Most conversations about AI automation get the core question wrong. The question isn’t which AI model should we use? It’s what are we actually asking the AI to perceive?
When a customer service agent gets a complaint, it arrives as text. But the full signal behind that complaint might include a photo of a damaged product, a video clip the customer recorded, a prior call transcript, and metadata about their purchase history. If your automation workflow can only read the text of that complaint, you are — by definition — working with a fraction of the available information. You are making decisions from an amputated signal.
This is the multimodal problem. And in 2026, it sits at the center of why some AI automation projects are delivering 300–500% ROI while others are stuck in perpetual pilot mode.
Multimodal AI — systems that can simultaneously process text, images, audio, video, and structured sensor data — has crossed from research curiosity into production deployment. The global multimodal AI market stands at $3.85 billion in 2026 and is tracking toward $13.51 billion by 2031 at a 28.59% compound annual growth rate. Gartner forecasts that 40% of enterprise applications will embed AI agents by the end of this year, up from just 5% in 2025. But deployment rates don’t tell the full story. The gap between deploying a multimodal model and building a multimodal workflow that actually works in production is where most organizations quietly struggle.
This guide is about that gap — the architectural decisions, the failure modes, the data pipeline realities, and the design patterns that determine whether a multimodal AI project delivers measurable business value or becomes an expensive proof of concept that never escapes the sandbox.
What Multimodal AI Actually Means for Automation (Beyond the Buzzword)
The term “multimodal AI” gets used loosely enough that it’s worth establishing a precise definition — particularly one that’s useful for people building automation systems rather than just experimenting with chatbots.
A multimodal AI system is one that ingests, processes, and reasons across two or more distinct input types — typically some combination of text, images, audio, video, and structured data (like sensor readings, database records, or time-series signals). The key word is simultaneously. A system that processes an image and then separately processes a text description of that same image is not truly multimodal. True multimodality means the model forms a unified internal representation that draws on all inputs together, allowing the signals from one modality to inform interpretation of another.
The Three Dominant Models in 2026
Three models currently dominate enterprise multimodal deployment, each with distinct strengths:
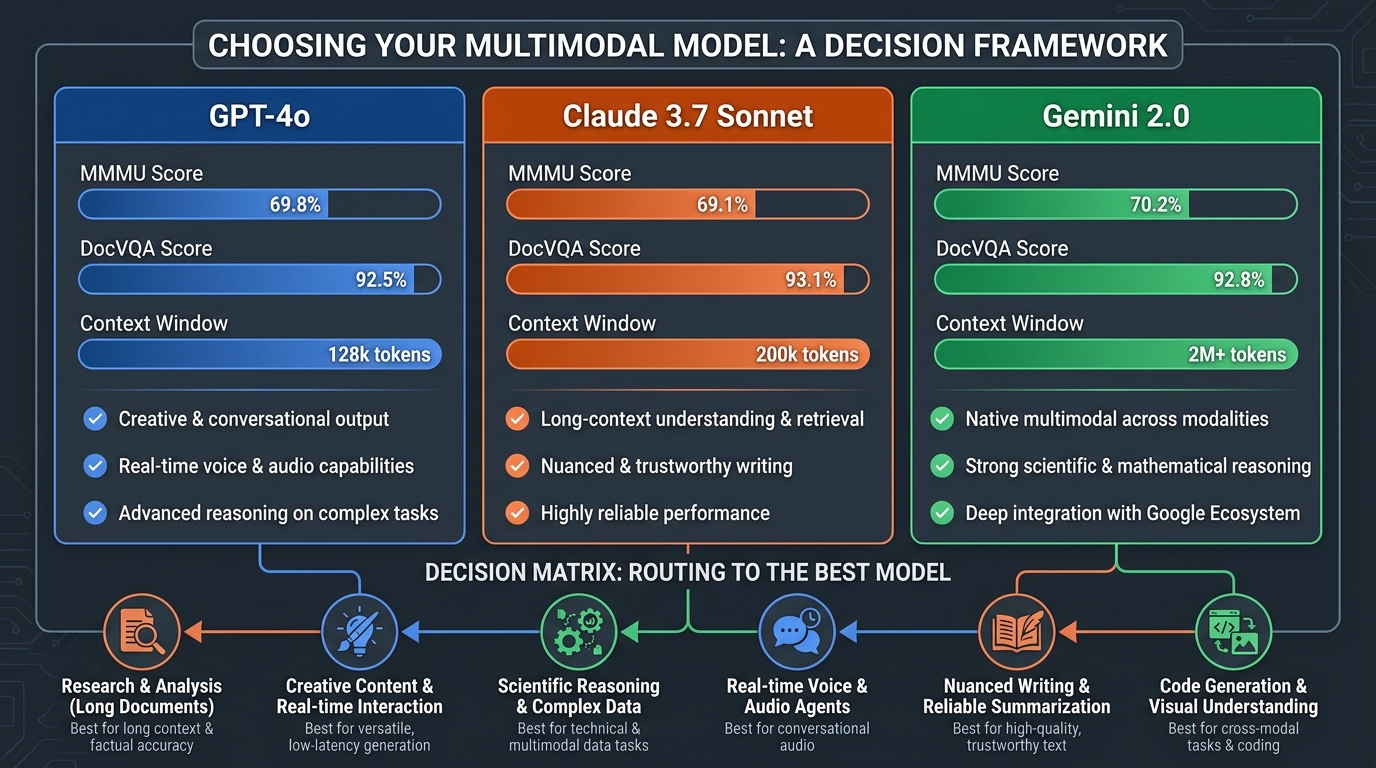
- GPT-4o leads on ecosystem breadth and raw multimodal benchmark performance, scoring 69.1% on the MMMU (Massive Multitask Multimodal Understanding) benchmark and 92.8% on DocVQA (document visual question answering). Its 128K context window and deep integration with Microsoft 365 Copilot make it the default choice for organizations already in the Microsoft stack. Its diagram understanding score of 94.2% on the AI2D benchmark makes it particularly strong for technical document workflows.
- Claude 3.7 Sonnet (and increasingly Claude 4.x in newer deployments) excels on document-heavy, structured-extraction tasks. With a 200K+ context window and a 77.2% SWE-bench score for code-adjacent reasoning, it’s the preferred choice for workflows requiring precision over breadth — legal document analysis, technical specification extraction, compliance audit workflows.
- Gemini 2.0 offers native integration with Google Workspace and Google Cloud infrastructure, with demonstrated efficiency gains of approximately 105 minutes saved per user per week in internal Google studies. For organizations in the Google ecosystem processing high-volume tasks, Gemini’s cost-per-token economics and native tool integration make it the rational default.
Multimodal Models vs. Multimodal Workflows
Here’s the distinction most implementations miss: a multimodal model is a capability. A multimodal workflow is an architectural decision. You can have access to the most capable multimodal model available and still build a workflow that delivers unimodal results — because the workflow was designed to funnel everything into text before passing it to the model.
This is context collapse, and it’s more common than most practitioners will admit. We’ll cover it in detail in the next section. For now, the important frame is this: choosing a model is step five. Designing the data flow, the modality routing, and the fusion strategy is steps one through four.
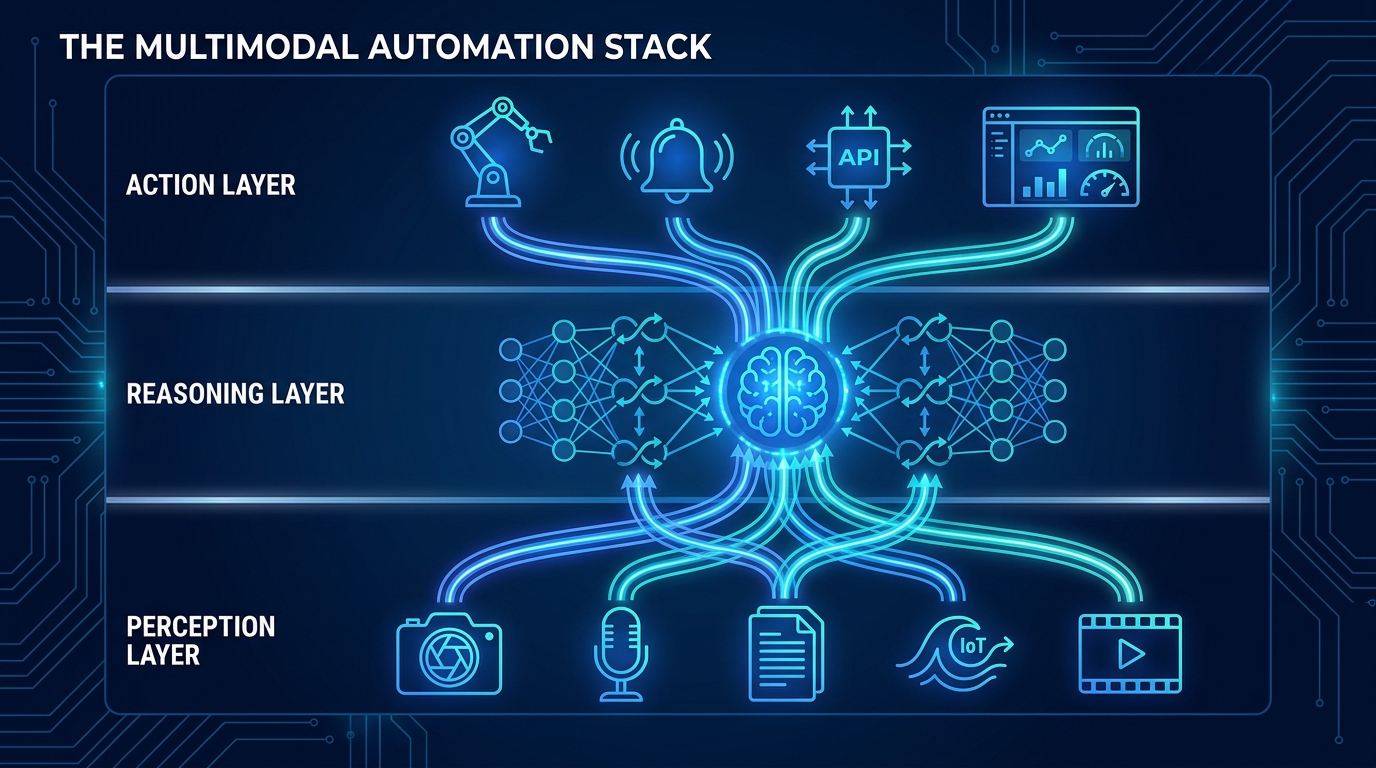
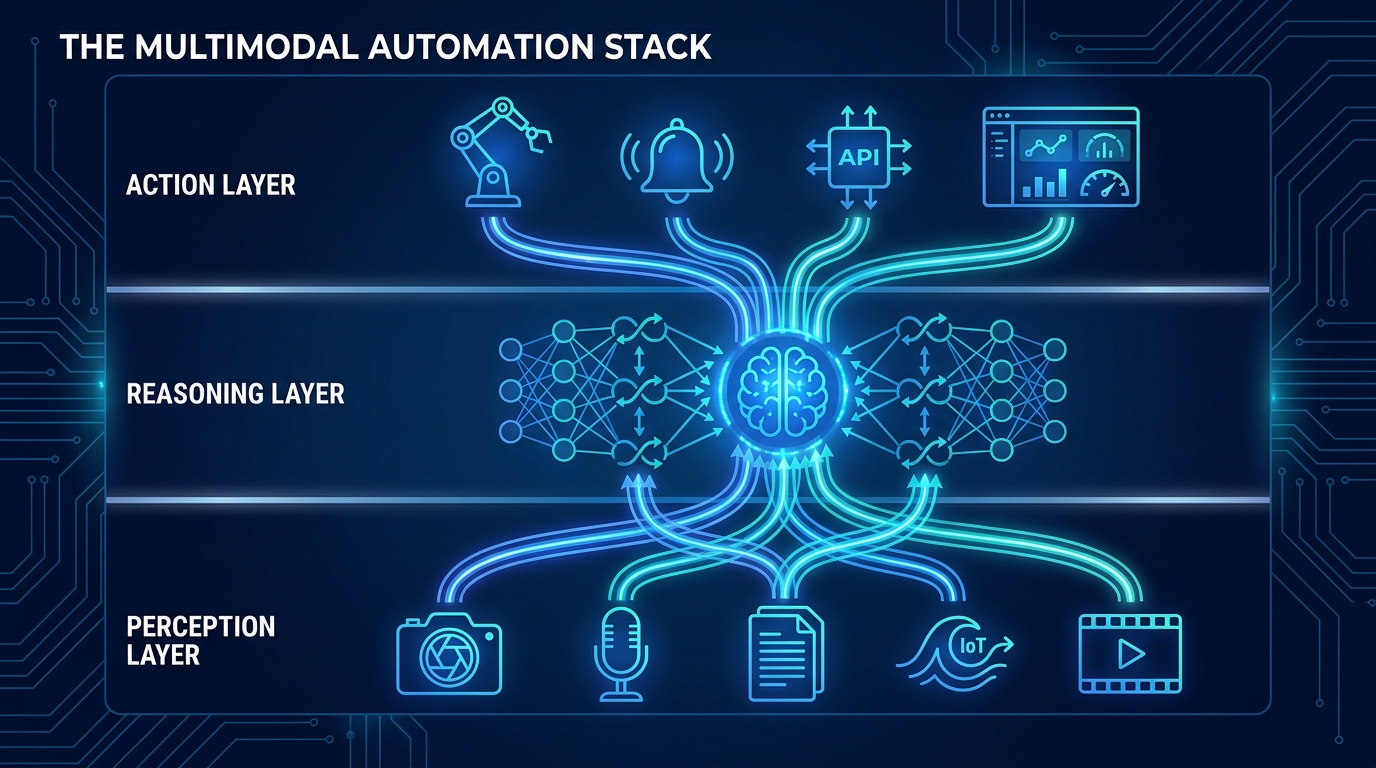
The Three-Layer Architecture Every Multimodal Workflow Needs
Regardless of industry or use case, production-grade multimodal automation systems follow a consistent architectural pattern. Understanding this pattern is prerequisite knowledge before selecting tools, vendors, or models.
Layer 1: The Perception Layer
The perception layer is responsible for ingesting raw inputs from all modalities and transforming them into representations that the reasoning layer can work with. This is not the glamorous part of the stack, but it is where most production failures originate.
In practical terms, the perception layer includes:
- Modality-specific encoders: Separate neural encoding pipelines for visual data (images, video frames), audio (voice, environmental sound), structured data (sensor readings, database records), and text (documents, transcripts, metadata). Each encoder converts raw input into embedding vectors.
- Temporal synchronization: When multiple data streams arrive simultaneously — say, a security camera feed, a microphone input, and sensor readings from the same piece of equipment — they must be aligned in time to sub-millisecond precision. Desynchronization here creates “ghost artifacts” downstream — the model reasons about events that don’t actually co-occur.
- Preprocessing and normalization: Image resolution standardization, audio resampling, text tokenization, and schema validation for structured data. Inconsistent preprocessing is one of the most common sources of modality mismatch errors in production.
- Streaming vs. batch ingestion: Real-time workflows (production line QC, emergency response) require streaming ingestion with Kafka or Flink. Batch workflows (document processing, report generation) can use Apache Spark or simpler ETL pipelines. Choosing the wrong ingestion architecture here locks you into latency characteristics that can’t be easily changed later.
Layer 2: The Reasoning Layer
The reasoning layer is where the multimodal fusion actually happens. Encoder outputs from the perception layer are combined into a unified representation using cross-attention mechanisms — the same transformer-based architecture that allows a model to understand that the cracked surface in an image corresponds to the vibration anomaly in the sensor reading and the “grinding noise” mentioned in the maintenance log.
The reasoning layer also handles:
- Short-term and long-term memory: In agentic systems, the reasoning layer needs access to the current context (what’s happening right now across all input streams) and persistent memory (what happened in prior interactions, prior inspection cycles, prior customer touchpoints). Without this, workflows lose coherence across multi-step tasks.
- Conflict detection: When two modalities give contradictory signals — a quality control image shows a perfect product while a sensor reading indicates a thermal anomaly — the reasoning layer must flag this conflict rather than arbitrarily resolving it. Systems that silently resolve contradictions produce confident wrong answers.
- Fusion strategy selection: Not all fusion happens the same way. Early fusion combines raw inputs before encoding (best for tightly correlated signals like video + audio). Late fusion combines encoded representations after each modality is independently processed (better when modalities have different reliability levels). Hybrid fusion uses early fusion for some pairs and late fusion for others. Production systems that apply one fusion strategy uniformly across all use cases consistently underperform.
Layer 3: The Action Layer
The action layer translates reasoning-layer outputs into concrete workflow steps: API calls to downstream systems, database writes, alerts, approval requests, generated documents, or commands to physical systems like robotic actuators.
The critical design consideration at this layer is output format fidelity. The reasoning layer may generate rich, nuanced conclusions. If the action layer only supports a binary approve/reject output to a downstream ERP system, that nuance is lost. Action layer design should work backwards from what downstream systems can actually consume — not forwards from what the model can theoretically produce.
Where Multimodal Workflows Break: The Three Failure Modes

Understanding how multimodal workflows fail is as important as understanding how they succeed. Three failure modes account for the majority of production breakdowns, and all three are architectural — not model — problems.
Failure Mode 1: Context Collapse
Context collapse happens when a workflow converts rich multimodal inputs into text before passing them to the model. An engineer receives a PDF with embedded charts, screenshots, and tabular data. Instead of letting the model process the visual elements natively, the pipeline runs OCR on the document, converts everything to text, and sends that text to the LLM. The chart data becomes garbled ASCII approximations. The spatial relationships in tables are destroyed. The model reasons about a degraded representation of the original information.
Context collapse is insidious because it doesn’t cause obvious errors — it causes subtle accuracy degradation that’s hard to attribute to a root cause. Systems affected by context collapse will work well enough to pass initial testing but underperform at scale on edge cases that depend on visual or structural nuance.
The fix is upstream: redesign the ingestion pipeline to preserve modality-native representations and pass them directly to a model capable of processing them without text conversion. This requires a perception layer built with native multimodal handling — not retrofitted OCR.
Failure Mode 2: Modality Mismatch
Modality mismatch occurs when different data streams about the same event are misaligned — either temporally (captured at different times) or semantically (described using different schemas or classification systems).
A concrete example: a logistics company deploys a workflow that cross-references delivery video footage with the corresponding delivery confirmation form. The footage uses a timestamp from the camera’s local clock; the form uses a server-side timestamp from the delivery management system. A two-minute drift between these clocks means the system consistently correlates the wrong footage with the wrong form — an error that produces plausible-looking but incorrect outputs.
More subtle mismatch occurs with semantic schema drift: an image classifier that labels damaged packaging as “condition: poor” while the warehouse management system uses a three-tier scale of “acceptable / marginal / reject.” If the middleware mapping between these schemas is inconsistent, the multimodal fusion layer works with incommensurable inputs.
The fix requires building explicit synchronization and schema validation into the perception layer, not assuming that data from different systems will naturally align. Sub-millisecond timestamp precision standards need to be enforced at ingestion, and semantic mappings need to be version-controlled and audited.
Failure Mode 3: Fusion Failure
Fusion failure happens when the integration architecture between modalities is too simple for the complexity of the relationship between them. The most common manifestation: treating modality fusion as a simple concatenation — appending image embeddings to text embeddings and hoping the model figures out the relationship.
Cross-attention fusion, by contrast, allows each modality’s representation to actively query and attend to features in other modalities — enabling genuinely joint reasoning rather than parallel processing with a naive merge at the end. Systems that use concatenation-style fusion consistently underperform on tasks requiring cross-modal reasoning, which is most of the interesting cases.
Fusion failure is also common when organizations use a single fusion strategy for all use cases. An early-fusion architecture works well for video + audio synchronization but poorly for text + image when the image and text are about the same topic but arrive at different times and reliability levels. Building a monolithic fusion layer is an architectural bet that rarely pays off at scale.
Choosing Your Modality Stack: A Practical Decision Framework
Model selection is not a one-time decision. In 2026, the most sophisticated multimodal workflows use model routing — dynamically selecting different models depending on the type of input, the required output precision, and the acceptable cost envelope for that specific task. Single-model architectures are increasingly a liability rather than a simplification.
The Task-Specificity Principle
No single model leads universally on all multimodal tasks. GPT-4o’s 94.2% score on diagram understanding makes it the clear choice for engineering drawing analysis, but Claude’s superior performance on structured document extraction and long-context reasoning makes it a better fit for legal review workflows processing dense contracts with embedded tables and cross-references.
Before selecting a model, audit your workflow’s task distribution:
- High-volume, low-complexity tasks (document classification, simple image tagging): Favor cheaper, faster models. Gemini 2.0 Flash or GPT-4o mini deliver acceptable accuracy at significantly lower cost-per-token.
- Moderate complexity, mixed-modality tasks (customer complaint triage combining text, image, and transaction history): GPT-4o’s broad ecosystem integration makes it the pragmatic choice.
- High-precision, document-heavy tasks (compliance auditing, legal review, technical specification extraction): Claude’s 200K context window and precision-first architecture outperforms alternatives in benchmark and production settings.
- High-volume Google ecosystem tasks (Gmail processing, Google Docs summarization, Google Cloud data pipelines): Gemini’s native integration removes an entire infrastructure layer and reduces both latency and cost.
Building a Multi-Model Router
Platforms like Clarifai, LiteLLM, and custom orchestration layers built on LangGraph or CrewAI are enabling multi-model routing in production. The router receives an incoming task, classifies it by modality mix and complexity, and dispatches to the appropriate model. This pattern achieves two things simultaneously: it reduces cost (routing simple tasks to cheaper models) and improves accuracy (routing complex tasks to more capable ones).
The practical catch: multi-model routing introduces latency at the classification step and requires that each model’s output format be normalized by a reconciliation layer before downstream consumption. Factor both costs into your architecture before committing.
Build vs. Buy: The Vendor Lock-In Reality
Every major cloud provider now offers managed multimodal AI services: Azure AI (GPT-4o via Azure OpenAI), Google Cloud Vertex AI (Gemini), AWS Bedrock (Claude, plus others). These managed services reduce infrastructure overhead dramatically — but they also create lock-in that becomes painful when a competitor model leapfrogs your vendor’s offering.
The hedge: architect your perception and action layers to be model-agnostic from the start, even if you’re deploying with a single vendor initially. The reasoning layer integration points should abstract away model-specific APIs so that swapping the underlying model doesn’t require rebuilding the entire workflow.
Building the Data Pipeline: The Unglamorous Part That Determines Everything
Multimodal AI pipelines fail at the data layer far more often than at the model layer. The model is the least likely component to be the bottleneck. The data pipeline — how data is ingested, stored, preprocessed, and served to the model — is where most production-grade multimodal workflows encounter their worst problems.
Storage Architecture for Mixed Modalities
Different modality types have fundamentally different storage requirements:
- Images and video live best in object storage (S3, Azure Blob, Google Cloud Storage). High-resolution images are large; storing them in relational databases kills performance.
- Audio is similar to video — object storage with metadata in a relational or NoSQL layer for queryability.
- Time-series sensor data requires purpose-built time-series databases (InfluxDB, TimescaleDB) for efficient range queries at scale.
- Text and structured data fit traditional relational or document databases, but unstructured text for retrieval augmentation needs vector storage (Pinecone, Weaviate, pgvector, or Databricks Mosaic AI Vector Search).
- Embeddings — the vector representations that the model produces during processing — need their own vector index, updated continuously as new data arrives.
Multimodal workflows that try to fit all modalities into a single storage system consistently underperform. The data engineering overhead of purpose-built storage per modality type is not optional complexity — it’s the baseline infrastructure that makes everything else work.
Handling Noisy and Missing Data
In real-world production environments, inputs are never clean. Cameras go offline. Sensors malfunction. Documents arrive with missing pages. Audio has background noise that degrades transcription quality. Multimodal workflows that aren’t designed for graceful modality degradation will fail in production in ways they never encountered in testing — because test data is almost always cleaner than production data.
The engineering principle here is called Missing Modality Robust Learning (MMRL). The practical implementation: for every workflow, explicitly design the fallback behavior when each modality is unavailable. What happens if the image is missing? If the audio transcription confidence score falls below threshold? If the sensor data stream drops? Systems with explicit degradation policies surface these events cleanly — routing to human review — rather than silently producing low-confidence outputs that downstream systems treat as reliable.
Observability: You Cannot Fix What You Cannot See
Multimodal pipelines need observability instrumentation at every layer — not just at the final output. At minimum, track:
- Ingestion completeness by modality (what percentage of expected inputs actually arrived?)
- Preprocessing error rates by modality and data source
- Model confidence scores per output, tagged by input modality mix
- Latency percentiles at each layer (p50, p95, p99)
- Downstream system integration error rates
Prometheus/Grafana stacks work well for operational metrics. For AI-specific observability — tracking confidence distributions, detecting model drift, flagging unusual input patterns — purpose-built tools like Arize AI, WhyLabs, or Evidently AI add the layer that general infrastructure monitoring tools miss.
Human-in-the-Loop Design: When to Trust the Machine
The question of when a multimodal AI workflow should execute autonomously and when it should escalate to human review is not a philosophical debate — it’s a design decision that should be made explicitly, documented, and version-controlled. Most production failures in agentic AI systems trace back to this decision being left implicit.
The Three Oversight Models
There are three established oversight architectures for production AI systems, and each is appropriate for different risk profiles:
- Human-in-the-Loop (HITL): A human approves every consequential decision before execution. Appropriate for high-stakes, low-volume workflows — regulatory filings, medical diagnosis support, financial fraud determinations. HITL provides maximum oversight but doesn’t scale to high-volume automation.
- Human-on-the-Loop (HOTL): The AI executes autonomously but all decisions are logged and surfaced for periodic human review. Appropriate for moderate-risk, high-volume workflows — procurement approvals within pre-approved budget ranges, customer tier classification, content moderation decisions with appeal pathways.
- Human-in-Command (HIC): The AI operates fully autonomously, with humans retaining only the ability to override or shut down. Appropriate only for low-risk, highly structured workflows with tight operational guardrails and extensive prior validation data.
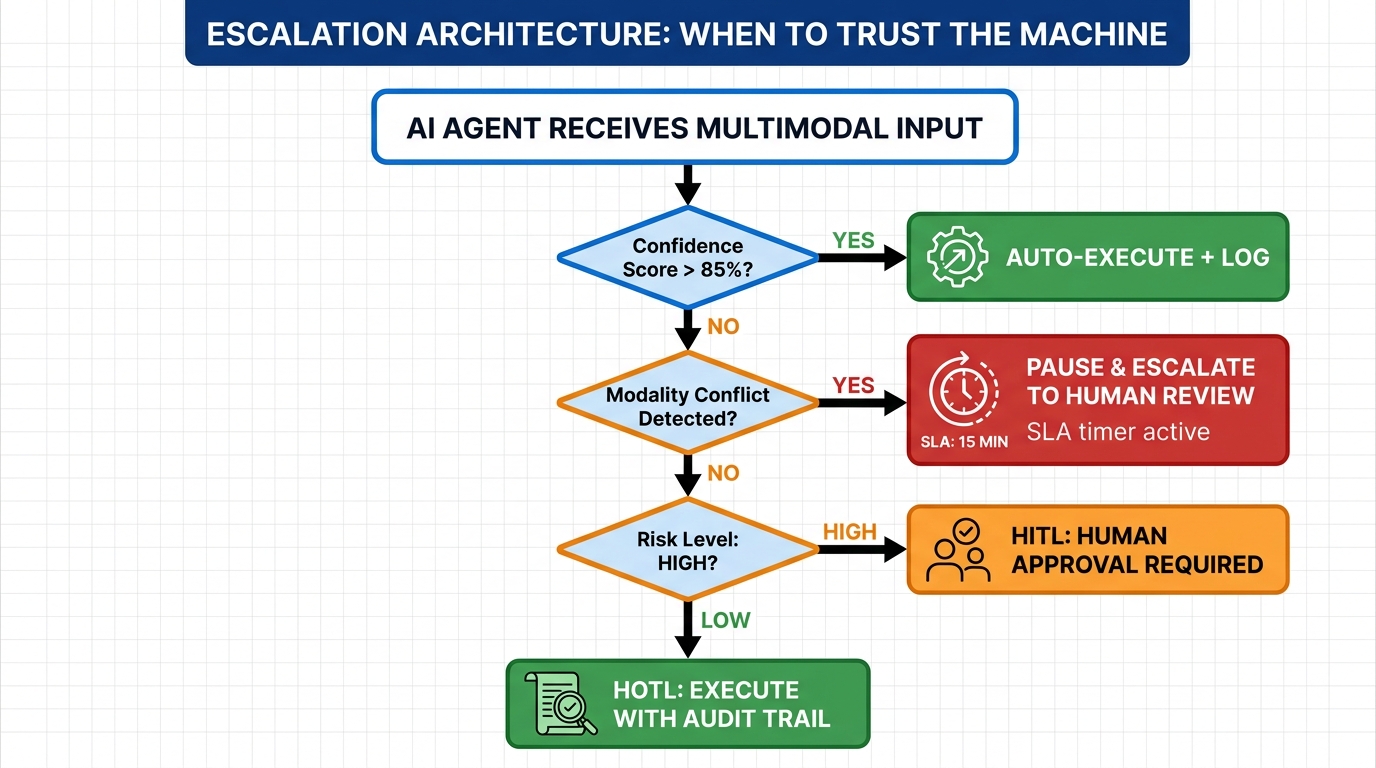
Confidence Thresholds and Auto-Escalation
The practical implementation of any oversight model depends on a confidence threshold system. The most common pattern: model outputs include a confidence score (or can be prompted to generate one). Outputs above an 85% confidence threshold proceed autonomously; outputs below this threshold trigger escalation. The threshold should be calibrated per use case and per modality mix — a workflow processing clean, high-resolution images from a controlled factory environment can use a higher confidence threshold than one processing variable-quality customer-submitted photos.
Beyond confidence scores, explicit escalation triggers should include:
- Modality conflict: When different input modalities suggest contradictory conclusions (the image looks fine but the sensor anomaly is severe), escalate regardless of confidence score.
- Out-of-distribution inputs: When the input characteristics fall outside the distribution of training or validation data, the model’s confidence score may be unreliable even when it appears high.
- High-consequence action scope: Any action that crosses a pre-defined consequence threshold (financial value, irreversibility, regulatory exposure) should require human approval regardless of model confidence.
Governance-as-Code and Regulatory Compliance
The EU AI Act entered full applicability in August 2026, with fines of up to €40 million or 7% of global turnover for violations involving high-risk AI systems. Multimodal AI workflows processing health data, making decisions affecting employment, or operating in critical infrastructure are explicitly classified as high-risk under this framework.
The operational response is governance-as-code: encoding decision rules, escalation thresholds, audit requirements, and human review protocols directly into the workflow infrastructure — not into policy documents that nobody reads. Tools like OPA (Open Policy Agent) and enterprise-grade MLOps platforms (MLflow with governance extensions, SageMaker Clarify, Vertex AI Model Registry) enable this. The audit trail isn’t a report generated quarterly — it’s a live, queryable log of every decision, with the input that produced it and the human override status.
Industry-Specific Workflow Blueprints
The three-layer architecture applies universally, but the specific modality combinations, fusion strategies, and escalation protocols differ substantially by industry. Here are three production-relevant blueprints based on documented deployments.
Manufacturing: The Closed-Loop Quality Workflow
Modalities involved: visual (camera images of components), acoustic (vibration/sound sensors on machinery), and textual (maintenance logs, specification documents).
The workflow: Components pass a camera array. Computer vision encoders detect surface defects, dimensional deviations, and color anomalies. Simultaneously, acoustic sensors on the production machinery capture vibration signatures that correlate with tool wear. The reasoning layer fuses visual inspection results with acoustic anomaly scores and cross-references both against maintenance log records documenting recent tool changes. A defect flagged by vision alone gets compared against whether the acoustic signature changed at the same time a tool was replaced — allowing the system to distinguish between a machine problem and a batch-specific material issue.
Results from documented deployments: visual inspection alone achieves 70–80% defect detection accuracy. Fusing vision with acoustic and maintenance log data pushes this above 95%, while reducing false positives by 40–60%. Siemens’ AI-powered production workflow delivered a 15% reduction in production time and a 99.5% on-time delivery rate. Predictive maintenance applications in manufacturing have documented 300–500% ROI over three-year periods, with 35–45% reductions in unplanned downtime.
Healthcare: The Clinical Decision Support Workflow
Modalities involved: medical imaging (X-rays, MRI, CT), electronic health records (structured text), and clinical notes (unstructured text, sometimes dictated audio converted to text).
The workflow: An incoming patient encounter triggers ingestion of all available modalities — current imaging, historical imaging for comparison, structured EHR data (lab values, medication list, vital signs), and physician voice-dictated notes. The reasoning layer fuses these signals to surface relevant findings, flag contradictions between modalities (an image finding inconsistent with the documented symptom history), and generate a structured summary for the reviewing clinician. The system operates in HITL mode: it generates recommendations but the clinician makes and documents all final decisions.
The modality alignment challenge here is acute: imaging timestamps often reflect scan acquisition time while EHR records use documentation timestamps, and the drift between them can be clinically significant. Healthcare multimodal deployments that solve this alignment problem have demonstrated meaningful diagnostic accuracy improvements and significant reductions in the time physicians spend on chart review before patient encounters.
Logistics: The Intelligent Parcel Workflow
Modalities involved: video (facility cameras, delivery cameras), GPS/location data (structured), and document images (shipping labels, customs forms, invoices).
The workflow: As parcels move through a logistics facility, video feeds track package handling and condition. OCR-multimodal models process shipping label images — not just reading text, but interpreting label damage, barcode obscuring, and weight sticker placement. GPS streams provide location context. When a package arrives at a customs checkpoint, the system fuses the physical condition assessment from video with the declared value from the invoice document image and the route history from GPS — identifying discrepancies that warrant further inspection.
UPS’s ORION routing system, which uses multimodal optimization combining route data, delivery instructions, and real-time constraints, saves over $400 million annually. DHL’s warehouse AI deployment achieved a 30% efficiency improvement. Protex AI’s deployment of visual multimodal AI across 100+ industrial sites and 1,000+ CCTV cameras achieved 80%+ incident reductions for clients including Amazon, DHL, and General Motors — demonstrating that edge-scale multimodal deployment is operational today.
The ROI Reality Check: Numbers Worth Actually Tracking

ROI ranges for multimodal AI implementations are real but heavily deployment-specific. The numbers that get cited in vendor materials represent best-case outcomes in well-executed, mature deployments — not what a first implementation will deliver in year one.
What the Numbers Actually Represent
- Predictive maintenance: 300–500% ROI over three years, with 5–10% reduction in maintenance costs and 30–50% reduction in unplanned downtime. These numbers assume the baseline is reactive maintenance with high unplanned outage costs. Organizations with already-mature preventive maintenance programs will see a smaller delta.
- Visual quality control: 200–300% ROI, with accuracy improvements from 70–80% (manual inspection) to 97–99% (AI-assisted inspection). The ROI calculation includes the cost reduction from catching defects earlier in the production cycle, not just the accuracy improvement itself.
- Logistics and supply chain optimization: 150–457% ROI over three years, depending on starting state. 20–50% inventory reduction and 30–50% throughput improvements are achievable — but only after the data pipeline and integration work is complete, which takes meaningful time and upfront investment.
The Hidden Costs Most ROI Models Ignore
Standard ROI models for AI automation typically account for model licensing costs and some implementation labor. They systematically underestimate:
- Data pipeline infrastructure: Purpose-built storage per modality, streaming ingestion infrastructure, real-time synchronization systems. For large deployments, this infrastructure can exceed model licensing costs by 2–3×.
- Human review labor during calibration: HITL workflows during the initial deployment period require significant human review time to generate the labeled data that calibrates confidence thresholds. This is a real labor cost that typically isn’t in the initial business case.
- Observability tooling: AI-specific monitoring, model drift detection, confidence score dashboards. These are ongoing operational costs, not one-time implementation costs.
- Retraining cycles: Production environments change. Camera angles shift, sensor calibration drifts, document formats evolve. Models need periodic retraining to maintain performance, which carries both compute cost and engineering labor cost implications.
Payback Period Reality
Documented payback periods for well-executed multimodal AI deployments range from 3–12 months for narrow, well-defined use cases (a single quality inspection station, a specific document processing workflow) to 18–36 months for enterprise-wide, multi-department deployments. Projects that try to boil the ocean — implementing multimodal AI across five departments simultaneously — consistently run longer, cost more, and deliver the worst unit economics. The fastest payback comes from targeting the single workflow with the highest combination of current error rate, high consequence per error, and high volume of decisions.
From Pilot to Production: The 5 Decisions That Determine Success
Most multimodal AI pilots succeed. Most multimodal AI production deployments disappoint. The gap is not technical — it’s architectural and organizational. Five decisions, made explicitly at the right time, separate the projects that scale from the ones that stay in pilot indefinitely.
Decision 1: Define Data Governance Before Selecting Models
Data governance decisions — who owns each modality’s data, what access controls apply, how long data is retained, what privacy requirements govern processing — constrain your architectural choices more than model capabilities do. A healthcare workflow that cannot retain patient images for model training due to HIPAA requirements needs a fundamentally different architecture than one where retention is unrestricted. Making governance decisions after model selection leads to expensive rearchitecting.
Decision 2: Build the Observability Stack Before Going Live
Organizations that go live without observability instrumentation spend their first six months in production debugging blindly. Every multimodal workflow needs per-modality confidence tracking, input quality monitoring, and downstream accuracy validation before the first production decision is made — not after you notice something is wrong.
Decision 3: Test Modality Degradation, Not Just Happy-Path Performance
Production testing of multimodal systems should include systematic degradation testing: What happens when image quality drops? When audio has significant background noise? When 20% of sensor readings are missing? Systems that perform well only on clean inputs are not production-ready, regardless of how impressive their benchmark scores are on curated test sets.
Decision 4: Map Skill Gaps Before Committing to Architecture
Multimodal AI workflows require a broader skill set than text-only AI implementations. Specifically: computer vision engineering (distinct from NLP), signal processing for audio and sensor data, data pipeline engineering for mixed-modality storage, and MLOps practitioners familiar with multi-model routing. Organizations that commit to architectures requiring skills they don’t have — or plan to hire for after implementation begins — consistently miss timelines and budgets.
Decision 5: Negotiate Model-Agnostic Contracts
The multimodal AI landscape is moving faster than most enterprise procurement cycles. A model that leads benchmarks today may be two generations behind in 18 months. Contracts with cloud providers and AI vendors should include explicit provisions for model swapping, exit data portability, and inference cost renegotiation triggers. This is not standard in vendor-proposed terms — it requires deliberate negotiation.
What’s Next: Edge Deployment and Real-Time Multimodal Agents

Two developments will define the next phase of multimodal AI in automation workflows: edge deployment and autonomous multi-agent orchestration. Both are moving from planning-stage concepts to production-scale reality faster than most enterprise roadmaps anticipated.
Edge Inference: Bringing Multimodal AI to the Data Source
The current dominant pattern — cloud-based inference for most enterprise multimodal AI — has latency limitations that make it unsuitable for real-time physical processes. A manufacturing quality control system that takes 800ms to get a cloud inference result cannot run on a production line moving at 120 components per minute. Edge deployment — running multimodal inference directly on hardware at the data source — eliminates this constraint.
Edge deployment in 2026 is enabled by a new generation of purpose-built edge AI hardware (NVIDIA Jetson Orin, Qualcomm Cloud AI 100) and by model distillation techniques that compress larger multimodal models into smaller versions that run efficiently on constrained hardware without catastrophic accuracy loss. The tradeoff: edge-deployed models update less frequently, require more careful hardware lifecycle management, and have constrained context windows compared to cloud-based counterparts.
Protex AI’s deployment of visual multimodal AI across 100+ industrial sites and 1,000+ CCTV cameras — achieving 80%+ incident reductions for clients including Amazon, DHL, and General Motors — demonstrates that edge-scale multimodal deployment is not a future concept. It is operational infrastructure today.
Autonomous Multi-Agent Orchestration
The next architectural evolution is multi-agent systems where specialized agents — each optimized for a specific modality or task — collaborate autonomously on complex workflows. An orchestrator agent receives a high-level task (audit this facility’s safety compliance from last week’s camera footage and incident reports). It decomposes the task and dispatches to a vision agent (process video footage), a document agent (extract data from incident report PDFs), and a reasoning agent (synthesize findings into a structured compliance report). The orchestrator manages sequencing, handles agent failures, and determines when human escalation is needed.
Current data suggests that multi-agent systems achieve 45% faster problem resolution and 60% more accurate outcomes compared to single-agent architectures. However, fewer than 10% of enterprises that start with single agents successfully implement multi-agent orchestration within two years. The prerequisite is organizational and operational maturity, not just technical capability. Attempting multi-agent orchestration before individual agents are stable and well-monitored in production is one of the most reliable ways to make a complex system dramatically more complex to debug.
Building Workflows That Actually Perceive
The organizations getting disproportionate returns from multimodal AI in 2026 share a specific characteristic: they designed their workflows around the full signal of the problem — not just the part that was easy to digitize first.
Text was the first modality to be fully digested by AI automation. It was accessible, and the returns from text-only automation were real. But the real world is not a text file. It is a simultaneous stream of visual information, acoustic cues, sensor readings, spatial coordinates, and natural language — and the most consequential decisions in operations, healthcare, logistics, and manufacturing depend on reasoning across that full signal.
Multimodal AI workflows are the architectural response to that reality. But the implementation details are where these projects succeed or fail. Getting the perception layer right — preserving modality-native signals instead of collapsing them into text. Building fusion architectures that reflect actual signal relationships rather than applying a universal strategy. Designing escalation logic that is explicit, version-controlled, and calibrated to actual risk levels. Running the data pipeline with purpose-built infrastructure for each modality type. Testing for degradation, not just clean-data performance.
None of this is glamorous. All of it is what separates a multimodal AI workflow that works in production from one that works impressively in a controlled demo and quietly underperforms in the real world.
Key Takeaways for Practitioners
- Design your workflow architecture before selecting models. The modality stack, fusion strategy, and escalation logic are more consequential than which underlying model you use.
- Build purpose-built storage infrastructure for each modality type. Trying to fit images, audio, time-series data, and text into a single storage system is a consistent source of production failure at scale.
- Test for modality degradation systematically. Production data is dirtier than test data. Workflows that aren’t built for graceful degradation will fail on the cases that matter most.
- Negotiate model-agnostic contracts with vendors. The multimodal model landscape is moving faster than procurement cycles. Lock-in that feels manageable today will feel expensive in 18 months.
- Target the single highest-value workflow for your first deployment. Fastest payback, clearest learning, and organizational proof-of-concept all favor narrow-then-scale over wide-then-optimize.
- Implement governance-as-code before going live. The EU AI Act’s full applicability in August 2026 makes this a legal requirement for high-risk systems — but it’s sound engineering practice regardless of regulatory jurisdiction.
Leave a Reply