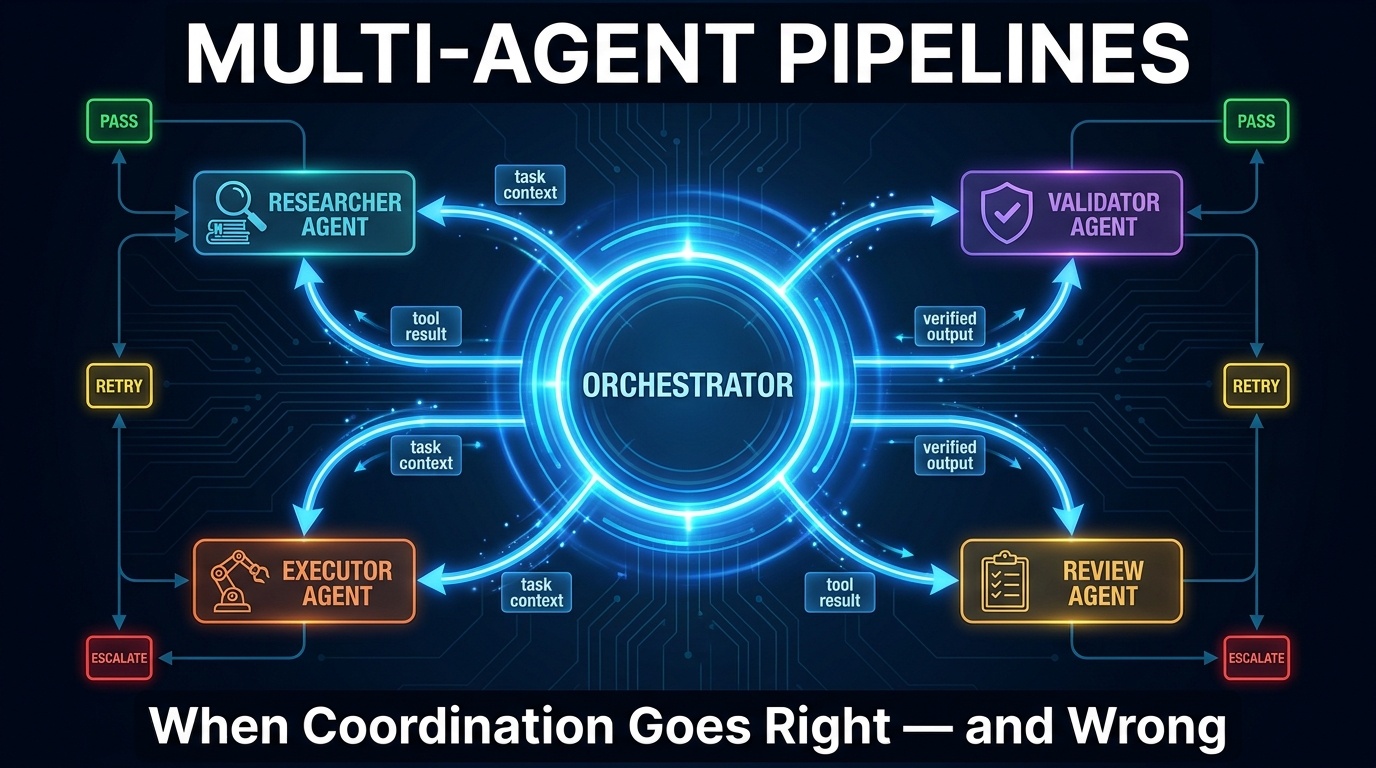
Hierarchical Orchestrator-Worker: The Production Workhorse
The hierarchical pattern puts a dedicated orchestrator agent at the top of the stack. The orchestrator plans, routes, and assembles — but doesn’t execute domain tasks. Worker agents below it handle specialized execution: a research agent, a calculation agent, a writing agent, a validation agent. Results flow back up to the orchestrator, which decides what to do next.
This topology is the most widely adopted in enterprise production deployments in 2026 for a simple reason: it localizes failure. When the research agent fails, the orchestrator knows it, can retry with a different strategy, and the writing agent never sees a degraded input it wasn’t designed to handle.
The orchestrator-worker pattern’s weakness is the orchestrator itself becoming a bottleneck — both in terms of latency (everything passes through it) and in terms of cognitive load (the orchestrator’s context window fills with accumulated task state across long workflows). Teams address this with sub-orchestrators: smaller orchestrators that manage subsections of the workflow and report aggregated results upward, creating a two-level or three-level hierarchy.
Peer-to-Peer Mesh: Theoretically Flexible, Practically Dangerous
In a mesh topology, agents can communicate directly with each other without routing through a central orchestrator. An agent can request help from any peer, delegate subtasks laterally, and receive results from multiple sources simultaneously.
The appeal is flexibility and low latency for certain coordination patterns. The reality in production is complexity explosion. Debugging a failure in a mesh is extremely difficult because you lose the single path of execution that you could trace. Circular delegation — where Agent A asks Agent B, which asks Agent C, which asks Agent A — becomes possible and is surprisingly hard to prevent without explicit cycle detection. Trust boundaries become ambiguous because any agent can communicate with any other.
Mesh topologies remain mostly in research contexts or in tightly scoped, well-instrumented production deployments. Most teams who start with mesh architecture migrate toward hierarchical or graph-based designs after their first significant production incident.
Graph (DAG) Topologies: The Most Resilient, the Hardest to Design
Directed Acyclic Graph (DAG) topologies model the workflow as an explicit graph of nodes and edges, where each node is an agent or tool invocation and each edge represents a data dependency or control flow transition. Branches, merges, conditional routing, and parallel execution are all native to the model.
Iterative, closed-loop designs built on DAG principles neutralize over 40% of faults that cause catastrophic collapse in linear workflows, according to recent fault-injection research. The reason is structural: a DAG forces you to design explicit merge points, where outputs from parallel branches are combined and validated before proceeding, and explicit conditional branches, where the next node is chosen based on structured evaluation of the previous result.
The cost is design complexity upfront. Building a good DAG requires you to model your workflow as a proper state machine before you build it — which is uncomfortable for teams that want to iterate rapidly. The payoff at scale is substantial. Frameworks like LangGraph have emerged specifically to make DAG-based multi-agent pipelines manageable, offering graph-based workflow definition with built-in checkpointing and state management.
State Management: The Hidden Load-Bearing Wall
If topology determines how failure propagates, state management determines whether you can recover from it. And in most multi-agent systems built in 2024 and early 2025, state was an afterthought — which is why so many of those systems are being rewritten in 2026.
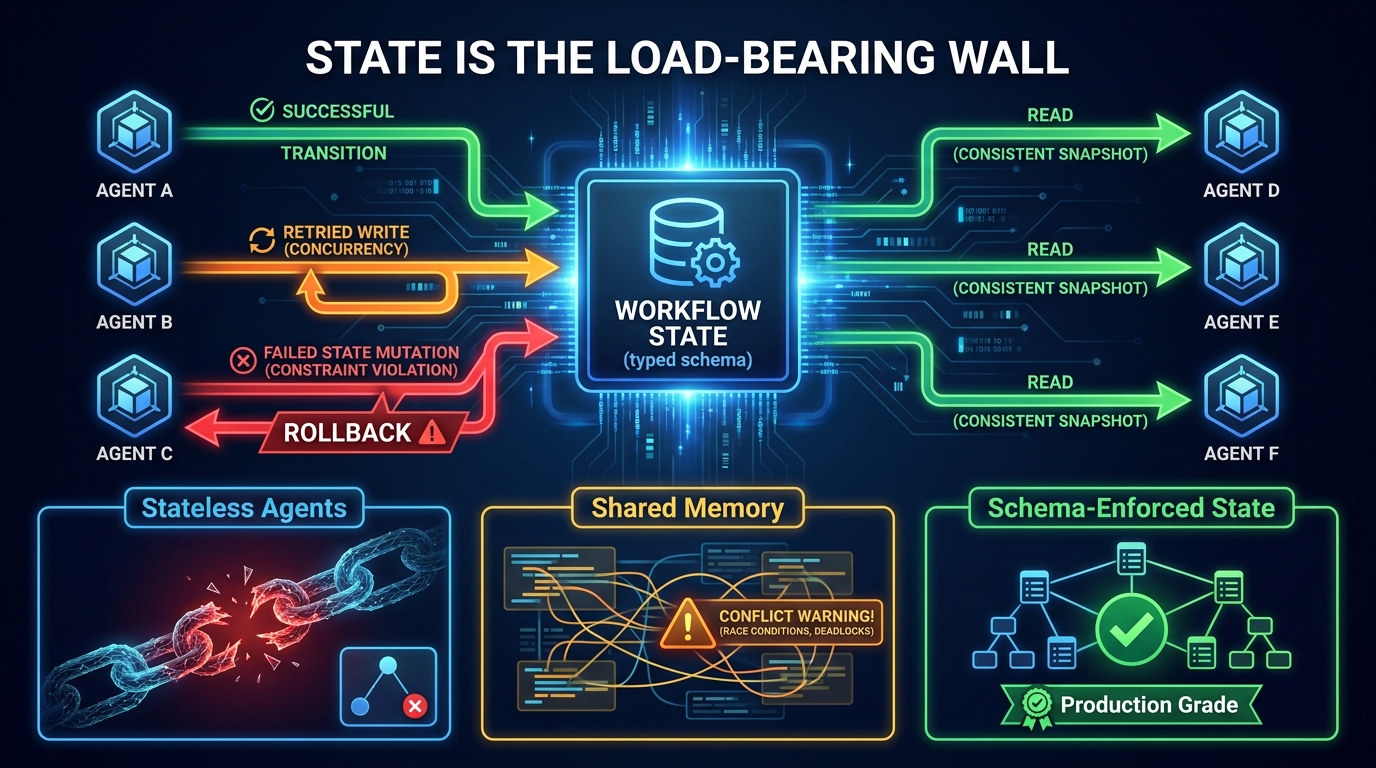
State in a multi-agent pipeline has three distinct layers, and conflating them is one of the most common architectural mistakes teams make.
Layer 1: Conversational Context
This is the in-context memory each agent carries — the accumulated messages, tool results, and instructions that fit within its context window. Conversational context is ephemeral: it dies when the agent call ends, and it doesn’t survive restarts, retries, or handoffs unless you explicitly pass it forward.
Many teams treat conversational context as if it were workflow state, passing the full conversation history as a handoff payload from agent to agent. This creates two problems. First, context windows fill up — a five-hop agent pipeline passing full history at each step is burning tokens on information most downstream agents don’t need. Second, the receiving agent has no structured way to identify which parts of the history are relevant to its task.
The production pattern is to summarize or extract structured outputs at each hop, passing only the typed data the next agent actually requires, not the full conversational trace. This requires more upfront schema design but dramatically improves reliability and cost efficiency.
Layer 2: Workflow State
Workflow state is the persistent, typed record of what has happened in the pipeline so far — completed steps, intermediate results, branching decisions, and retry counts. This is the layer that makes recovery possible.
The non-negotiable property of production workflow state is durability. If a worker agent crashes mid-execution, the orchestrator needs to know what was completed, what was not, and what inputs the failed step received — so it can retry without re-running everything from scratch. Without durable workflow state, any failure resets the entire pipeline.
The 2026 production standard is schema-enforced shared state with explicit write semantics. Every state mutation is typed, validated, and logged. Agents don’t write arbitrary key-value data to a shared store — they emit structured state transitions that the orchestrator validates before they’re committed. This is the same pattern used in event sourcing and CQRS architectures, and it maps directly onto multi-agent pipelines because the fundamental problem — distributed components modifying shared state — is identical.
Layer 3: External Side Effects
Side effects — database writes, API calls, emails sent, files written — are the most dangerous category of state because they cannot be easily rolled back. A multi-agent pipeline that makes an external write halfway through and then fails faces a partial commitment problem that’s familiar to anyone who has debugged a distributed transaction.
The pattern that works is treating all external side effects as idempotent operations with explicit rollback plans. Every tool call that touches external state should have an idempotency key, a confirmation step before execution, and a logged record of what was written. Agents should not be given open-ended write access to external systems — they should have scoped, validated, reversible write capabilities that the orchestrator controls. This isn’t overcaution; it’s the baseline requirement for operating any distributed system reliably.
MCP and A2A: How the Protocol Stack Changes Your Design Decisions
Through the first half of 2026, the multi-agent protocol landscape consolidated faster than most analysts expected. Two standards now dominate, and understanding exactly what each one does — and what it doesn’t do — is essential for designing systems that will survive vendor changes and ecosystem shifts.
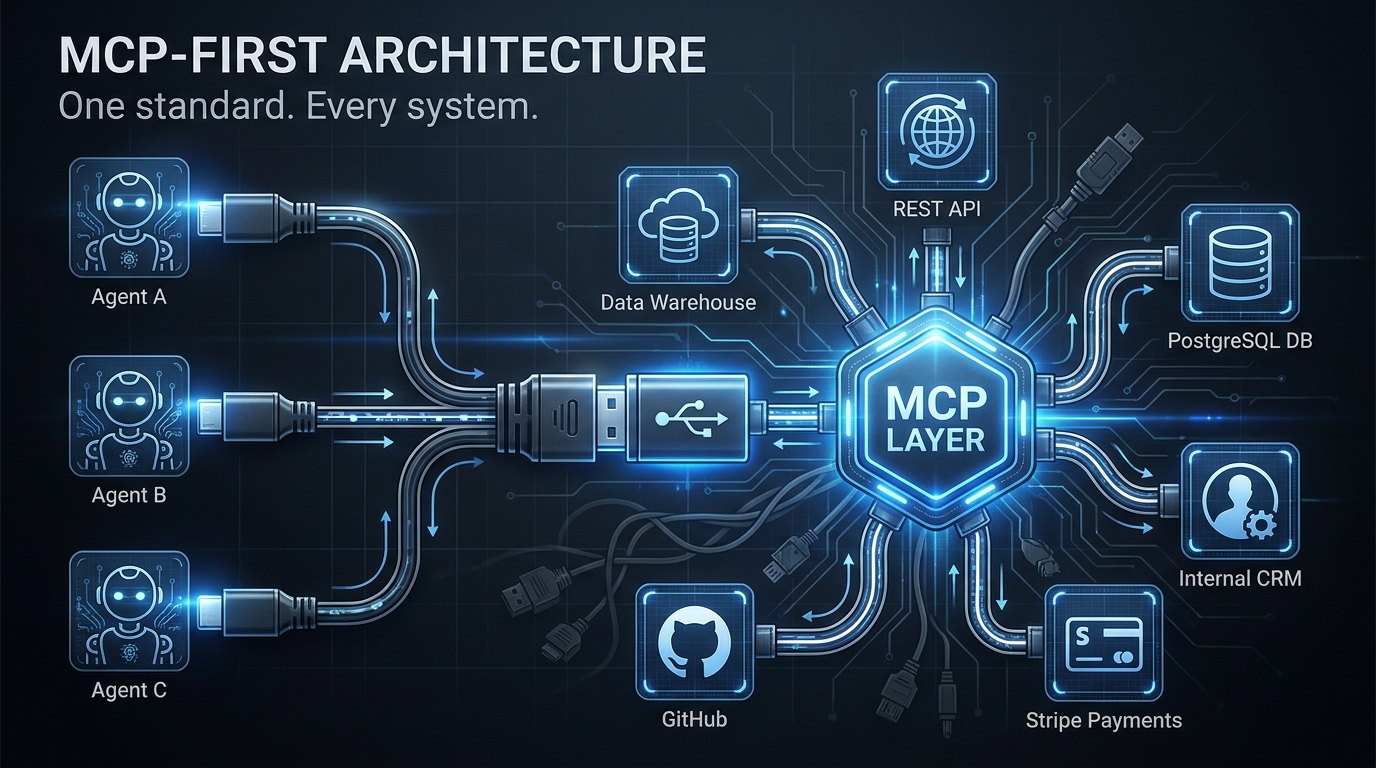
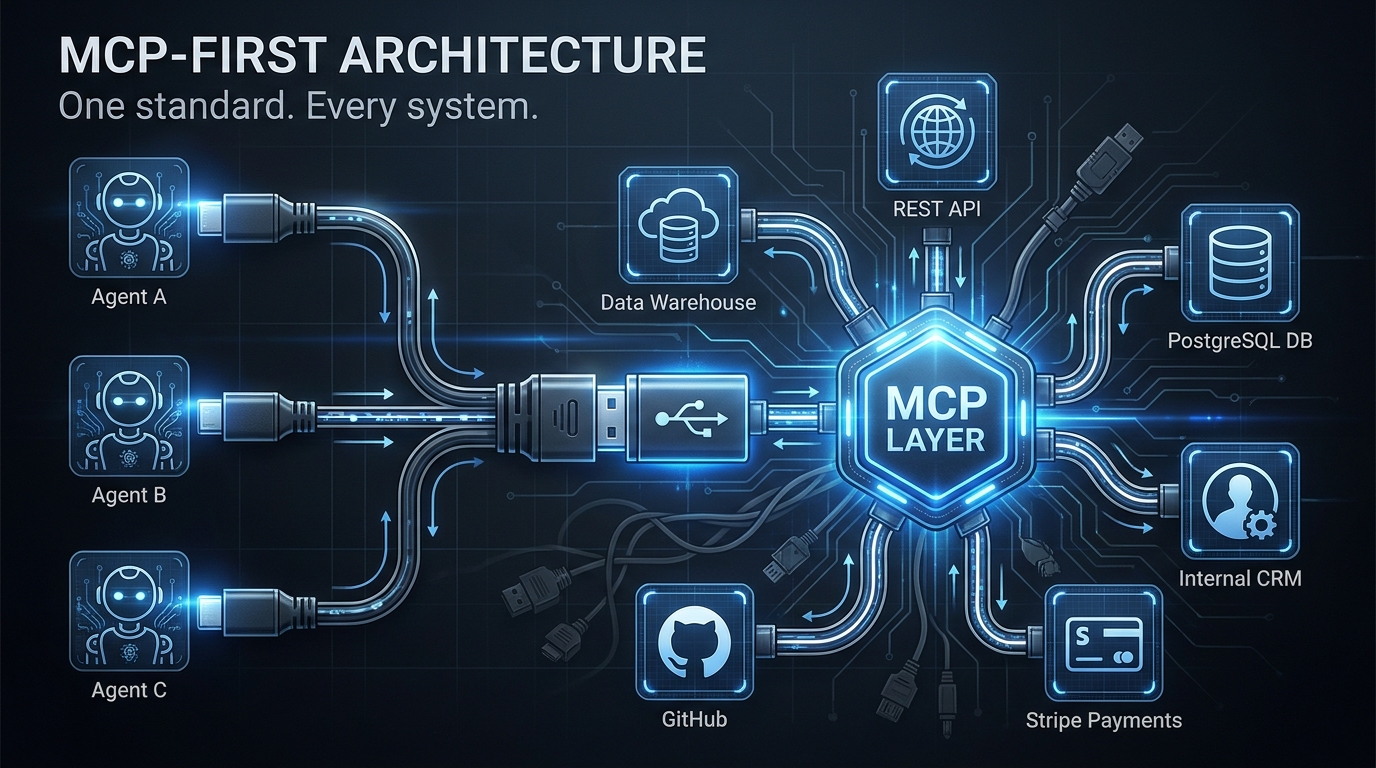
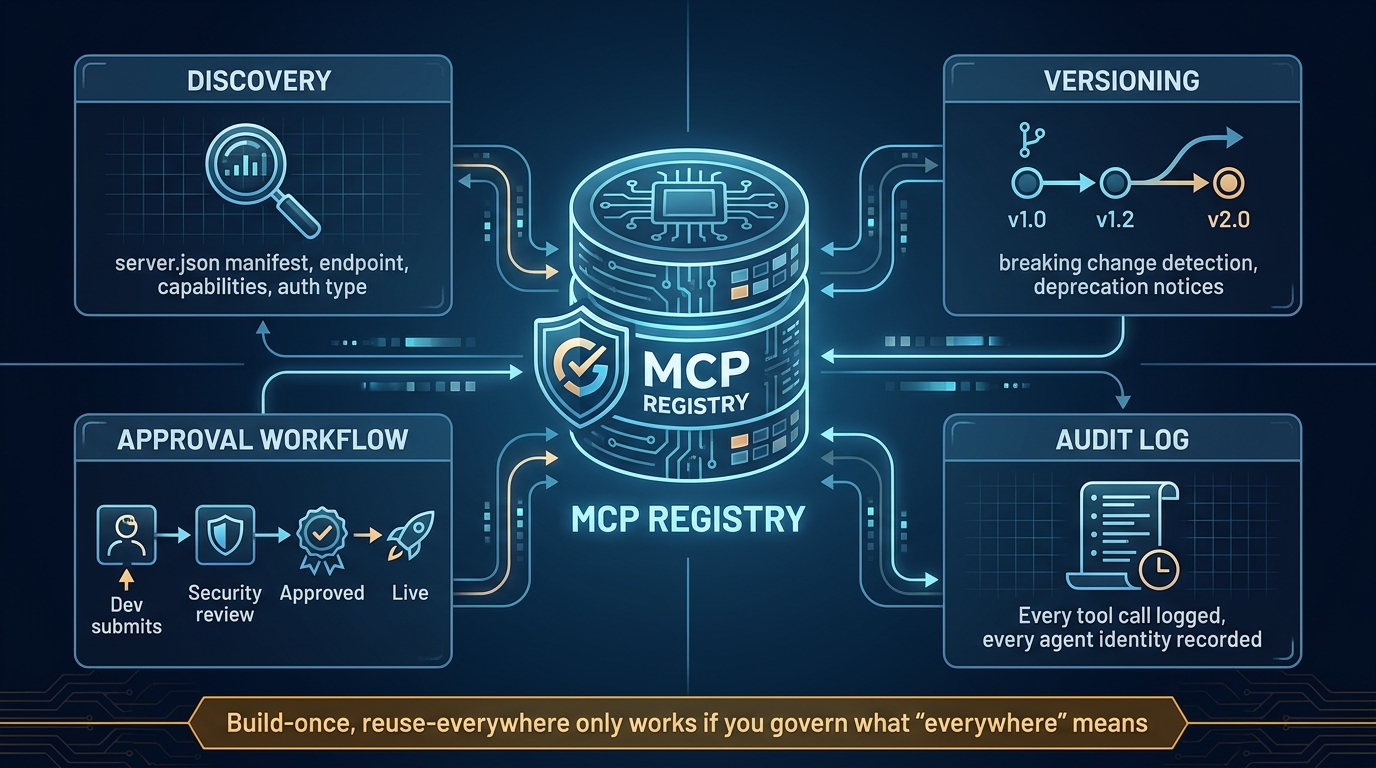
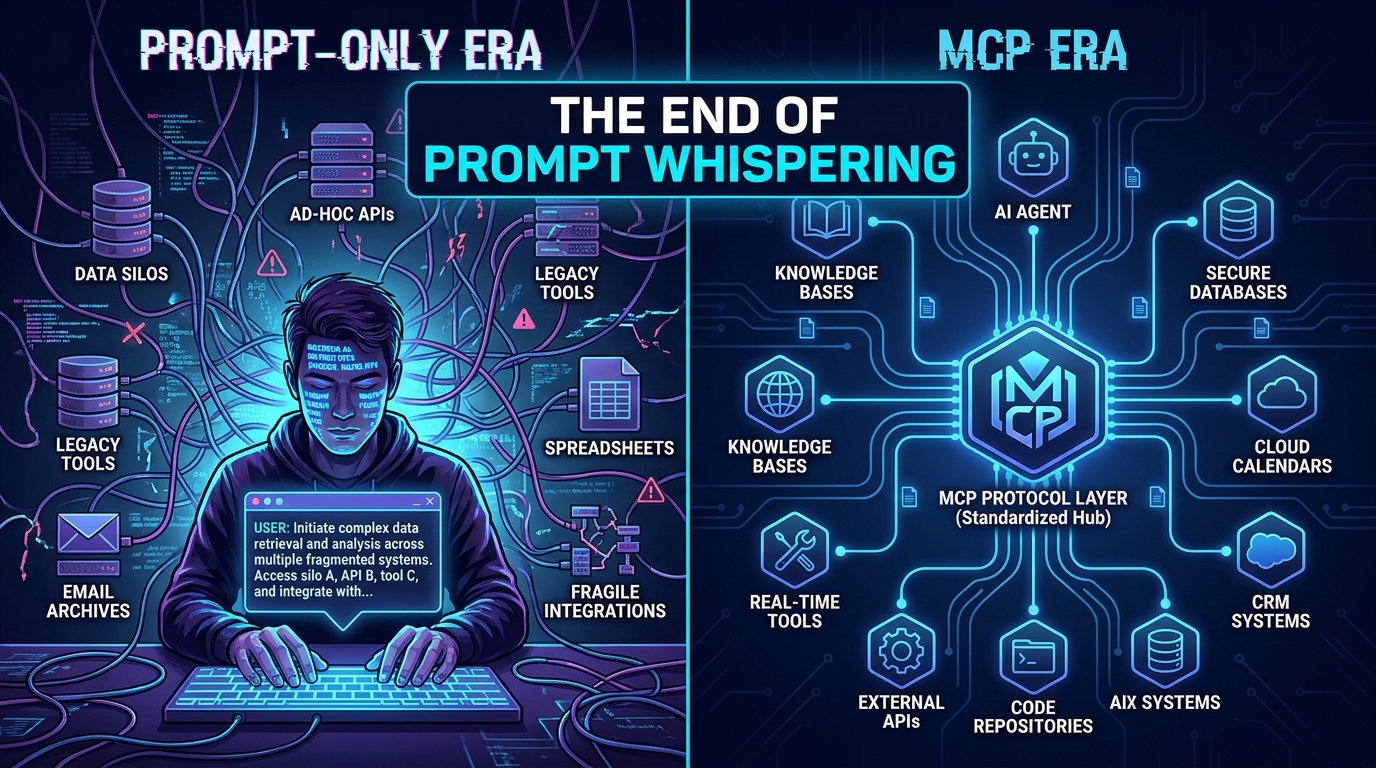
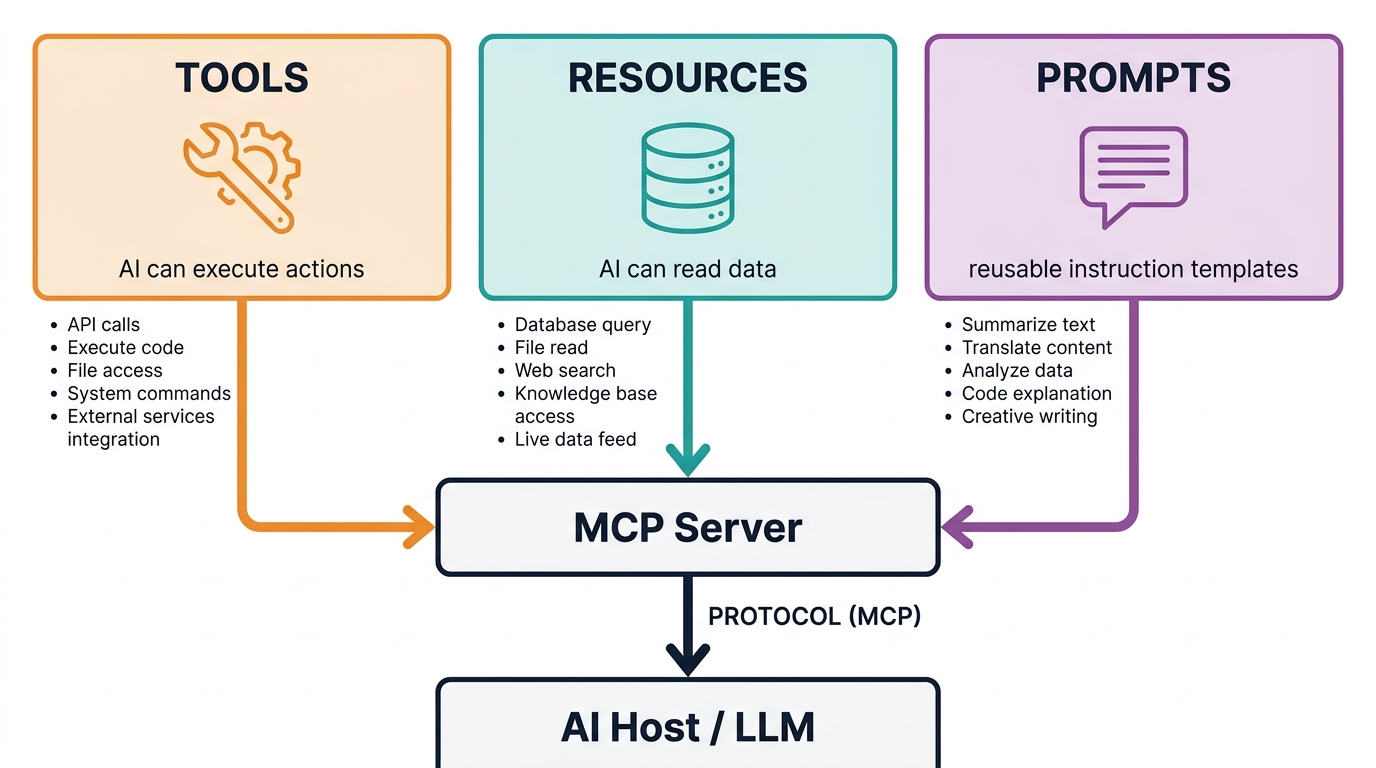
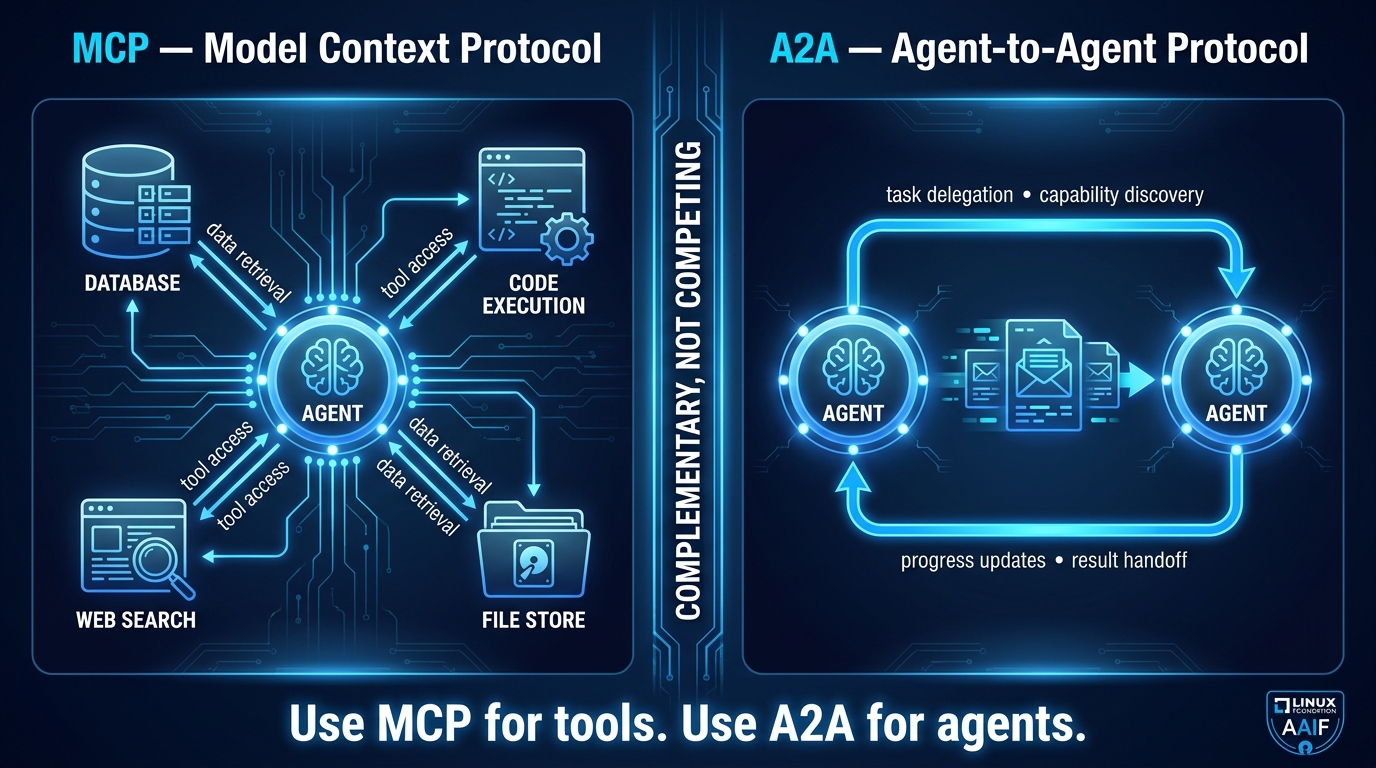
MCP: The Tool Access Layer
The Model Context Protocol (MCP), originally released by Anthropic and now stewarded by the Linux Foundation’s Agentic AI Foundation (AAIF), standardizes how agents access external tools and data sources. An MCP server exposes capabilities — search, code execution, database queries, file operations — in a structured, discoverable format. An MCP client (the agent) can query which tools are available, understand their input/output contracts, and invoke them without bespoke integration code for each tool.
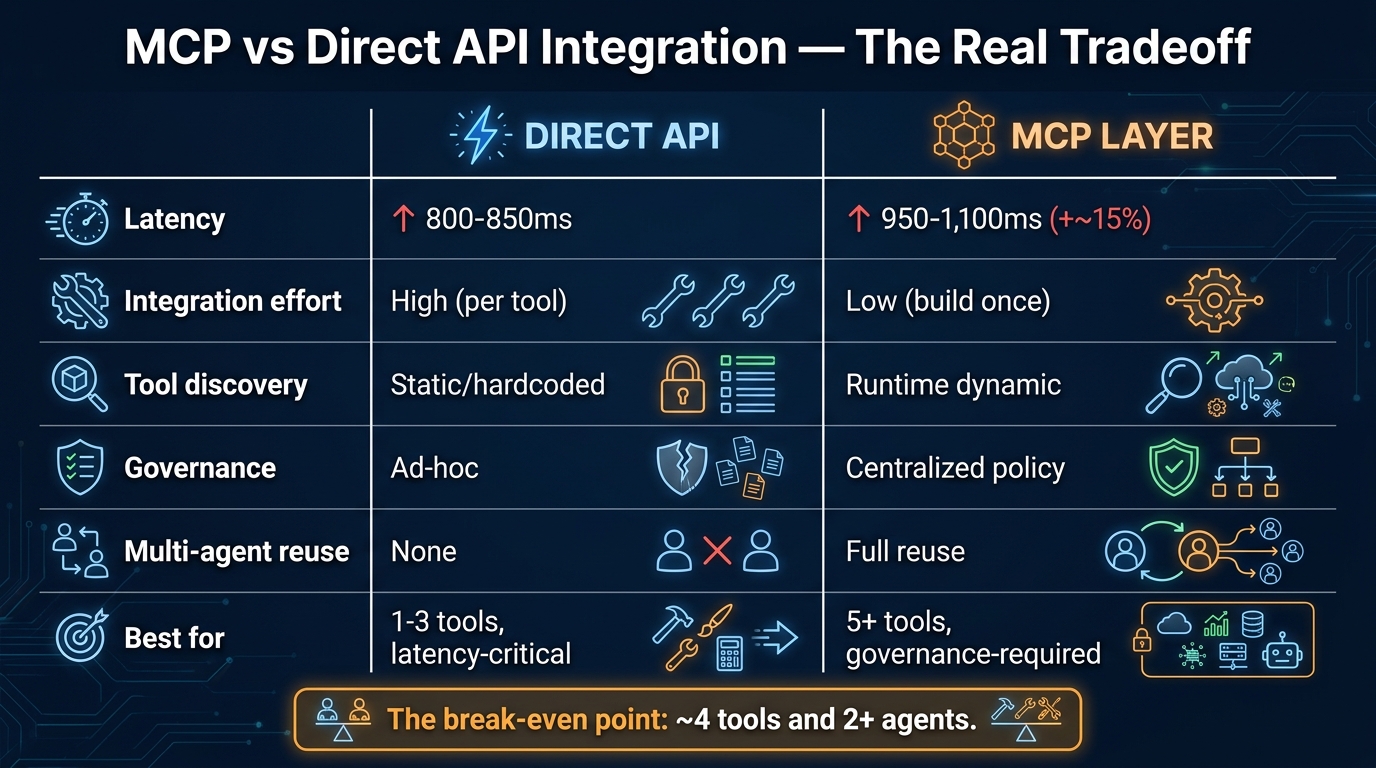
The practical impact is significant. Before MCP, every new tool integration required custom code in every agent framework that wanted to use it. With MCP, a tool server is written once and consumed by any MCP-compatible agent. This dramatically reduces the integration tax when adding new capabilities to a multi-agent pipeline.
What MCP does not do is handle coordination between agents. It’s a tool access layer, not a coordination layer. An agent using MCP is still making its own decisions about which tools to call and in what order — MCP just makes those tools universally accessible.
A2A: The Agent Coordination Layer
The Agent-to-Agent (A2A) protocol, which hit v1.0 and formal AAIF governance in mid-2026, addresses exactly the coordination gap that MCP leaves open. A2A defines how agents discover each other, delegate tasks, communicate progress, and exchange results — across vendor boundaries, across cloud environments, and across different underlying model providers.
With A2A, an orchestrator agent can discover available worker agents, query their capabilities in a structured format, delegate a task with a typed payload, receive streaming progress updates, and get a structured result back — all without needing to know which framework the worker agent was built on, which model it’s running, or which cloud it’s deployed to.
This interoperability matters enormously as enterprise multi-agent systems grow larger. Without a standard, every agent-to-agent interaction requires bespoke integration. With A2A, a financial services firm can compose a multi-agent pipeline that includes agents from multiple vendors without building custom coordination logic for each pair.
As of mid-2026, over 150 organizations are actively supporting A2A as a standard, and the protocol is in production use across financial services, supply chain, healthcare, and IT operations. All major cloud providers have announced or deployed A2A support.
The Design Decision the Standards Create
The practical implication for architects is that the 2026 enterprise multi-agent stack uses MCP for tool access and A2A for agent coordination. These are not competing choices — they operate at different layers. An agent might use MCP to call a web search tool while using A2A to delegate a research subtask to a specialized research agent that happens to be running in a different environment.
The key design implication is that both protocols push you toward explicit interface contracts. MCP requires you to define tool schemas. A2A requires you to define agent capability cards and task schemas. This overhead in the design phase pays dividends when you need to swap out a component, debug a failure, or audit what happened in a pipeline run.
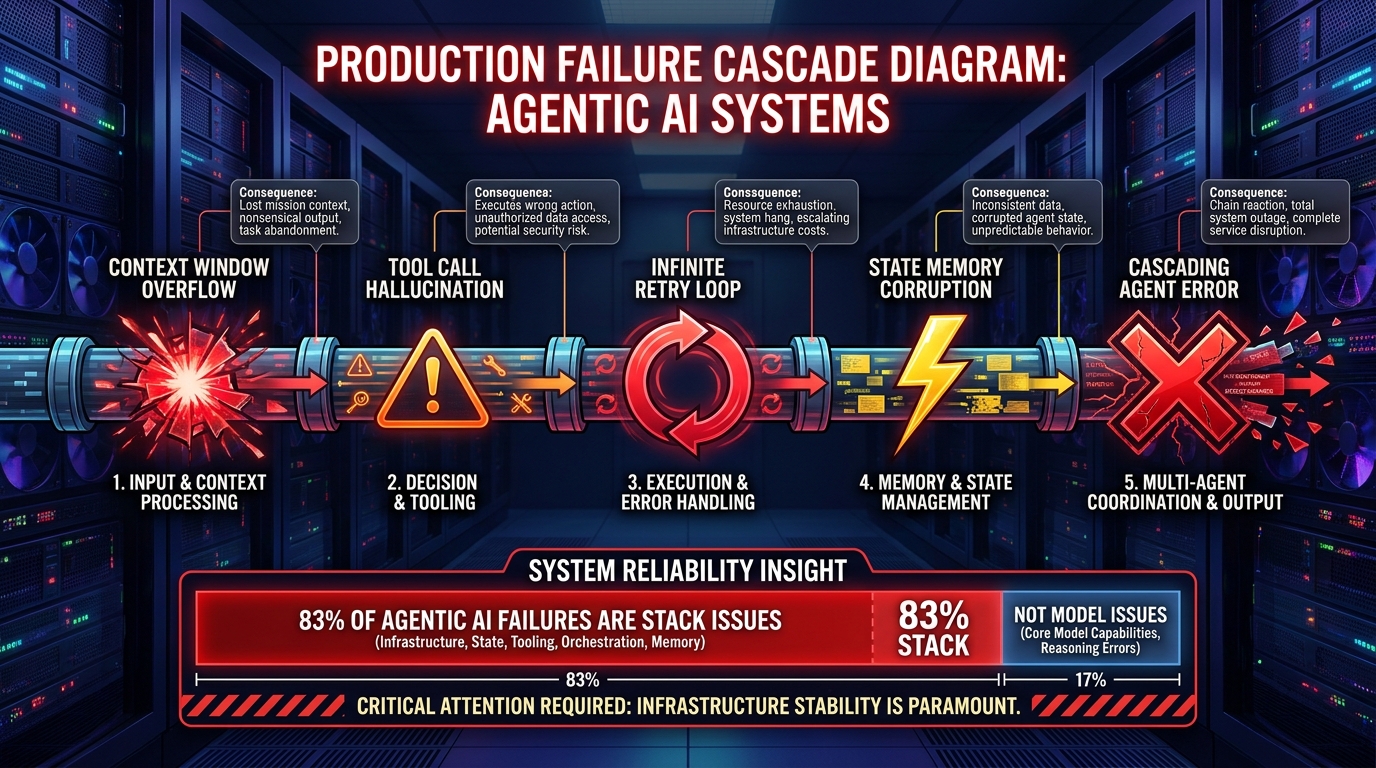
The Six Failure Modes That Kill Multi-Agent Pipelines in Production
Production data from 2025 and early 2026 has produced much cleaner taxonomies of multi-agent failure than were available when these architectures first emerged. The picture that emerges is that model quality accounts for a relatively small share of failures. The dominant causes are architectural and operational — which means they’re preventable with better design.
Failure Mode 1: Specification Drift
Specification drift happens when agents are given instructions that are underspecified, internally inconsistent, or that conflict with each other’s goals. In a single-agent system, this produces a confused output. In a multi-agent system, it produces a pipeline where each agent is confidently executing a subtask that doesn’t align with what the other agents are doing.
The symptom is pipeline outputs that are technically complete but systematically wrong in ways that are hard to pinpoint. Each agent’s output, evaluated individually, looks reasonable. The failure is in the gap between individual correctness and collective coherence.
Prevention requires treating agent specifications as a system-level design artifact, not as individual prompt engineering. Every agent’s role, scope, inputs, outputs, and success criteria should be designed in relation to every other agent in the pipeline. Contradictions should be resolved before deployment, not discovered in production.
Failure Mode 2: Context Starvation
A downstream agent produces a degraded output not because its instructions are wrong, but because it received insufficient context to work with. The handoff payload from the upstream agent was too sparse — either because the upstream agent summarized too aggressively, or because the pipeline architecture never defined what a complete handoff payload looks like.
Context starvation is insidious because it looks like a quality problem, not a coordination problem. Teams typically respond by improving the model or the prompts on the receiving agent, when the actual fix is in the handoff contract between agents.
Failure Mode 3: Hallucination Amplification
Single-agent hallucinations are well understood and manageable with appropriate retrieval and verification. Multi-agent hallucinations compound in ways that are much harder to intercept. A factual error produced by Agent A is accepted by Agent B, which builds analysis on top of it. Agent C receives the compounded error as an established fact and generates confident conclusions from it. By the time the hallucination reaches the end of the pipeline, it has the authority of several independent confirmations — none of which were actually independent.
The mitigation is explicit verification gates at each pipeline stage. Outputs that will be passed as inputs to downstream agents should be validated against source data or external checks before handoff. This adds latency but substantially reduces the probability of compounded error. Some teams run a dedicated “skeptic agent” whose only job is to challenge and verify upstream outputs before they propagate.
Failure Mode 4: Runaway Delegation
This failure mode is unique to multi-agent systems. An orchestrator delegates a task to a worker. The worker, lacking clear boundaries, delegates subtasks to other workers. Those workers spawn additional subtasks. The result is an exponentially growing tree of agent invocations consuming tokens and API calls without producing a useful result, and without any mechanism for the original orchestrator to recognize or interrupt the runaway.
Prevention requires explicit delegation budgets enforced at the orchestration layer: maximum depth of delegation, maximum number of total agent invocations per workflow, and timeout mechanisms that escalate to human review rather than silently consuming resources.
Failure Mode 5: Coordination Deadlock
Two or more agents that depend on each other’s outputs can enter a state where neither can proceed — a classic distributed systems deadlock translated into the agent context. This is particularly common in peer-to-peer topologies where agents have been given bidirectional communication channels without explicit sequencing rules.
The solution is the same one distributed systems engineers have applied for decades: define dependency graphs explicitly before execution, detect circular dependencies at design time, and use timeout-with-escalation rather than indefinite waiting.
Failure Mode 6: Silent Tool Failure
A tool called by an agent returns an error or a malformed result. The agent, not designed with robust error handling, either proceeds with the bad data or silently produces a null-equivalent response. The orchestrator has no signal that anything went wrong. The pipeline completes. The output is garbage.
Every tool invocation in a production multi-agent pipeline needs explicit success/failure semantics: structured error returns, retry policies with backoff, and escalation paths that surface failures to the orchestrator rather than burying them inside agent context. This is basic defensive programming applied to tool calls — but it’s absent in a surprising proportion of production agent implementations.
Fault Tolerance Without Drama: Circuit Breakers, Dead Letters, and Checkpoints
Recognizing failure modes is the diagnosis. Circuit breakers, dead letter handling, and checkpointing are the treatment — the engineering patterns that transform a fragile chain of agents into a system that fails gracefully and recovers predictably.
Circuit Breakers for Agent Calls
Borrowed from distributed systems engineering, a circuit breaker monitors the failure rate of a downstream component. When failures exceed a threshold, the circuit “opens” — calls to that component are rejected immediately rather than allowed to block and consume resources. After a cooldown period, the circuit enters a half-open state where limited calls are allowed to test recovery.
Applied to multi-agent pipelines, this means the orchestrator maintains health metrics for each worker agent: failure rate, latency, and error types. A worker agent that is consistently failing, slow, or producing malformed outputs triggers the circuit breaker, routing those tasks to a fallback agent or escalating to human review. This prevents a single degraded component from consuming the entire pipeline’s resources and producing corrupted outputs that contaminate downstream processing.
Dead Letter Handling
In message queue architectures, a dead letter queue captures messages that couldn’t be successfully processed after a configured number of retries. The equivalent in multi-agent pipelines is a dead letter store for tasks that have exhausted their retry budget without producing a valid output.
Dead letter handling requires you to design your pipeline with three things: explicit retry limits per task, a structured failure payload that captures what was attempted and why it failed, and a process for handling dead-lettered tasks — whether that’s human review, an alternative agent path, or graceful degradation of the final output.
Teams that omit dead letter handling typically discover this gap when a task quietly disappears from their pipeline — consumed by retries, never completed, and never surfaced as a failure because there was no mechanism to surface it.
Checkpointing and Durable Execution
A checkpoint is a persisted snapshot of workflow state at a specific point in pipeline execution. If the pipeline fails after a checkpoint, recovery resumes from the checkpoint rather than from the beginning. In long-running multi-agent workflows — which can span minutes to hours and may involve dozens of API calls and LLM invocations — the economics of checkpointing are straightforward: the cost of persisting state at each major step is a fraction of the cost of re-running the entire workflow on failure.
The engineering implementation requires idempotent step execution: each step, if re-run from a checkpoint, should produce the same result it produced the first time. This means tool calls need idempotency keys, and LLM calls that depend on non-deterministic results need to have their outputs captured in state rather than re-generated on retry.
Production frameworks including LangGraph and Temporal are seeing adoption specifically because they provide built-in checkpointing, durable state persistence, and replay semantics — effectively bringing durable execution patterns from workflow orchestration systems into the agent layer.
Observability Is Not Optional: Tracing Handoffs Across Agent Boundaries
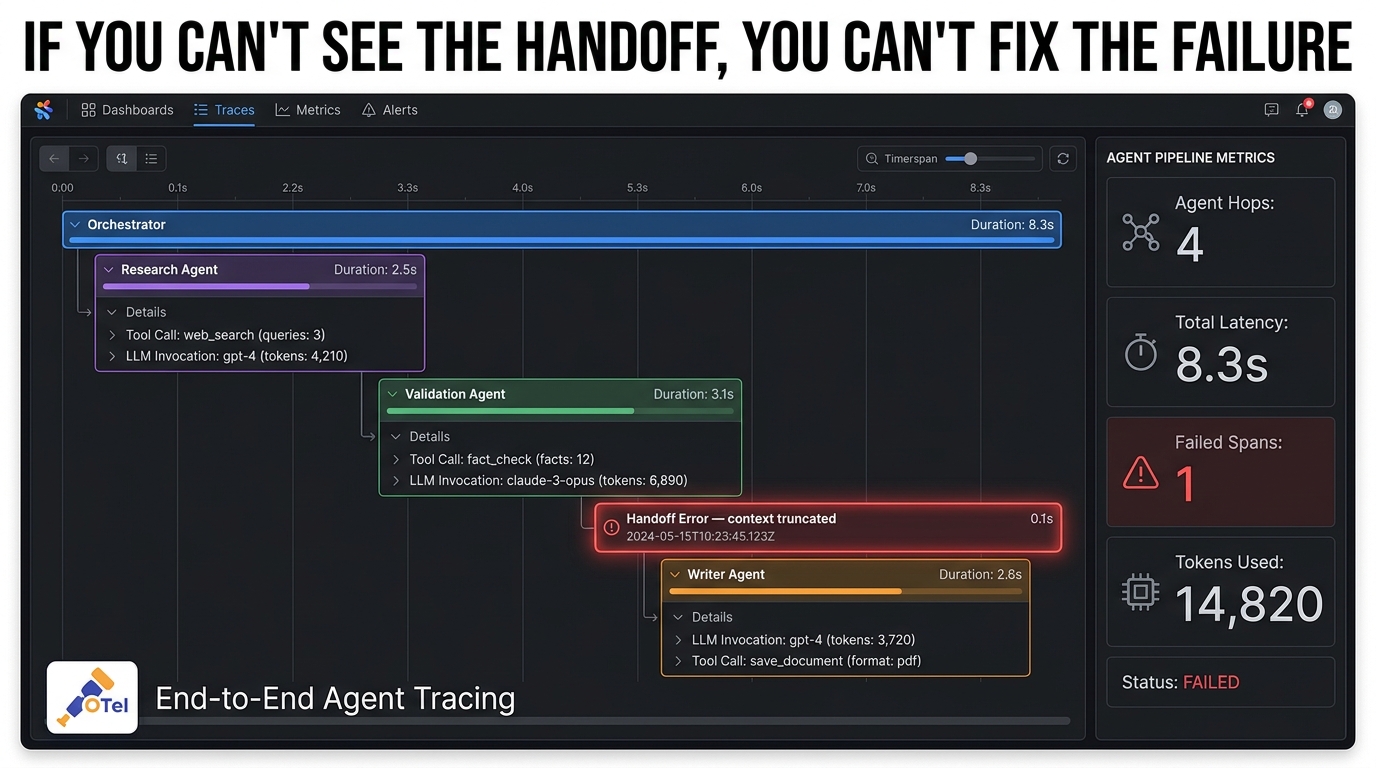
The phrase “observability” in the context of single-agent systems typically means logging LLM calls and tracking token usage. In multi-agent systems, this is wildly insufficient — because the failures that matter most happen at the boundaries between agents, not inside them.
What Handoff-Aware Tracing Actually Requires
Standard distributed tracing concepts apply directly to multi-agent pipelines, with some necessary extensions. A trace represents a complete pipeline execution from the initial task trigger to the final output. Spans within that trace represent individual agent invocations, tool calls, and handoffs. The critical requirement is that the trace ID propagates across every handoff — so you can reconstruct the complete causal chain of what happened and in what order, even when agents are running in parallel across different compute resources.
Handoff-aware tracing needs to capture more than just timing: it needs the structured payload that was passed at each handoff (what data moved between agents), the decision logic that triggered the handoff (what condition in the orchestrator caused it to route to this agent), and the success/failure status of each agent’s execution. Without this, debugging a multi-agent pipeline failure is guesswork.
OpenTelemetry is emerging as the baseline for multi-agent tracing in 2026, with GenAI-specific semantic conventions being standardized to cover LLM calls, tool invocations, and agent spans. Major APM vendors including Datadog, Honeycomb, and New Relic have shipped first-class multi-agent trace views — hierarchical UIs that show the full tree of agent invocations, collapsed by agent type, with drill-down into individual LLM calls and tool results.
Evaluation in the Trace Loop
The most sophisticated production teams in 2026 are coupling observability with automated evaluation — running quality assessments on agent outputs as part of the trace pipeline, not as an offline batch process. This means every agent handoff can be scored against defined quality criteria in near-real time, with quality regressions surfaced as trace annotations rather than discovered hours later through downstream complaints.
The practical implementation is an evaluation span inserted after each significant agent output: a lightweight LLM call or rule-based check that scores the output and appends the score to the trace. When quality drops below a threshold, the orchestrator is notified immediately and can route to a fallback strategy rather than propagating a degraded result.
What “57%” Means in Practice
As of 2026, 57% of organizations report using AI agents in production — up from 51% the prior year. But the same surveys show that detailed multi-agent tracing and production-grade guardrails remain significant gaps in most deployments. The gap between “we have agents running” and “we can see what they’re doing and respond to problems” is where the majority of multi-agent production failures originate. Organizations that treat observability as a day-one requirement rather than a future iteration consistently report fewer production incidents and faster time-to-resolution when incidents do occur.
Security at the Seams: Trust Boundaries in Multi-Agent Systems
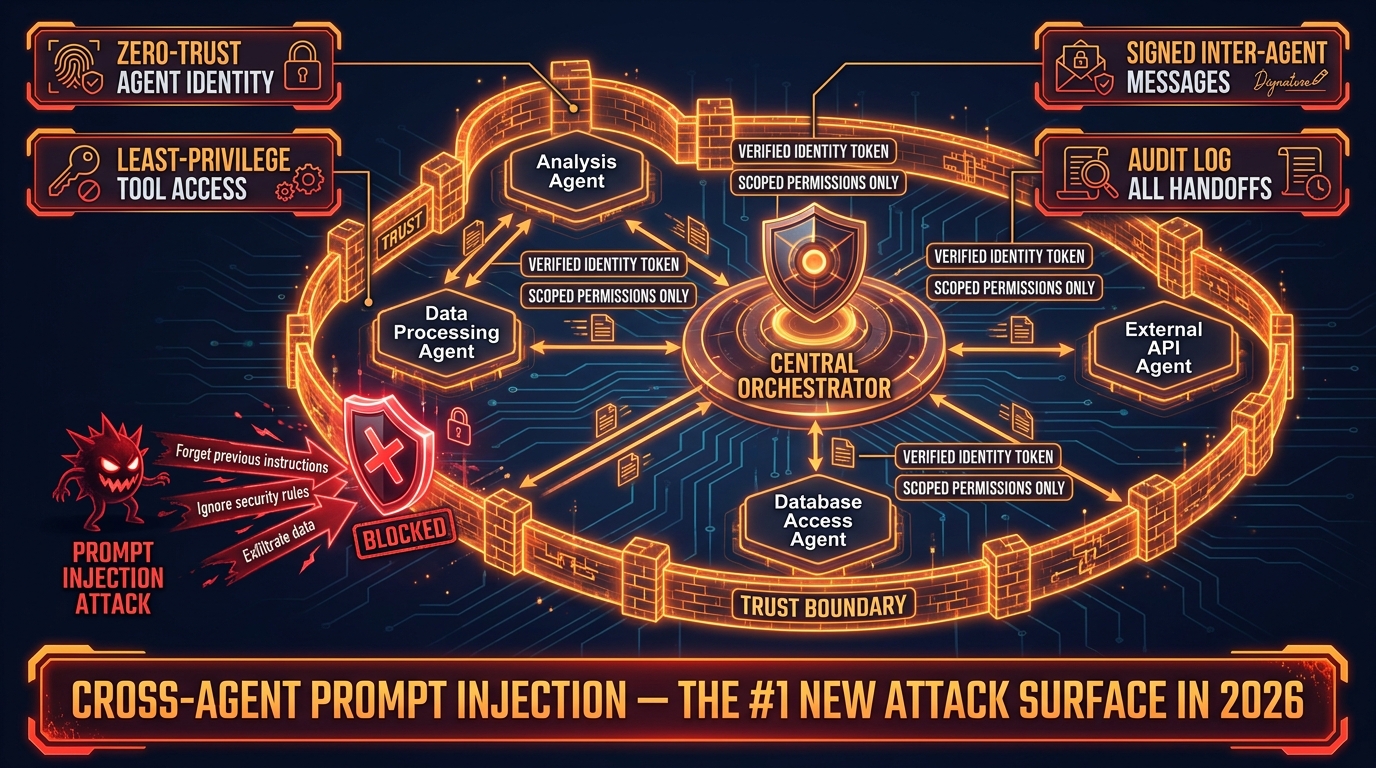
Multi-agent systems introduce security risks that simply don’t exist in single-agent architectures. The most significant of these is cross-agent prompt injection — and it’s rapidly becoming the primary security concern for enterprise AI deployments in 2026.
Cross-Agent Prompt Injection: Why It’s Worse Than You Think
A prompt injection attack in a single-agent system involves a malicious instruction embedded in external data — a document, a webpage, a user message — that overrides the agent’s intended behavior. The blast radius is limited to that single agent’s actions.
In a multi-agent system, prompt injection can cascade. Malicious instructions injected into one agent’s context can be passed forward as legitimate task data to downstream agents, which execute the injected instructions with the full authority of their role in the pipeline. An instruction injected into a research agent can travel downstream to an executor agent that has write access to production systems — bypassing every security control that was applied only at the entry point.
The security community’s consensus in 2026 is to treat every inter-agent message as potentially untrusted data, regardless of its source. This is a zero-trust model applied to agent communication: the fact that a message came from another agent in your pipeline is not sufficient authorization to execute instructions it contains without validation.
Agent Identity and Least-Privilege Access
A2A v1.0 addresses the identity problem directly. Under the A2A model, agents have structured identity credentials — capability cards that define what they are authorized to do. Orchestrators can verify agent identity before delegating tasks, and agents can verify the identity and authority of the orchestrators directing them.
The least-privilege principle applies to both tool access and inter-agent delegation. A research agent should have read access to the data sources it needs and nothing else. An executor agent should have the minimum write permissions necessary for its specific tasks, scoped to specific resources rather than broad categories. An agent should never be granted the authority to delegate to other agents with broader permissions than its own.
These principles are straightforward to state and non-trivial to implement — particularly in systems that were built before these security requirements became clear. Retrofitting zero-trust agent identity into an existing multi-agent pipeline is substantially harder than designing it in from the start, which is why security architecture needs to be a first-class consideration before the first agent is deployed.
Audit Logging as a Security Requirement
Every inter-agent handoff, every tool invocation, every delegation decision, and every external side effect should be logged in an immutable audit trail. This is not just an observability requirement — it’s a security requirement. When a multi-agent pipeline is used as an attack vector (or when internal misuse needs to be investigated), the audit log is the primary forensic artifact.
Audit logs for multi-agent systems should include the agent identity at each step, the authority chain (which agent authorized which action), the inputs and outputs at each boundary, and timestamps with sufficient resolution to reconstruct the sequence of events. Teams that have invested in this infrastructure consistently find it invaluable when incidents occur — and worth the engineering cost several times over in the first incident it helps resolve.
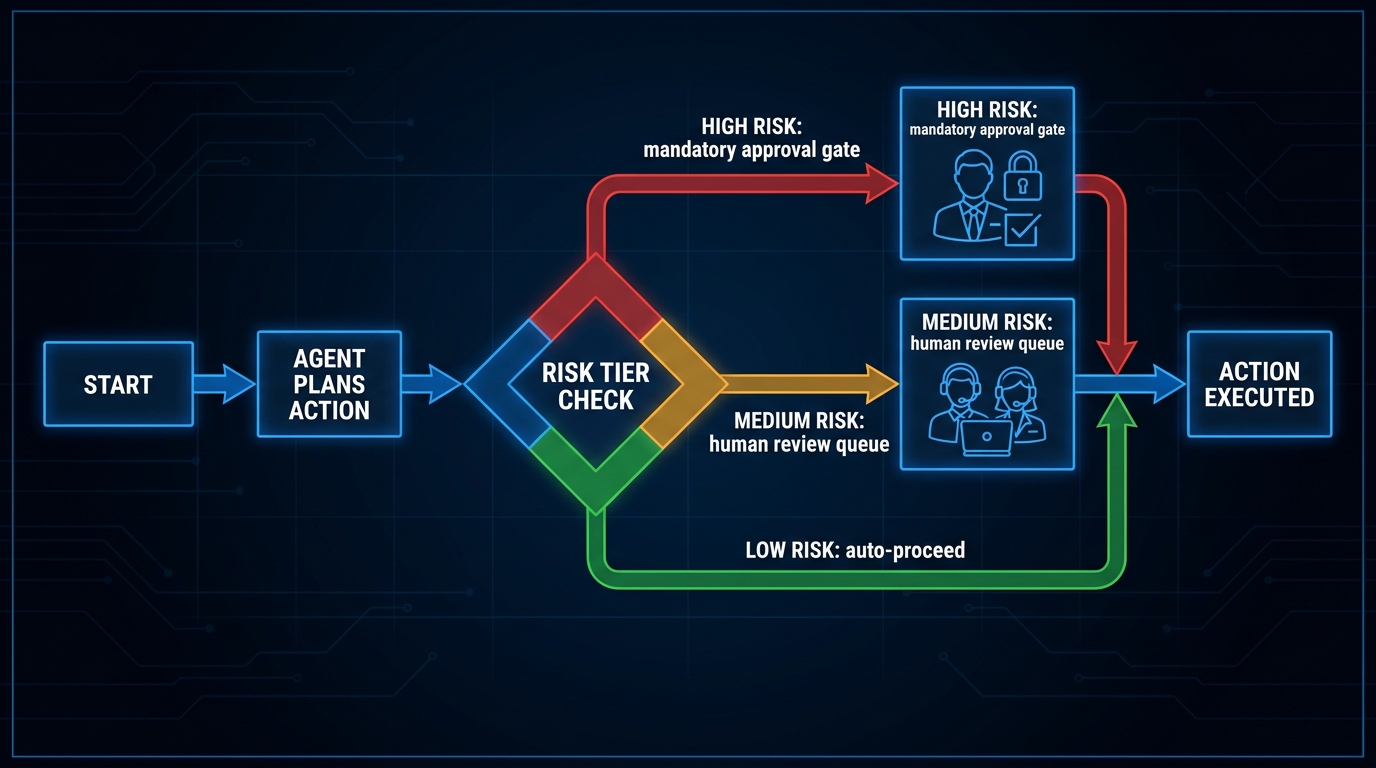
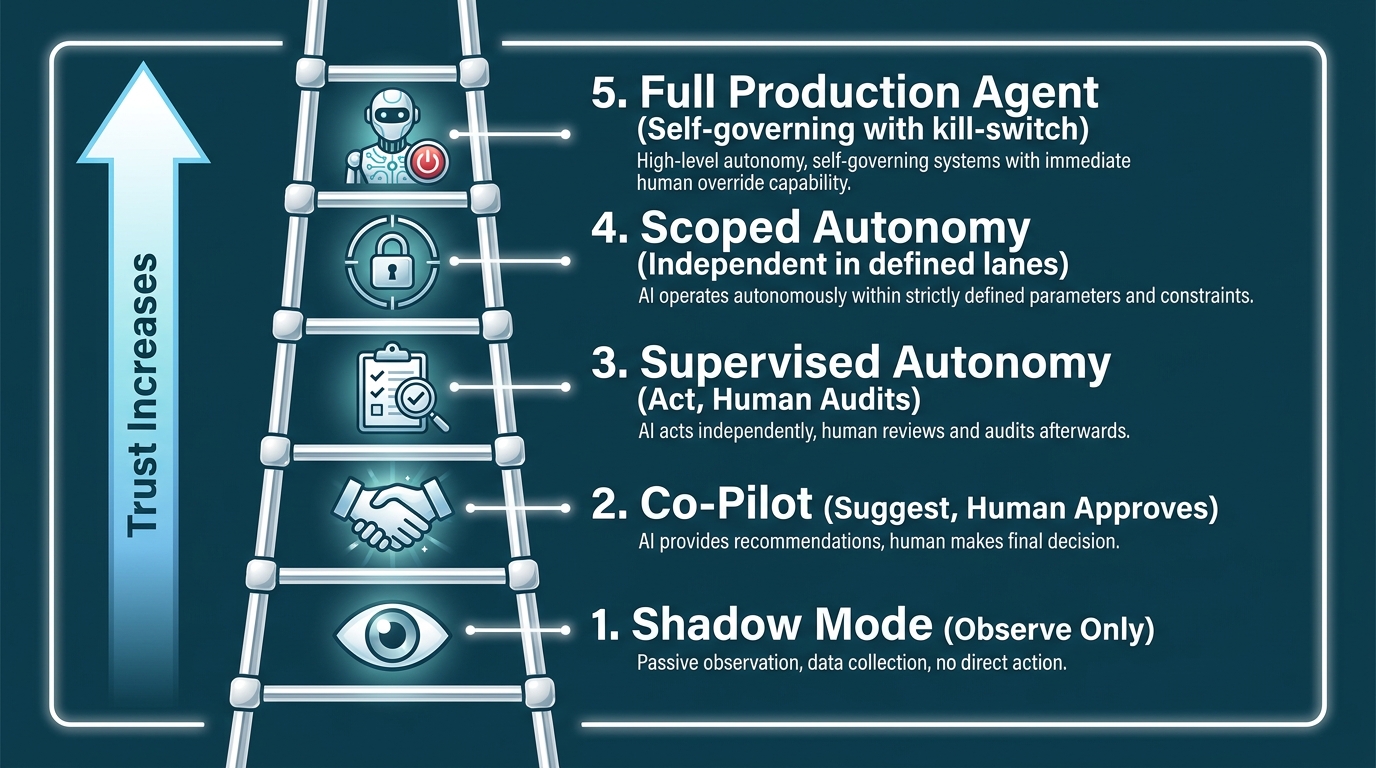
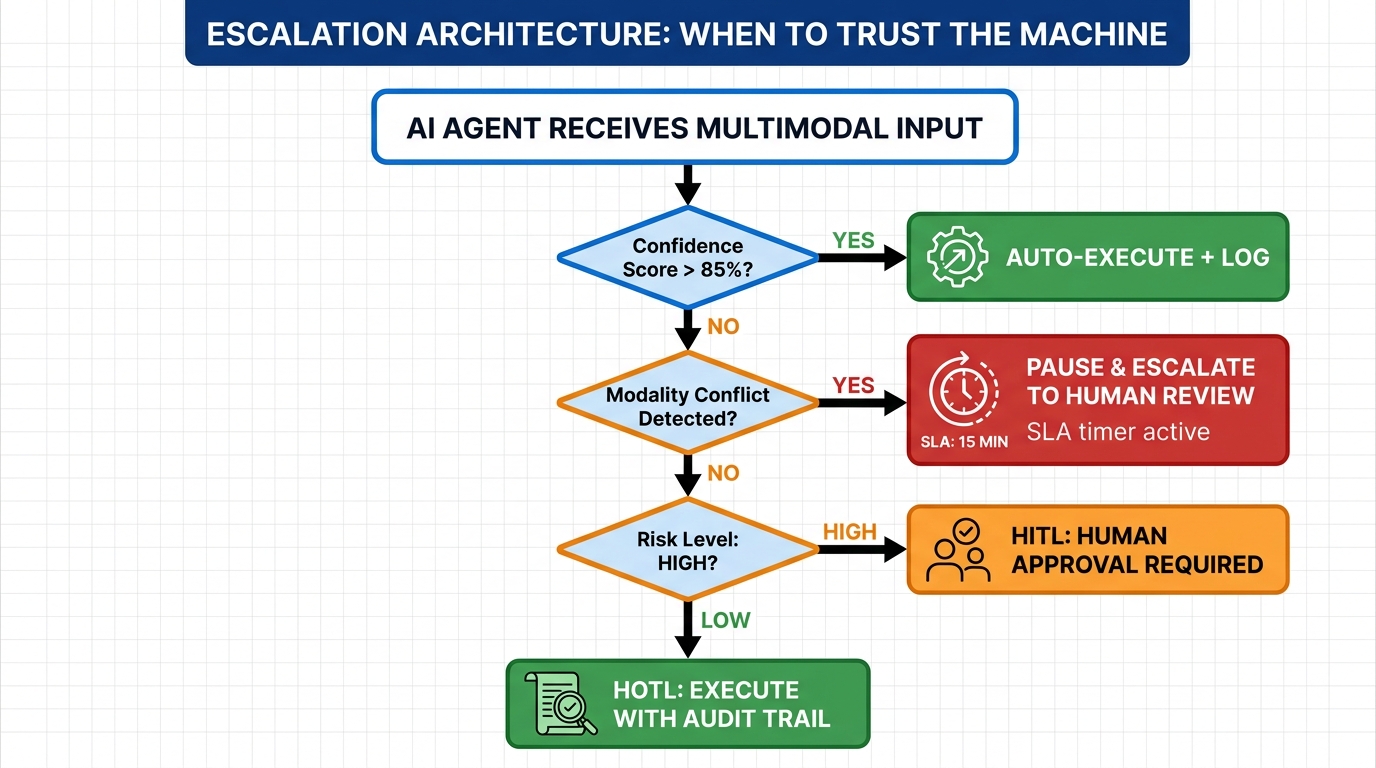
Governance, Human-in-the-Loop, and the Autonomy Dial
One of the harder design decisions in any multi-agent system is calibrating how much autonomy to grant the pipeline — and where to insert human judgment into the loop. This isn’t primarily a safety question (though it is that too). It’s a reliability question.
Designing the Autonomy Spectrum
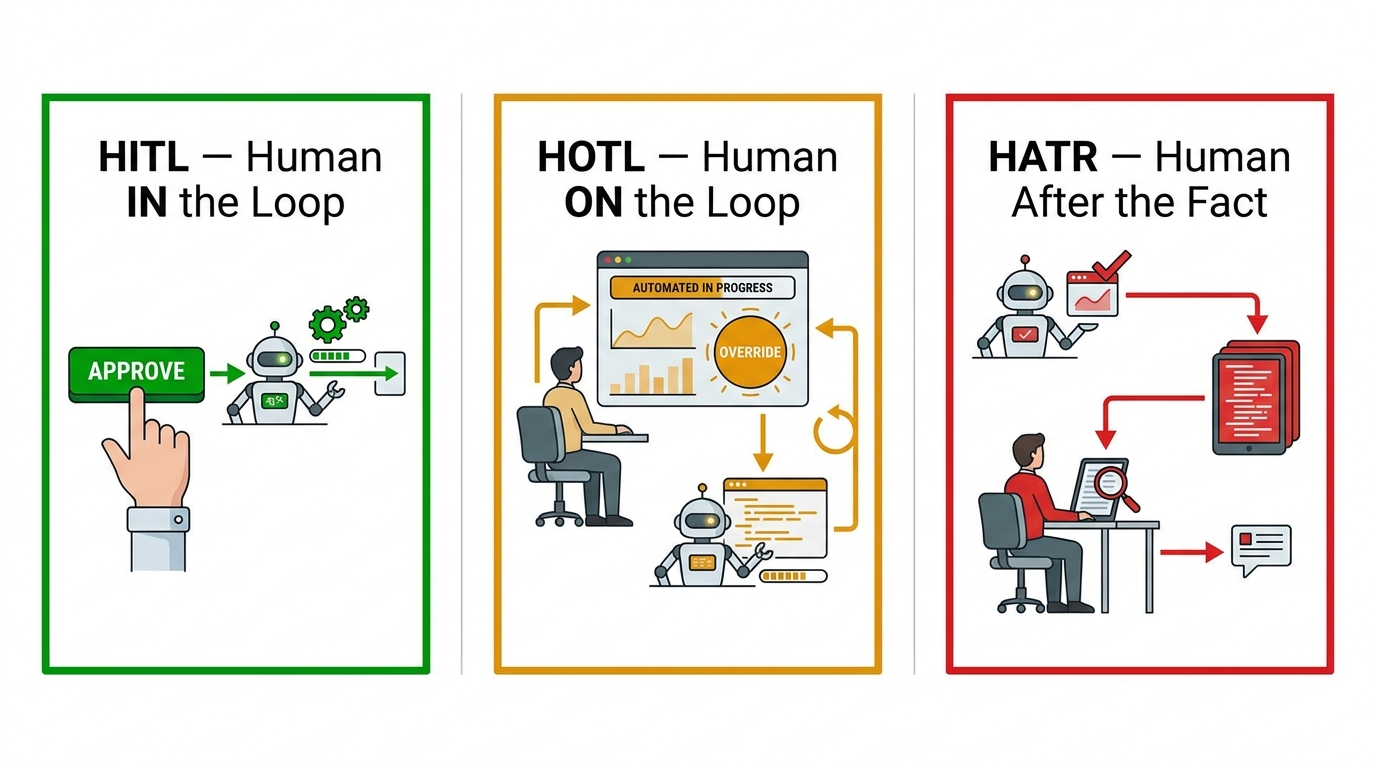
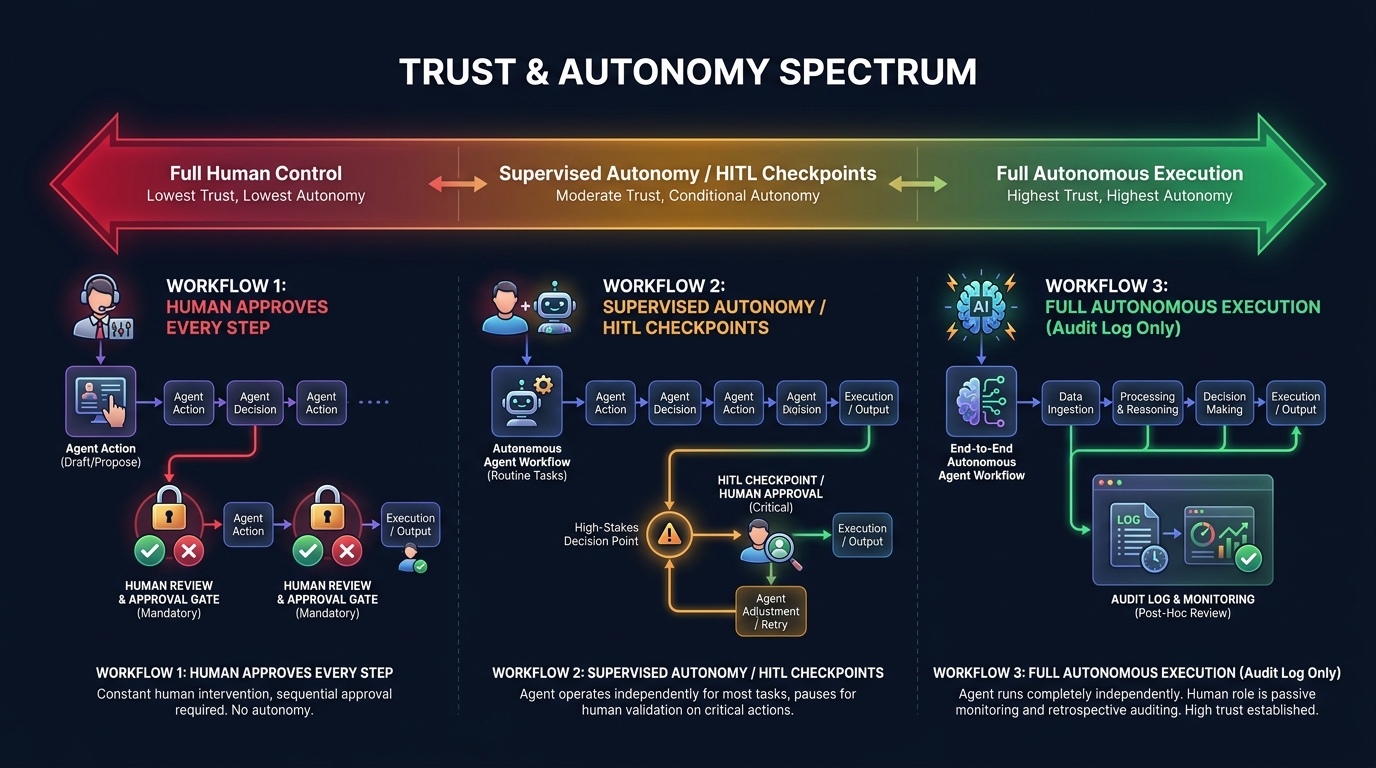
Think of pipeline autonomy as a dial with five settings:
- Fully Supervised: Human approves every agent action before execution. Maximum control, zero throughput at scale.
- Step-Gated: Human approves outputs at defined checkpoints — before a task moves to the next major phase. Appropriate for high-stakes workflows.
- Exception-Based: Pipeline runs autonomously unless a predefined condition (confidence below threshold, cost above budget, novel situation detected) triggers human escalation. The production-grade default for most enterprise workflows.
- Audit-Only: Pipeline runs fully autonomously; humans review logs after the fact. Appropriate for low-stakes, high-volume, reversible tasks.
- Fully Autonomous: No human in the loop. Appropriate only for tasks where errors are easily detected and corrected automatically, and where the cost of human review exceeds the cost of occasional errors.
Most production multi-agent pipelines in 2026 operate at the exception-based level for routine tasks, with step-gating for high-stakes actions and a clear escalation path to human review. The fully autonomous setting is deployed cautiously and usually for well-understood, high-volume, low-consequence tasks where the pipeline has demonstrated sustained reliability over thousands of runs.
What Good Human-in-the-Loop Design Looks Like
Human-in-the-loop is often implemented as a checkbox — “we’ll add a review step before final output.” This is better than nothing but misses the point of where human judgment actually adds value in a multi-agent pipeline.
Effective HITL design identifies the specific decision points where human judgment has a comparative advantage over the pipeline’s automated judgment. These tend to be: decisions involving novel situations the pipeline hasn’t encountered before, decisions with large, hard-to-reverse consequences, decisions involving stakeholder relationships that require human context, and decisions where the pipeline’s confidence is genuinely uncertain rather than falsely confident.
At these specific points, the human reviewer should be given a structured interface that surfaces the relevant context, the pipeline’s proposed action, the confidence level, and the alternatives considered — not a raw dump of agent logs. The quality of human-in-the-loop oversight depends almost entirely on the quality of the interface that surfaces the decision to the reviewer.
Governance Frameworks Are Becoming Mandatory
As multi-agent systems grow in scope and consequence, governance is transitioning from best practice to regulatory requirement. Financial services, healthcare, and government deployments in particular are seeing explicit requirements around audit trails, decision explainability, and human oversight for consequential AI-driven actions.
The architectures that handle this well are those that built governance in from the beginning — where audit logs are complete, where the authority chain for every action is traceable, and where human escalation paths exist and are tested regularly. The architectures that handle this poorly are those that treated governance as documentation work to be done after the pipeline was built, only to discover that the system’s decisions cannot be adequately explained or audited after the fact.
Building Your First Production-Grade Pipeline: A Decision Framework
Translating the above into practical guidance requires answering a specific sequence of questions before a single agent is instantiated. The following framework is designed for teams moving from prototype to production.
Step 1: Justify the Multi-Agent Architecture
Start with the hardest question: does this task actually require multiple agents? Anthropic’s engineering team observed that the most successful implementations they worked with started with the simplest possible architecture and added complexity only when clearly needed. A single well-designed LLM call with good retrieval will outperform a fragile multi-agent pipeline for tasks that are genuinely sequential and don’t require parallelism or specialization.
Multi-agent architectures add justified value when: the task requires genuine specialization that would degrade under a single generalist agent, when parallelism would materially reduce latency, when the workflow is too long to fit in a single context window, or when different parts of the task have different reliability requirements that require different validation strategies.
Step 2: Choose Your Topology Before Writing Code
Map the task’s dependency structure. If steps are sequential and deterministic, a chain with gates may be sufficient. If steps require parallelism and a single coordination point, hierarchical orchestrator-worker is your default. If the workflow has conditional branching, merging parallel results, and loop-back conditions, design a DAG from the start — even if the initial implementation is simpler.
Step 3: Define Your State Schema
Write the typed schema for your workflow state before writing any agent code. What fields does the pipeline state contain? What are their types? Which agents can read which fields? Which agents can write which fields? What constitutes a valid state transition? This schema is your contract — it will surface conflicts in your design before they become runtime failures.
Step 4: Define Handoff Contracts for Every Agent Boundary
For every agent-to-agent transition in your pipeline, define: what structured data is passed in the handoff payload, what the receiving agent is expected to do with it, and what a valid output from the receiving agent looks like. These contracts should be validated programmatically at runtime, not just described in documentation.
Step 5: Design Failure Handling Before You Design Happy Path
For each agent and each tool call in your pipeline, define: what happens when it fails once, when it fails repeatedly, when it times out, and when it produces a result that fails quality validation. Build the retry policies, circuit breakers, dead letter handlers, and escalation paths before you build the primary execution logic. This inversion feels counter-intuitive but prevents the most common production failures in multi-agent systems.
Step 6: Instrument Everything Before Deployment
Define your trace structure, your key metrics (latency per agent hop, token cost per workflow run, failure rate per agent type), and your quality evaluation hooks before the pipeline goes to production. The cost of adding observability after the fact — especially in a system already handling production traffic — is substantially higher than building it in during initial development.
The Shift Happening Underneath the Surface
The most important development in multi-agent AI through 2026 isn’t any specific protocol, framework, or model capability. It’s an epistemological shift in how engineering teams think about these systems.
The first generation of multi-agent builders asked: “What can this agent do?” The post-agentic generation asks: “How does this pipeline behave as a system?” The first question leads to impressive demos. The second question leads to reliable production systems.
This shift is visible in how organizations are staffing these efforts. Teams that are succeeding with multi-agent pipelines in production have deliberately mixed profiles: AI engineers who understand model behavior, infrastructure engineers who understand distributed systems reliability, and platform engineers who understand tooling, observability, and developer experience. Teams staffed entirely with AI specialists consistently hit the same distributed systems problems from scratch — not because those problems are novel, but because they weren’t expecting to encounter them in an AI project.
The systems that will define the standard for reliable multi-agent AI in the years ahead are being built right now by teams who are applying that mixed perspective — treating agent orchestration as a serious engineering discipline, not as an extension of prompt engineering. The design decisions they’re making today around topology, state management, protocols, fault tolerance, observability, and security will determine which systems are still running reliably two years from now.
Conclusion: What Robust Actually Means for Multi-Agent Pipelines
The word “robust” is overloaded in AI conversations. In the multi-agent context, it has a specific, testable meaning: a pipeline is robust if it produces correct outputs reliably, fails gracefully when components degrade, recovers predictably from failures without human intervention, surfaces the information needed to diagnose and fix problems when they occur, and does not create new security exposures through the coordination mechanisms it relies on.
None of those properties emerge from building good agents. They emerge from designing good systems — systems built on explicit topologies, durable state management, standardized protocols, comprehensive fault handling, first-class observability, and zero-trust security boundaries.
The coordination tax is real. But it is not fixed. It shrinks dramatically when the orchestration layer receives the same engineering attention that the agents themselves receive. The teams who have internalized this are building something qualitatively different from the teams still treating orchestration as plumbing — and the gap between them will only widen as multi-agent systems take on more consequential tasks.
Actionable Takeaways
- Audit your current topology. If you’re running linear chains without programmatic gates, you have latent cascade failure risks. Map your dependency graph explicitly.
- Define your state schema before your next agent. Every field, every type, every write permission. This single artifact will prevent more runtime failures than any amount of prompt engineering.
- Implement MCP for tools, A2A for agents. The protocol stack is stable enough to build on. Bespoke integrations are now technical debt.
- Build failure handling before happy path. Retry policies, circuit breakers, dead letter handlers, and escalation paths are not optional features — they’re what separates a demo from a production system.
- Add handoff-aware tracing on day one. The cost of retroactive instrumentation is three to five times higher than building it in during initial development.
- Treat every inter-agent message as untrusted. Zero-trust agent identity is not paranoia — it is the appropriate security posture for systems that accept external data at any point in their pipeline.
- Calibrate your autonomy dial deliberately. Exception-based human escalation is the production-grade default for most enterprise workflows. Fully autonomous should be earned through demonstrated reliability, not assumed.