There is a version of ChatGPT Connectors that gets talked about in press releases — a polished story about AI unifying your entire stack, eliminating app-switching, and turning natural language into cross-platform action. Then there is the version that teams are actually using week to week in 2026: messier, more specific, and genuinely more interesting.
The reality is that Connectors have quietly moved from a novelty to a production layer for a growing slice of knowledge workers. The shift did not happen in a single feature drop. It accumulated — through better deep research integration, the slow expansion of write actions, and the Model Context Protocol (MCP) giving enterprise teams a path to build connectors that can actually touch their own internal systems in ways the native integrations cannot.
This post is not an explainer on what Connectors are. It is a ground-level account of what is working right now, for which teams, under what conditions, and where the real friction points still live. If you are trying to figure out whether to build or expand a Connectors-based workflow in the next 30 days, this is the article you need to read first.
We will cover the ecosystem in its current state, the underused combination of Deep Research mode with live connectors, the write actions that finally give the platform some teeth, the MCP architecture layer for teams that need to go beyond native integrations, and the honest limitations that trip up otherwise well-designed workflows. We will also spend time on the governance question — because what data your connected apps expose depends heavily on which plan you are running, and that distinction matters far more than most teams realise until something goes wrong.
The Connector Ecosystem at Mid-2026: What 500+ Apps Actually Means in Practice
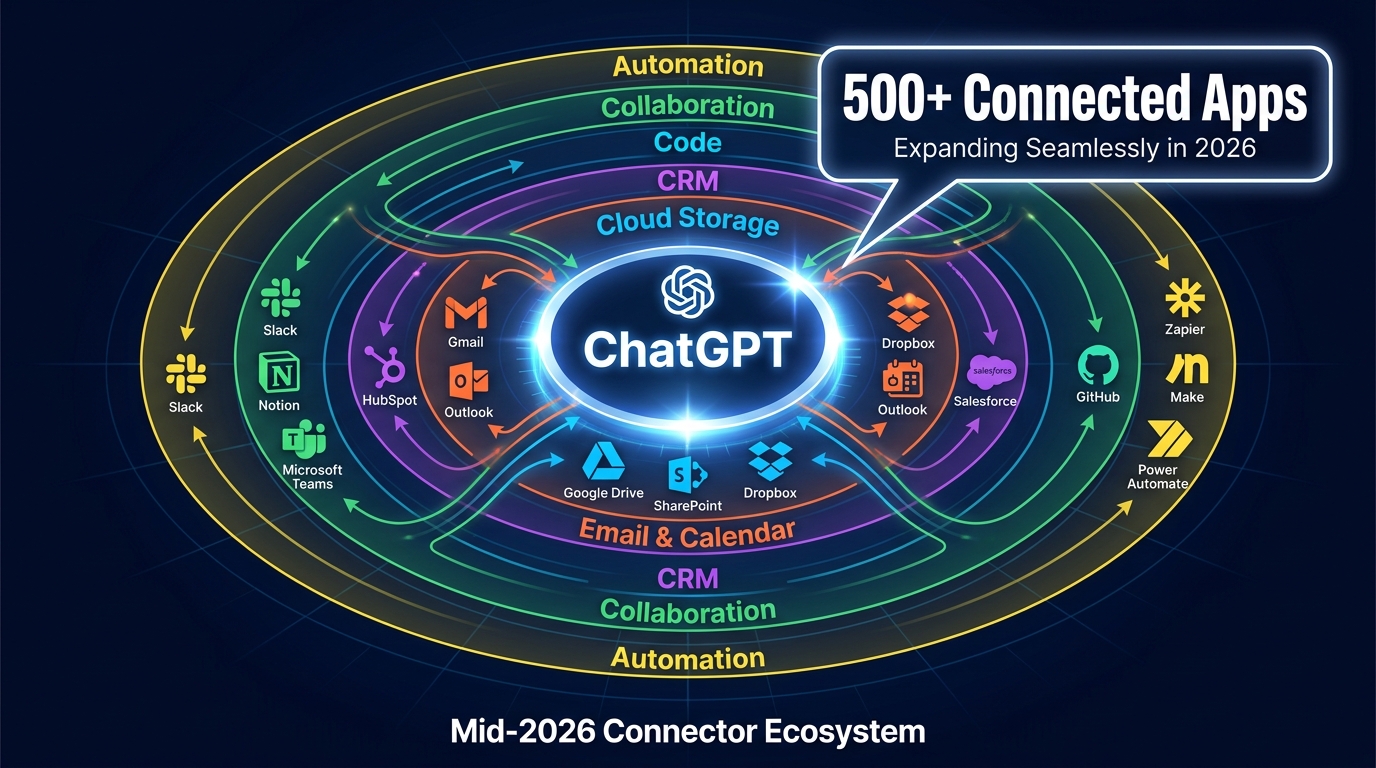
OpenAI’s connector count crossed 500 integrated applications for ChatGPT 5, spanning cloud storage, email, calendars, CRMs, code repositories, and automation platforms. That headline figure is accurate, but it requires some unpacking before it translates into workflow strategy.
Coverage is Uneven by Design
The most battle-tested connectors — the ones that have been in production the longest and carry the fewest edge-case surprises — cluster in a predictable group: Google Workspace (Drive, Gmail, Calendar, Docs), Microsoft 365 (SharePoint, OneDrive, Outlook, Teams), GitHub, Slack, and Notion. These cover the daily surfaces where most knowledge work actually happens, and they are the connectors where the deep research integration and sync/indexing features are most mature.
CRM connectors occupy a different tier. HubSpot is listed as a native built-in CRM connector in ChatGPT Enterprise’s framework, and it works well for retrieval — pulling contact records, deal stages, and activity history into a chat context without leaving the interface. Salesforce access, by contrast, tends to run through MCP-based or third-party bridges rather than a fully native connector, which changes the setup complexity significantly. If your RevOps team is planning Salesforce workflows assuming native connector simplicity, that gap will surface early.
The automation platform integrations — Zapier, Make, Microsoft Power Automate — sit in a third category. These are less about data retrieval and more about triggering. When you connect ChatGPT to Zapier, you are not just reading from Zapier; you are using ChatGPT as the reasoning layer that decides what Zapier should execute. This distinction between ChatGPT as a retrieval tool versus ChatGPT as an orchestration layer is the most important conceptual shift for teams designing their first serious connector workflows.
Search vs. Sync: Two Modes That Teams Confuse
There are two fundamentally different ways ChatGPT can interact with a connected app: real-time search and pre-synced indexed knowledge. Real-time search pulls current data from the connected app at query time — it is slower and depends on live API access, but the data is always fresh. Pre-synced indexed knowledge uploads a snapshot of your connected content (documents, wikis, knowledge bases) and lets ChatGPT query that index instantly without hitting the live API on every request.
The choice between these two modes matters for both performance and data freshness. Teams building customer support workflows typically want real-time search so agents always get current ticket status and contact data. Teams building research workflows or internal knowledge assistants often prefer indexed sync for speed, accepting that the data might be hours or days old depending on their sync schedule.
Getting this wrong — expecting indexed freshness when you have set up real-time search, or expecting live pricing data when you are querying a weekly sync — is one of the most common causes of early frustration with Connectors. It is not a product failure; it is a configuration decision that needs to be deliberate.
Plan Availability Shapes What You Can Actually Build
Not all features are available on all plans. The full connector suite, write actions, and MCP custom connector support are concentrated in ChatGPT Team, Business, Enterprise, and Edu plans. Free and Plus users have access to a narrower set of connectors with more restricted capabilities. If you are evaluating Connectors for a team deployment, the feature-to-plan mapping is worth auditing before you build any workflow assumptions around capabilities that may not be available at your current tier.
Deep Research Mode + Connectors: The Combination Most Teams Are Leaving on the Table

ChatGPT’s Deep Research mode was designed to conduct extended, multi-source research tasks autonomously. When it launched, the primary use case was web-based — pulling together publicly available information on a topic, synthesising it into a structured report, and surfacing citations. That was useful. What is significantly more useful, and less discussed, is running Deep Research across your own connected data.
What Happens When Deep Research Hits Internal Data Sources
When you activate Deep Research mode with connectors enabled — particularly Google Drive, SharePoint, or a Notion workspace — the model does not just search one source. It can be instructed to pull from multiple connected repositories simultaneously, cross-reference findings, and synthesise a coherent output that would have required an analyst several hours to assemble manually.
The practical example that illustrates this well is competitive intelligence preparation. A team preparing for a quarterly business review might need to compile: recent customer feedback from a Notion CRM notes database, product development updates from GitHub commit summaries, and sales deal notes from HubSpot. Before connected Deep Research, that synthesis meant three separate logins, manual copy-paste into a document, and then a drafting session. With connectors configured and Deep Research prompted correctly, a single well-structured query can pull from all three sources and return a formatted briefing document in the time it used to take just to open the tabs.
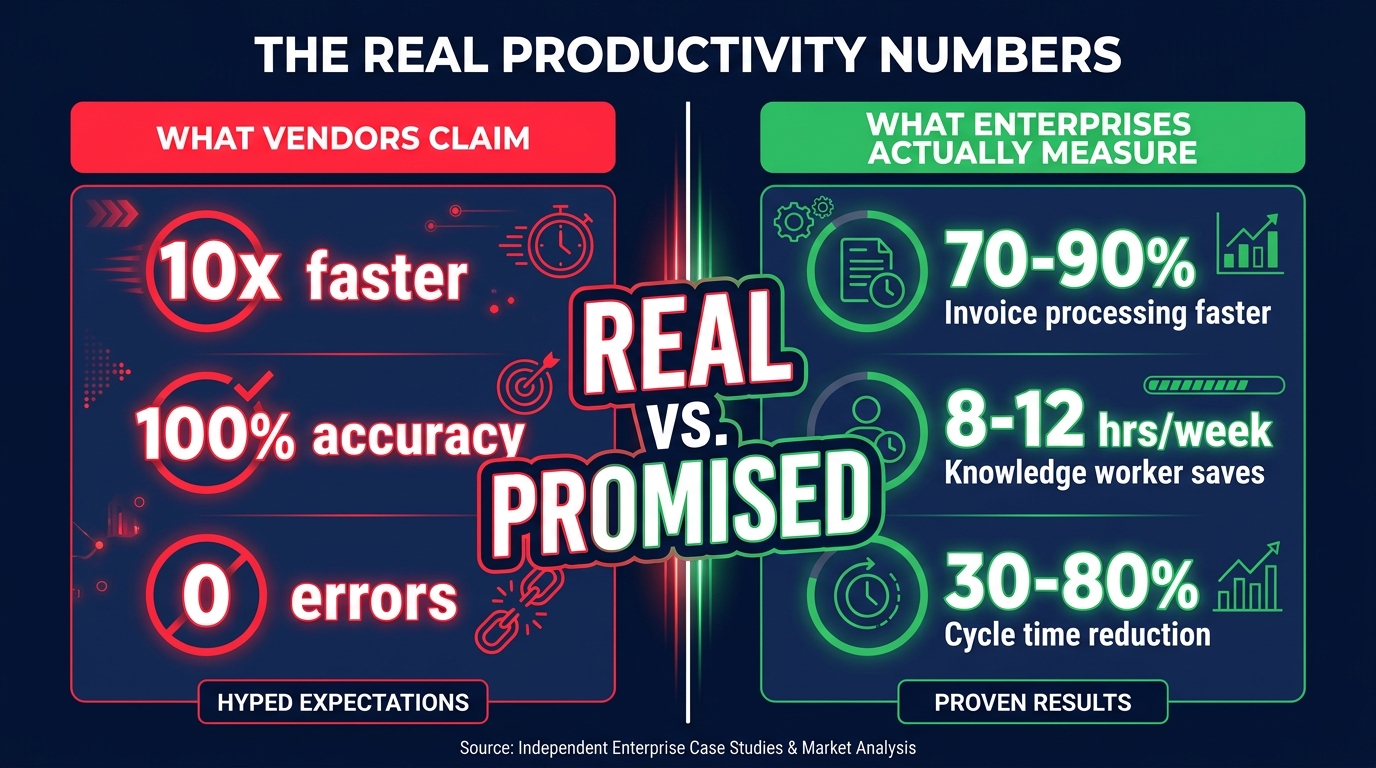
Teams running this pattern consistently report time savings in the range of 40 to 60 minutes per worker per day on research-heavy tasks. That figure comes from OpenAI’s own enterprise productivity data and is consistent with independent analyst estimates. On a ten-person team doing daily research tasks, that is the equivalent of recovering a full-time employee’s working hours every week — without headcount change.
The Prompt Architecture That Makes It Work
Deep Research across connectors does not work as well with vague prompts as it does with scoped, structured ones. The prompts that produce the most consistent results tend to follow a pattern: specify the data sources explicitly (“from my Google Drive project folder and HubSpot deal notes”), define the output format (“give me a bulleted executive summary with a risk flag section”), and set a time boundary (“for the past 30 days”).
Vague prompts like “summarise what happened in the business this month” will return something, but it will be inconsistent and harder to act on. The teams getting the most out of Deep Research with connectors have built prompt templates — stored in a shared Notion page or a ChatGPT custom instruction set — that every team member uses as a starting point. Prompt standardisation is not glamorous, but it is the operational practice that separates teams with high connector ROI from teams with mediocre connector ROI.
Connector-Augmented Research for External Competitive Work
The combination also works outward. Teams using the web search connector alongside internal data connectors can instruct Deep Research to synthesise internal pipeline data alongside publicly available competitor announcements, industry reports, and pricing pages. The output is a research brief that blends proprietary internal context with external market intelligence — something that previously required a dedicated analyst function to produce at any reasonable frequency.
Write Actions: Where Connectors Finally Get Some Teeth
For most of their life, ChatGPT Connectors have been fundamentally about reading data — fetching, searching, and summarising content from connected apps without touching anything on the other side. Write actions change that equation, and they represent the most significant recent evolution in what Connectors can do.
What Write Actions Currently Cover
Write actions allow ChatGPT, when connected to supported apps, to take actions rather than just report on them. In practice, the most mature write action implementations in mid-2026 include: drafting and sending emails via Gmail or Outlook (with user confirmation), creating calendar events, creating and updating Notion pages and database entries, creating GitHub issues and pull request comments, and triggering actions in connected automation platforms like Zapier or Power Automate.
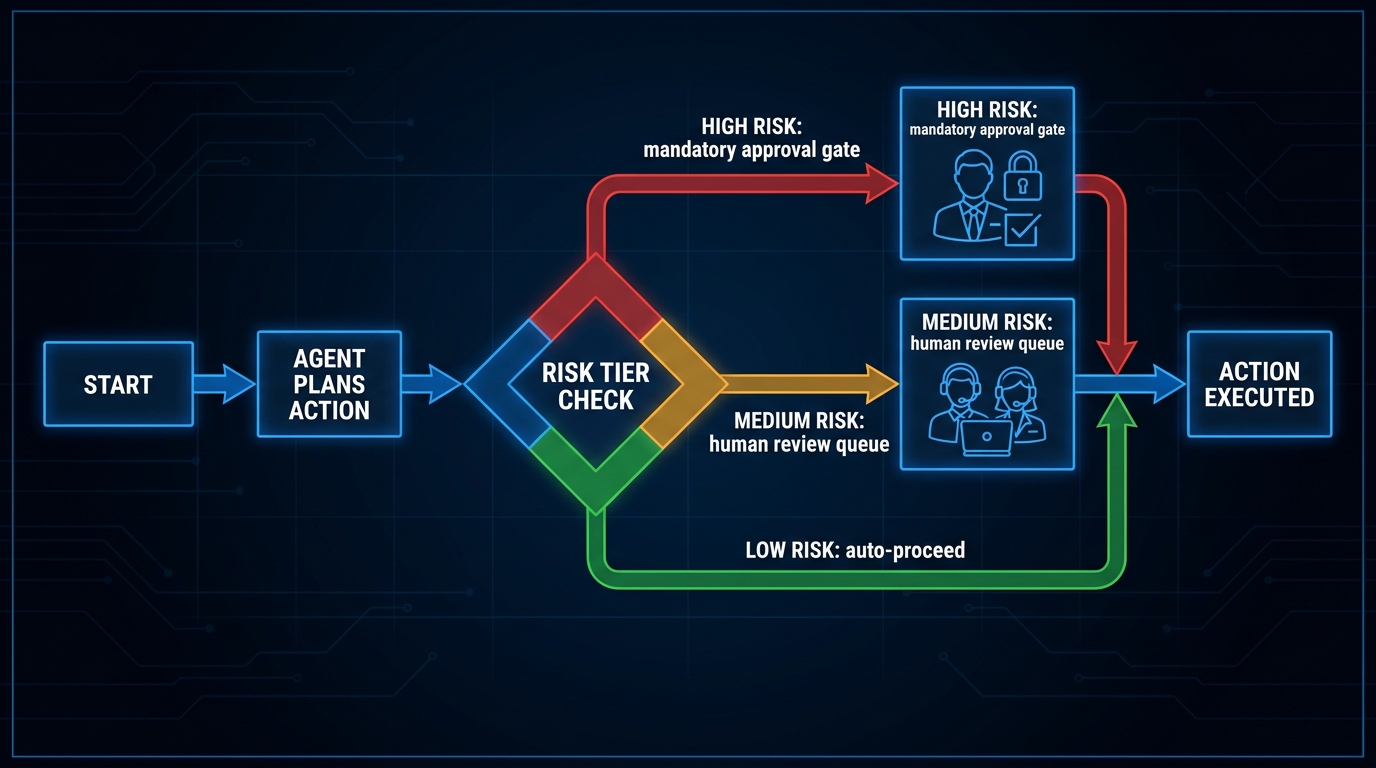
The key qualifier is “with user confirmation.” Most write action implementations include a confirmation step before execution — ChatGPT shows you what it is about to do and asks you to approve. This is not an arbitrary friction point; it is a deliberate design choice that addresses one of the central governance concerns about giving an AI model write access to production systems. Teams that find the confirmation step annoying often have workflows where the write volume is high enough that the confirmation becomes a bottleneck, which is a signal that those workflows should be moved to a fully automated pipeline via Zapier or Make rather than handled interactively in ChatGPT.
The Workflows Where Write Actions Are Actually Earning Their Keep
Meeting preparation and follow-up is the workflow category where write actions are delivering the most consistent value in practice. The pattern looks like this: a sales rep finishes a call, opens ChatGPT, prompts it to pull the call notes from their connected CRM, generate a follow-up email summarising next steps, create a calendar event for the agreed follow-on meeting, and update the deal stage in HubSpot. What used to take 20 to 30 minutes of fragmented admin work after every call now takes two to four minutes with connector-enabled write actions.
Multiply that across a 15-person sales team with four to six customer calls per day per rep, and the arithmetic becomes compelling quickly. One reported outcome from a sales operations team using this pattern was a 23% increase in closed deals — attributed specifically to the elimination of dropped follow-ups that previously fell through the cracks in the manual admin process.
Content creation workflows are the second area of strong adoption. Marketing teams are using write actions to take a research output produced by Deep Research, have ChatGPT transform it into a draft blog post or email campaign, and push that draft directly to a Google Doc or Notion page for editorial review. The human still edits, approves, and publishes — but the first draft, historically the most time-intensive part of the content production cycle, is handled by the connected workflow.
Where Write Actions Are Still Immature
It is worth being direct about the gaps. CRM write-back — the ability for ChatGPT to update deal records, contact properties, and pipeline stages directly in Salesforce or HubSpot based on conversation context — is inconsistent and limited outside of explicitly supported operations. Delete actions remain largely unavailable across the connector ecosystem; ChatGPT will not delete your emails or your files. Bulk write operations (updating 200 records at once rather than one at a time) are not reliable through the native connector interface and require the MCP layer or a separate automation platform for anything at scale.
Real Workflow Wins: Sales Operations and CRM Pipelines
Of all the functional areas where Connectors have been adopted in production, sales operations has the most clearly quantified outcomes and the most repeatable workflow patterns. This is partly because RevOps teams tend to have cleaner metrics for measuring impact — deal velocity, follow-up rates, CRM data quality — and partly because the pain points that Connectors address in sales ops are among the most acute across knowledge work.
Pipeline Hygiene at Scale
One of the most common and highest-ROI connector use cases in sales is automated pipeline hygiene review. The workflow: connect ChatGPT to the CRM (HubSpot natively, Salesforce via MCP), prompt it weekly to identify all deals past their expected close date, deals with no activity in the past two weeks, and deals missing required data fields. ChatGPT synthesises this into a prioritised cleanup list, flags the highest-risk deals, and drafts outreach messages for each stalled opportunity.
The manual version of this task — typically performed by a sales manager or RevOps analyst — takes two to four hours per week. The connector-assisted version takes under 20 minutes, including the time to review and approve the drafted outreach. More importantly, it happens consistently. Manual pipeline reviews are the first thing to get skipped when a team is busy. Connector-automated pipeline reviews happen on schedule regardless of how many fires are burning.
Lead Enrichment and Routing
A second high-value sales ops workflow combines CRM connectors with web search connectors for lead enrichment. When a new lead arrives in HubSpot, a connected workflow can instruct ChatGPT to research the company (size, funding stage, recent news, tech stack signals from public sources), score the lead against your ideal customer profile, draft a personalised first-touch email, and route the lead to the appropriate sales rep based on territory or vertical rules.
Teams implementing this workflow report near-zero data entry errors (because the enrichment is automated) and significant improvements in first-touch response quality. The personalised emails drafted by the enrichment workflow outperform generic sequence templates because they reference specific, current company context rather than generic industry messaging.
Meeting Brief Automation
Pre-call research is another workflow category where the time savings are immediate and the quality improvement is tangible. A connected brief generation workflow pulls the last three months of deal activity from CRM, any email thread history from Gmail, and recent news about the prospect company from web search, then synthesises a two-page meeting brief with talking points, known objections, and recommended next steps. Reps who use this workflow consistently report feeling more prepared and handling objections more confidently — not because the AI is doing the thinking, but because it is ensuring that relevant context is always surfaced before the call, rather than only when the rep happens to remember to look.
Real Workflow Wins: Knowledge Work, Documentation, and Internal Comms
Beyond sales, the second most impactful category of Connector deployment is in organisations with high volumes of internal knowledge work — professional services firms, product teams, research functions, and any operation where people spend significant time either finding information or documenting what they know.
The Internal Knowledge Base Problem
Most organisations accumulate knowledge in scattered, poorly organised repositories. Confluence wikis that no one updates. Notion databases where search returns 40 results for any query. SharePoint folders that have been added to for eight years by people who no longer work there. The standard solution — periodic knowledge audits, better tagging taxonomies, dedicated knowledge managers — is expensive and rarely sustained.
ChatGPT Connectors offer a different approach: rather than organising the knowledge base, you use ChatGPT as an intelligent interface on top of it. Connect ChatGPT to Notion, Confluence, or SharePoint, index the content, and let team members query the accumulated knowledge in natural language rather than through a search interface that requires them to know what to look for. The knowledge base does not get cleaner, but it becomes dramatically more accessible.
Teams running this pattern report reducing average information-retrieval time from 15 to 20 minutes (digging through docs) to two to three minutes (querying the connected index). Over a week of work, that adds up to context-switching reduction of up to 70% on knowledge-retrieval tasks — a figure consistent with productivity research on the cost of app-switching in knowledge-intensive roles.
Document Drafting and Iteration Workflows
The second major knowledge work use case is iterative document drafting. The workflow: retrieve relevant existing documents from Google Drive or SharePoint via connector, use them as context for drafting a new document (proposal, report, policy update, technical spec), and push the resulting draft back to the document store for review. The key here is that the connected context makes the drafts significantly better than prompting ChatGPT without access to internal references. When the model can read your existing proposal templates, client history, and pricing guides before drafting a new proposal, the output is calibrated to your organisation’s standards rather than generic.
Internal Comms and Status Reporting
Project status reporting is one of the most universally disliked administrative tasks in knowledge work. It is time-consuming, it is often written by people who would rather be doing the actual work, and it is frequently repetitive — summarising the same data that already exists in project tools. Connected ChatGPT workflows are changing this for teams running their projects in tools like Asana, GitHub, or Notion. A weekly status prompt can pull current task status, blocking issues, and completion metrics from the connected project tool, then draft a formatted status update ready for the team lead to review and send. The time savings per week per project manager run between 45 minutes and two hours depending on project complexity.
Real Workflow Wins: Engineering Teams and Code Repositories
Engineering teams were early adopters of AI coding tools via GitHub Copilot, but the ChatGPT Connectors integration with GitHub represents a different use case — less about autocomplete in the IDE and more about connecting code context to broader operational workflows.
Code Review Summarisation and Context Bridging
Large pull requests are a well-known productivity bottleneck in engineering organisations. A senior engineer reviewing a 2,000-line PR needs context on what the change is doing, why it was made, what tests cover it, and what risks it introduces. Historically, gathering that context means reading the commit history, the linked issue, the PR description (if one was written), and the diff itself. Connected ChatGPT can pull the GitHub PR, linked issue, and relevant documentation from a connected Confluence or Notion space and produce a structured review brief in under a minute. Reviewers still do the actual code review; they just arrive at it with context already assembled.
Incident Response and Post-Mortems
Incident response is another area where cross-system context is critical and time is scarce. When something breaks, engineers need to correlate information from monitoring tools, Slack threads, GitHub commits, and deployment logs simultaneously while also trying to fix the problem. Connected ChatGPT workflows can assist by pulling the recent commit history, the active incident Slack thread, and any linked issues into a single context window, then helping draft the timeline and contributing factors analysis for the post-mortem. Teams that have piloted this report significant reductions in post-mortem documentation time — from four to six hours to under two hours — while improving the accuracy and completeness of root cause analysis.
Developer Onboarding
Perhaps the most structurally impactful engineering workflow enabled by Connectors is developer onboarding. New engineers typically spend their first two to four weeks finding information about codebases, internal tools, processes, and conventions — primarily by asking colleagues and searching internal docs. A connected ChatGPT deployment that indexes the GitHub codebase, internal engineering wiki, architecture decision records, and runbooks dramatically compresses this ramp-up. Rather than waiting to find the right person to ask, a new hire can query the connected system directly. Teams report reducing effective onboarding time by 30 to 40% using connected knowledge systems — a significant saving given the cost of engineering talent.
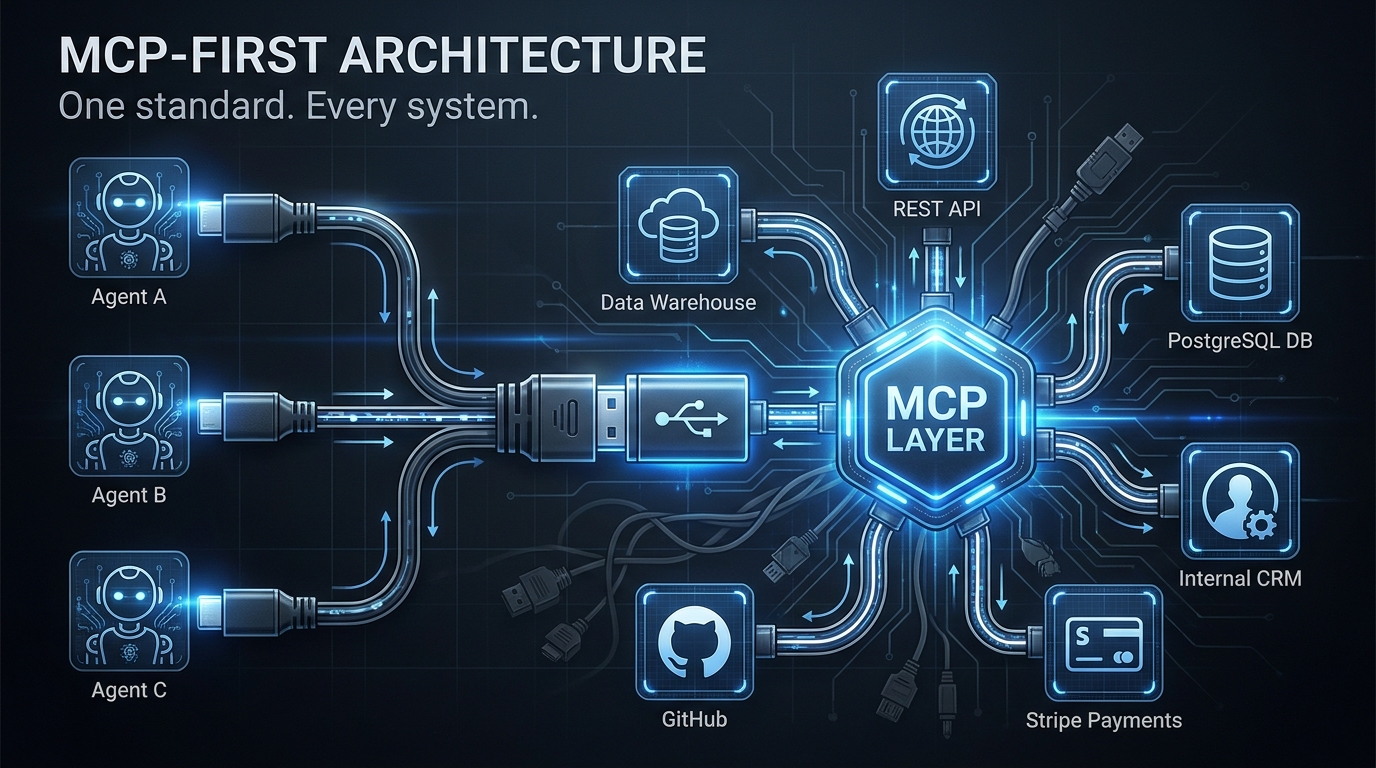
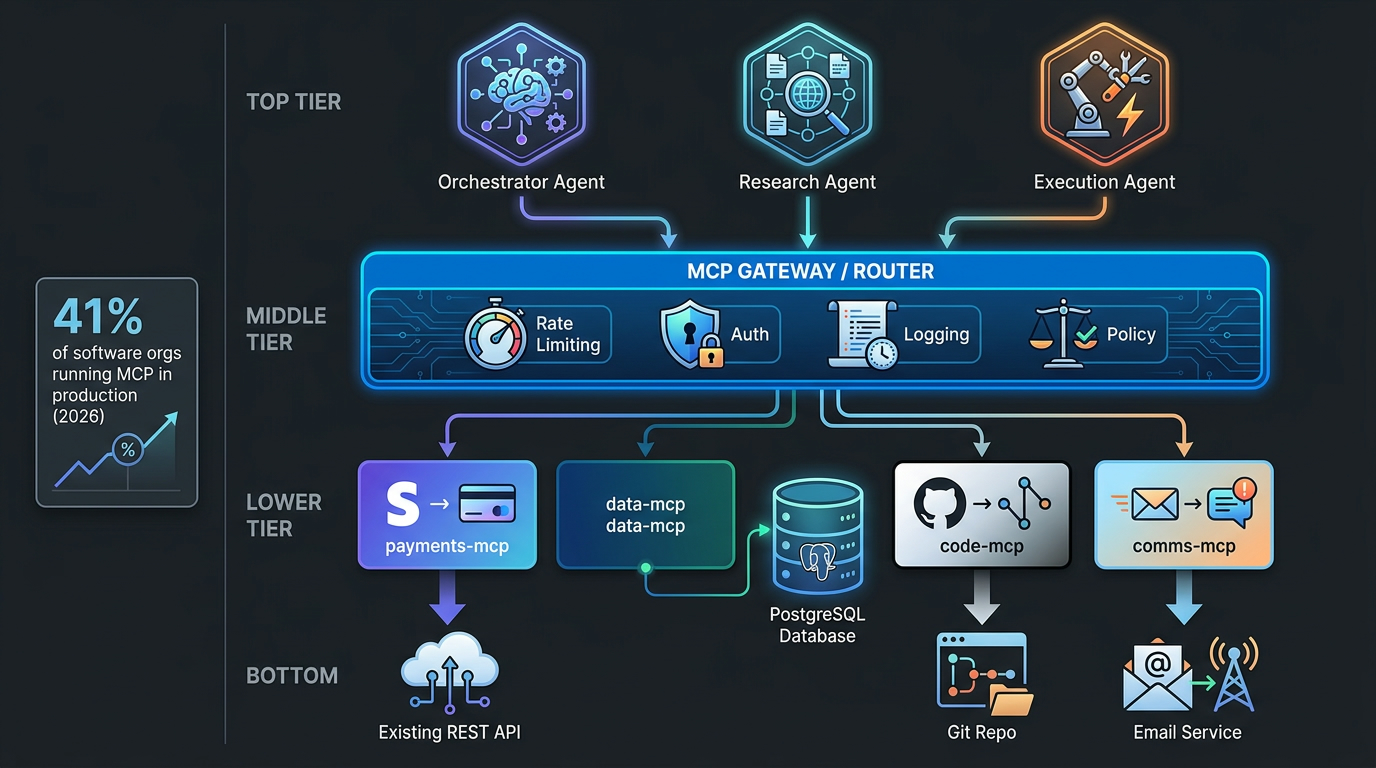
The MCP Layer: Building Custom Connectors That Can Actually Do Things
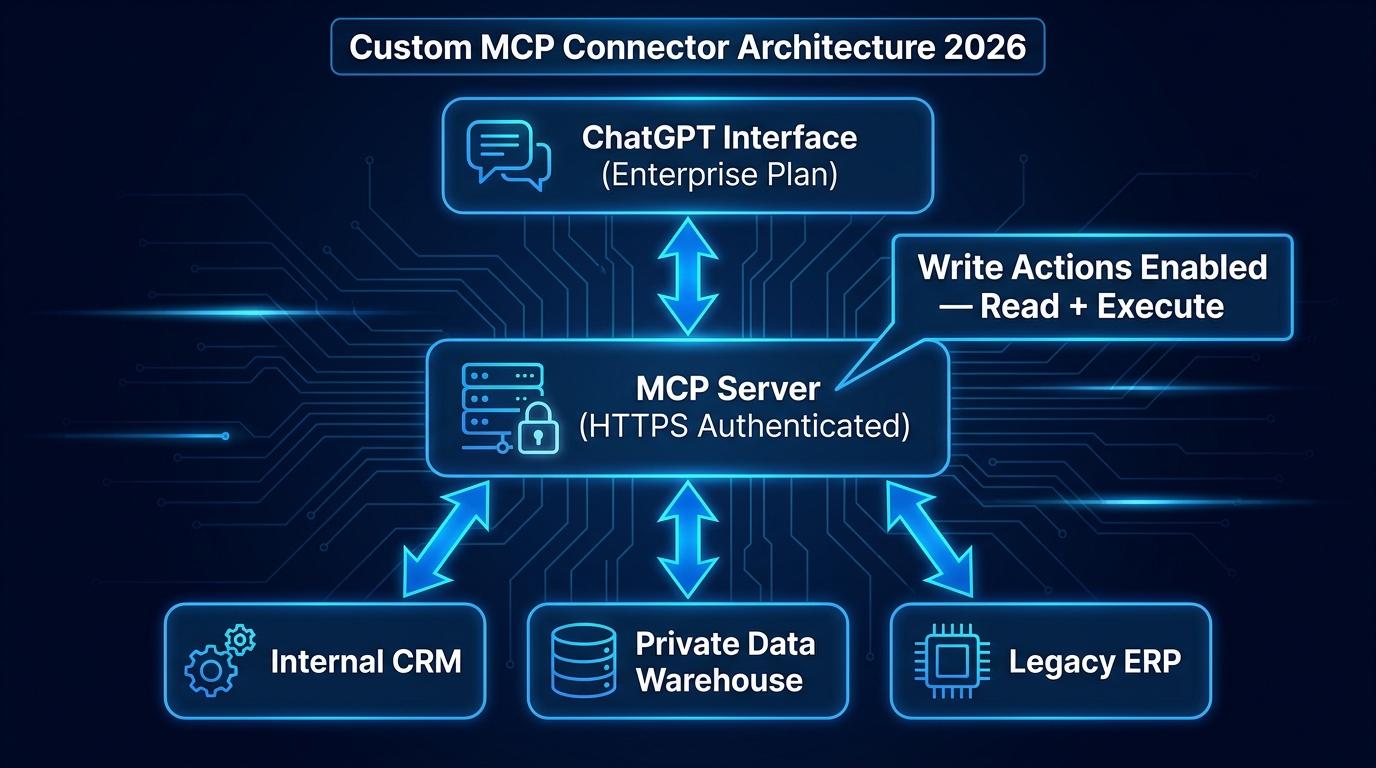
The native ChatGPT Connectors catalogue covers a wide range of applications, but it will never cover everything an enterprise uses. Legacy ERP systems. Custom internal databases. Proprietary data warehouses built on Snowflake or Databricks. Industry-specific tools in healthcare, finance, or manufacturing that are not on any SaaS connector list. This is where the Model Context Protocol (MCP) layer becomes essential.
What MCP Actually Is and Why It Matters
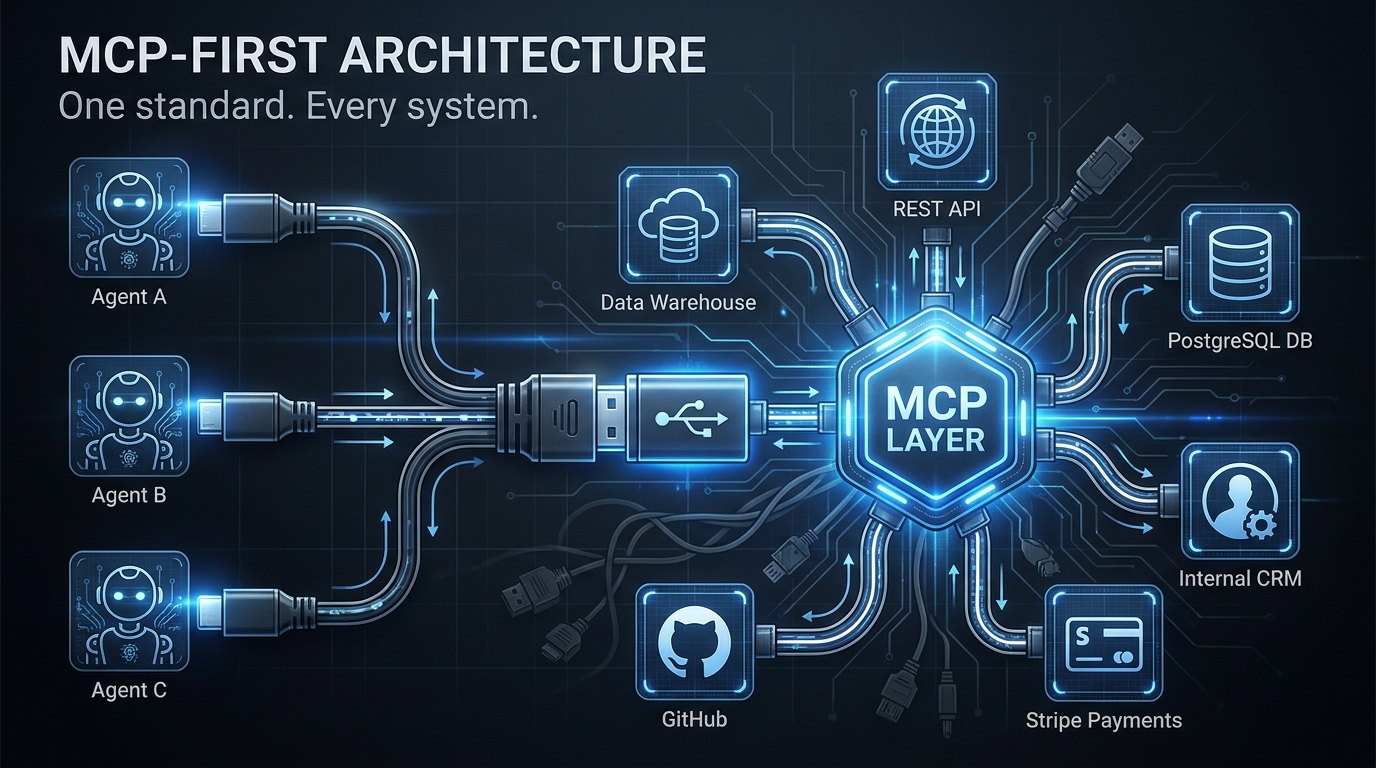
The Model Context Protocol is an open standard that defines how AI agents fetch data and perform actions through tool servers. In plain terms, it is the technical specification that allows you to expose any internal system — if you can build an HTTPS-authenticated API endpoint for it — as a connector that ChatGPT can read from and, with the right configuration, write back to.
For enterprises, this resolves the fundamental limitation of native connectors: the dependency on OpenAI to build and maintain an integration with every system you use. With MCP, you build the server layer yourself, you control the scope of what the model can access and do, and you can implement your own authentication, rate limiting, and audit logging in the process. The MCP connector (now formally called an “app” in ChatGPT’s Enterprise developer mode) is registered with your ChatGPT Enterprise deployment and becomes available to your team as if it were a native connector.
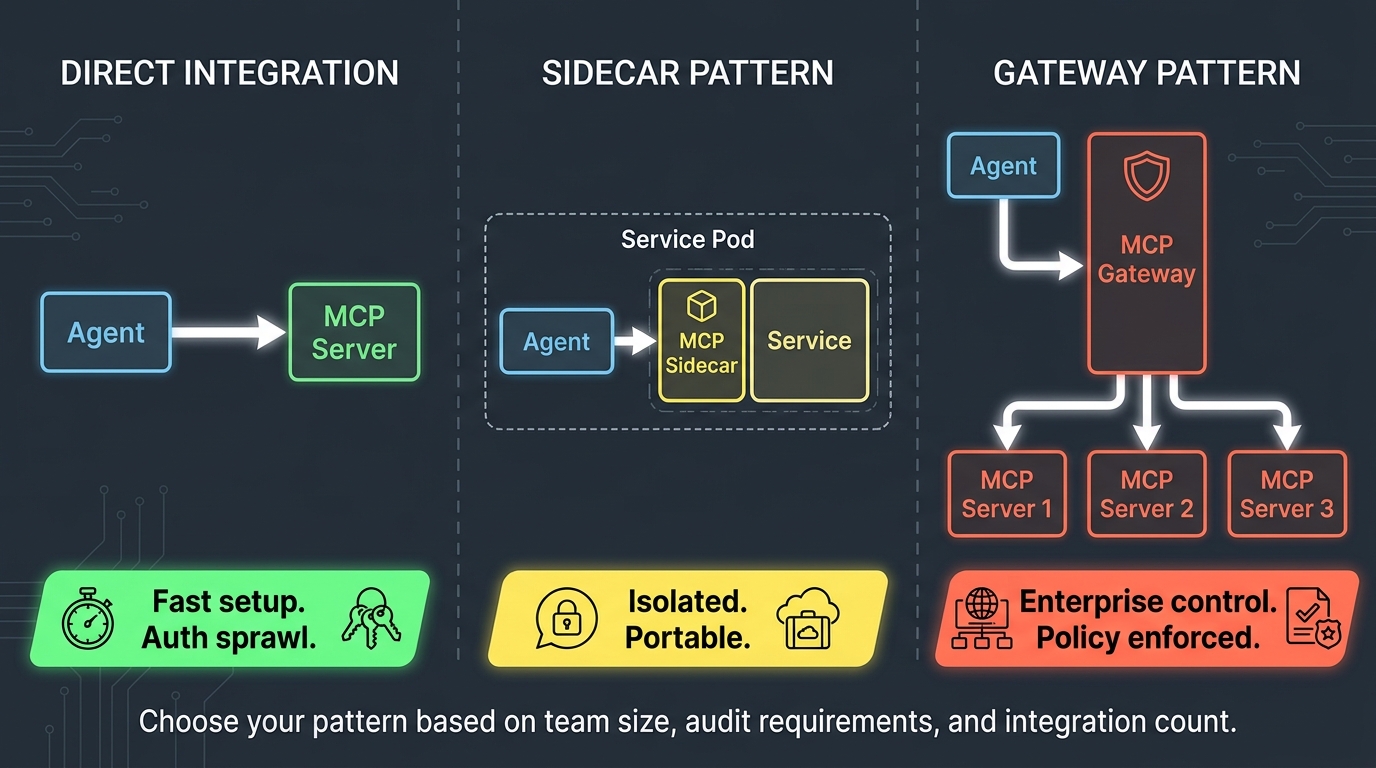
The Architecture in Practice
A typical enterprise MCP connector architecture for ChatGPT runs in three layers. The top layer is the ChatGPT interface — the Enterprise plan deployment that your team uses. The middle layer is your MCP server: an HTTPS-authenticated endpoint you build and host, which translates ChatGPT’s requests into queries or actions against your underlying systems. The bottom layer is your internal infrastructure — the CRM, the data warehouse, the ERP, the proprietary database — which the MCP server accesses using your existing internal credentials and access controls.
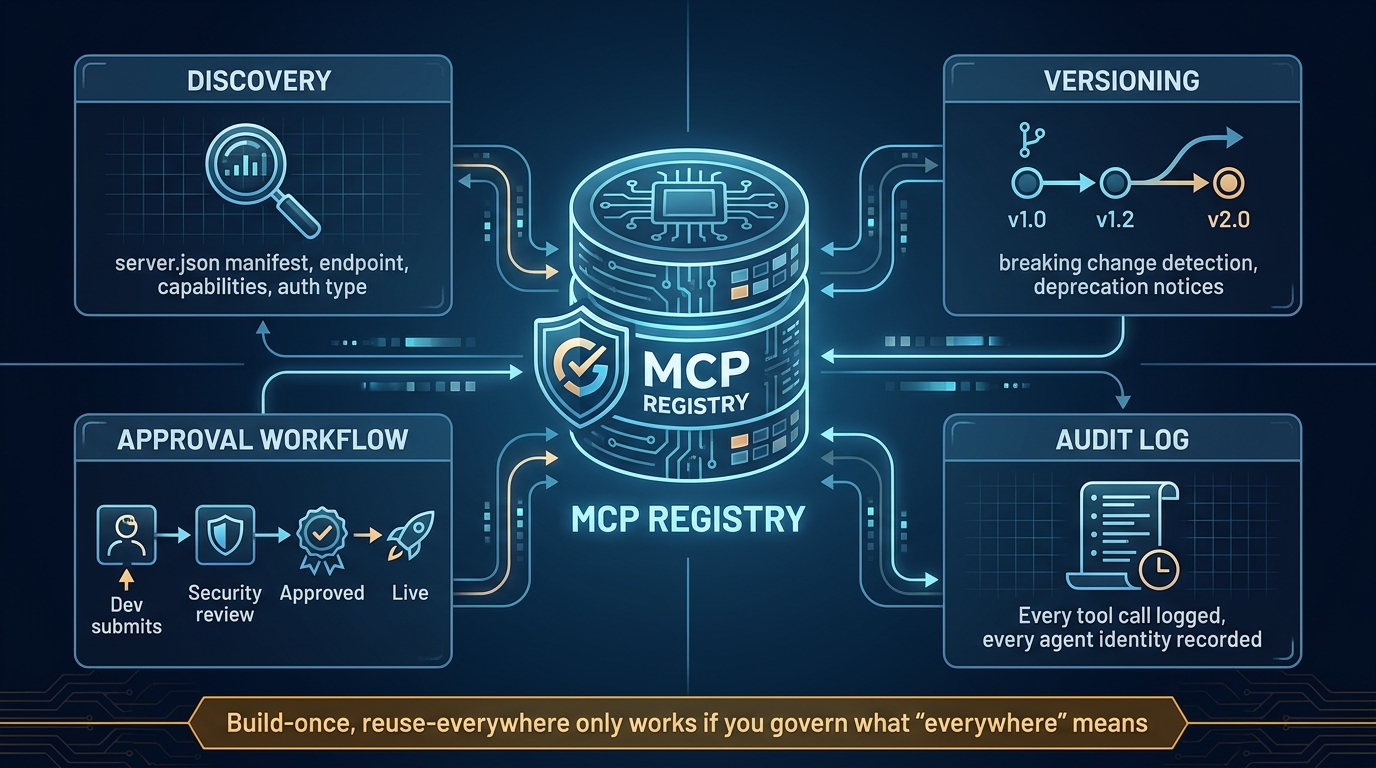
The middle layer is where most of the engineering effort lives. A well-built MCP server will implement: scoped access controls (so ChatGPT can only access the data the user is authorised to see), input validation (to prevent prompt injection attacks from reaching your internal systems), action confirmation for write operations, and comprehensive audit logging for compliance. A poorly built MCP server — one that passes raw user inputs directly to internal systems without validation — introduces the same prompt injection risks that make native connectors a concern in sensitive data environments.
What Custom MCP Connectors Enable That Native Connectors Do Not
The most significant capability gap that MCP connectors close is bidirectional, unrestricted write access. Where native connectors are largely read-only or limited to specific write operations, a custom MCP connector can expose any action your underlying system supports — updating records, triggering workflows, submitting transactions, even calling external APIs — subject only to the constraints you build into your server logic.
This opens up workflow categories that are simply not accessible through native connectors: procurement workflows that update ERP purchase orders, finance workflows that query and update budget tracking systems, compliance workflows that pull audit trails from multiple internal systems and generate regulatory reports. The build investment is higher than configuring a native connector, but the capability ceiling is also substantially higher.
The teams getting the most value from custom MCP development in 2026 are those who have identified two to three high-volume internal workflows where the ROI on build time is clear — typically workflows that combine information retrieval with a specific action that runs hundreds or thousands of times per month — and built focused, purpose-specific connectors rather than trying to expose every internal system at once.
The Limitations Teams Keep Hitting — An Honest Account
Any assessment of ChatGPT Connectors that does not spend real time on limitations is either a marketing document or a productivity post written before anyone tried to use the feature in anger. Here is where the real friction lives.
Read-Only Is the Default — and It Bites
For most native connectors, read-only is not a setting you can turn off — it is the default mode of operation. GitHub, Google Drive, Calendar, and similar integrations are described in OpenAI’s own documentation as essentially read-only in their native form. You can search, fetch, and summarise, but you cannot directly edit a Google Doc through the connector, you cannot delete a GitHub issue, and you cannot update a SharePoint page.
This surprises teams who assume connector access means full programmatic access. It does not. If your workflow requires write access to these systems natively — outside of the specific write actions that are explicitly supported — you need to route through an automation platform integration (Zapier, Make, Power Automate) or build the write capability into a custom MCP connector.
Context Window Size and Multi-Connector Queries
When you query multiple connectors simultaneously, the data returned from each connector competes for space in the model’s context window. For most straightforward queries this is not an issue. For complex deep research prompts that try to pull large volumes of data from three or four connected sources simultaneously, you can hit context limits that cause the model to truncate or miss data from later sources in the retrieval chain. The mitigation is to structure complex multi-connector queries as sequential focused queries — one connector at a time — rather than attempting to pull everything in a single prompt.
Connector Reliability Varies by Source
Native connector reliability is not uniform. Connectors for Google Workspace and Microsoft 365 tend to be the most stable and fastest. Third-party and less common connectors can be slower, hit rate limits, or return inconsistent results depending on the source system’s API reliability. Teams building time-sensitive workflows — anything that runs as part of a meeting or a live customer interaction — should test their specific connector configuration under realistic load before relying on it in production.
Single-Source Search Limitation
A commonly cited operational frustration is that connector search queries, outside of the Deep Research mode, tend to work best one source at a time rather than simultaneously across all connected sources. The multi-source synthesis that Deep Research mode enables is not the default behaviour in standard chat mode with connectors active. Standard chat with connectors enabled will typically search the most recently active or most contextually relevant connector for a given query, not all connected sources in parallel. Teams that discover this after assuming all queries would span all connectors often need to revisit their workflow design.
Regional Availability Gaps
Not all connectors are available in all regions. Enterprise deployments in certain geographies — particularly in parts of the EU, APAC, and the Middle East — may find that specific connectors are unavailable or operate under data residency constraints that affect what can be connected and how data is handled. This is an operational constraint that should be checked early in any regional deployment planning rather than discovered after contracts are signed.
Data Privacy and Governance: What Your Plan Tier Actually Determines

The governance question around ChatGPT Connectors is not abstract. It has concrete implications for whether the data your team feeds through connected apps can end up training OpenAI’s models, who within your organisation can access what through a shared ChatGPT deployment, and how you would demonstrate compliance if a regulator asked you to account for how sensitive data was processed.
The Plan-Tier Data Policy Split
OpenAI’s data use policy creates a clear divide by plan. For Business, Enterprise, and Edu plans, data processed through connected apps is not used to train OpenAI’s models. That is a firm commitment that enterprise teams can cite in their data processing agreements and vendor assessments. For Free, Plus, and Pro plans, data may be used to improve models if the user has model improvement enabled in their settings — the default varies and should be checked explicitly.
This is not a subtle distinction. If your team is running connector workflows on a Pro or Plus plan and model improvement is enabled, information from your connected Google Drive, HubSpot, or Slack workspace is potentially being used as training data. For most personal productivity workflows this is acceptable. For anything touching customer data, proprietary business information, financial data, or regulated personal information, it is likely not acceptable and may violate your obligations under GDPR, CCPA, HIPAA, or sector-specific regulations.
The practical governance advice is straightforward: use Enterprise or Business plan for any connector deployment that touches business-sensitive data. Document that decision as part of your AI governance framework. Do not allow team members to replicate Enterprise-level workflows on personal Plus accounts to work around the plan cost.
Prompt Injection: The Risk That Scales With Connector Scope
Prompt injection — where malicious content in a connected data source attempts to override the model’s instructions — is a real and growing concern as connector scope expands. The attack vector is simple to describe: a bad actor plants a specially crafted instruction in a document, email, or database record that ChatGPT is likely to read through a connector. When the model ingests that content, the injected instruction attempts to alter the model’s behaviour — exfiltrating data to an external URL, generating misleading outputs, or bypassing confirmation steps for write actions.
Native connectors mitigate this to some degree through content sandboxing, but the risk does not disappear. For custom MCP connectors, input validation in the server layer is the primary defence — never passing raw retrieved content directly into the model context without sanitisation. For native connectors, keeping connector scope narrow (connecting only the specific data sources a workflow needs, not every possible source) reduces the attack surface. Teams with high-sensitivity data environments should treat prompt injection as a genuine threat model, not a theoretical concern.
Access Control and Least Privilege
A principle of least privilege applies to connector configuration just as it does to any other access control framework. Connectors should be granted the minimum scope of access required for the specific workflow they support. A connector built to support sales pipeline review does not need access to HR documents or financial records. A connector supporting engineering onboarding documentation does not need write access to the production code repository.
In practice, teams often connect the broadest available scope during setup (because it is easier) and then leave it wide. This is the connector governance equivalent of giving every employee admin access because it is less work than configuring individual permissions. It creates unnecessary risk and complicates compliance documentation. Building narrow, purpose-specific connector configurations from the outset is more work upfront and significantly better practice.
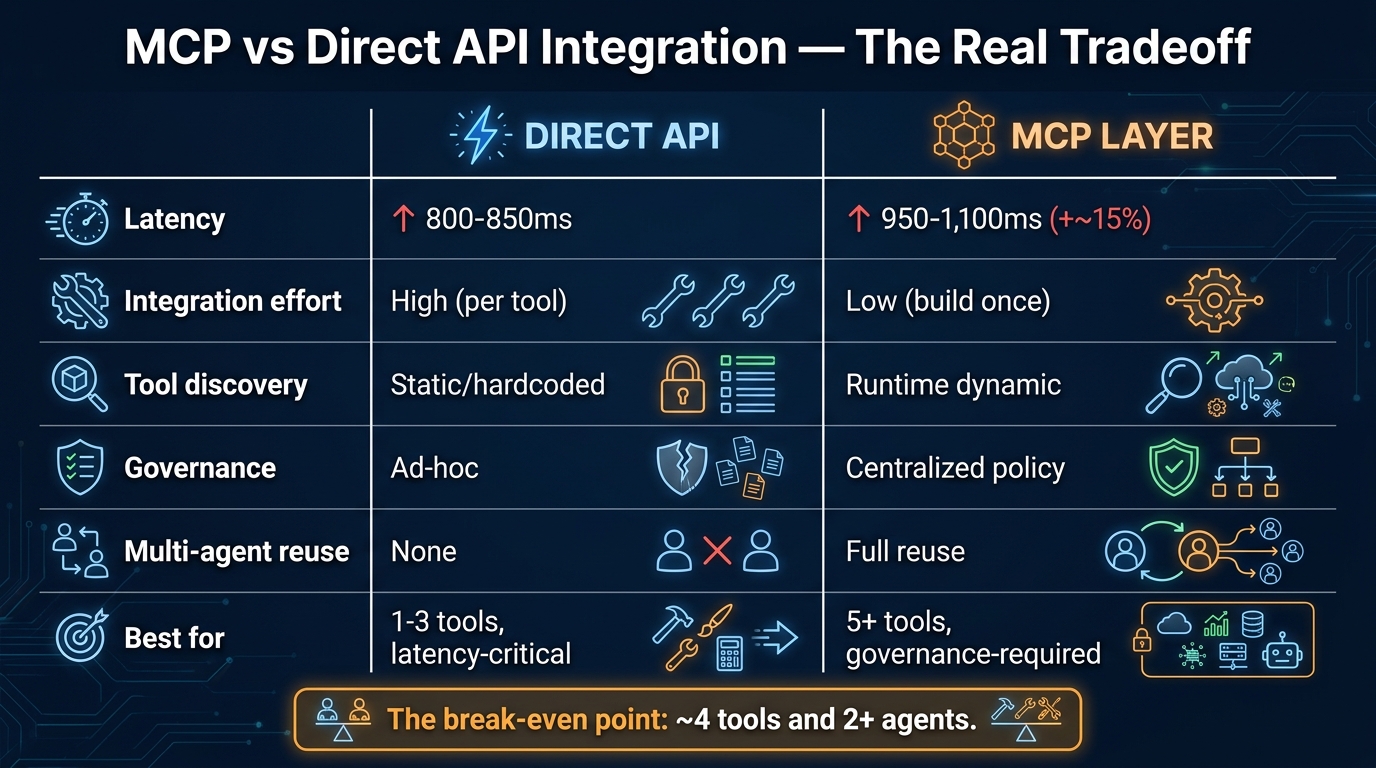
ChatGPT Connectors vs. Zapier, Make, and Power Automate: Choosing the Right Layer
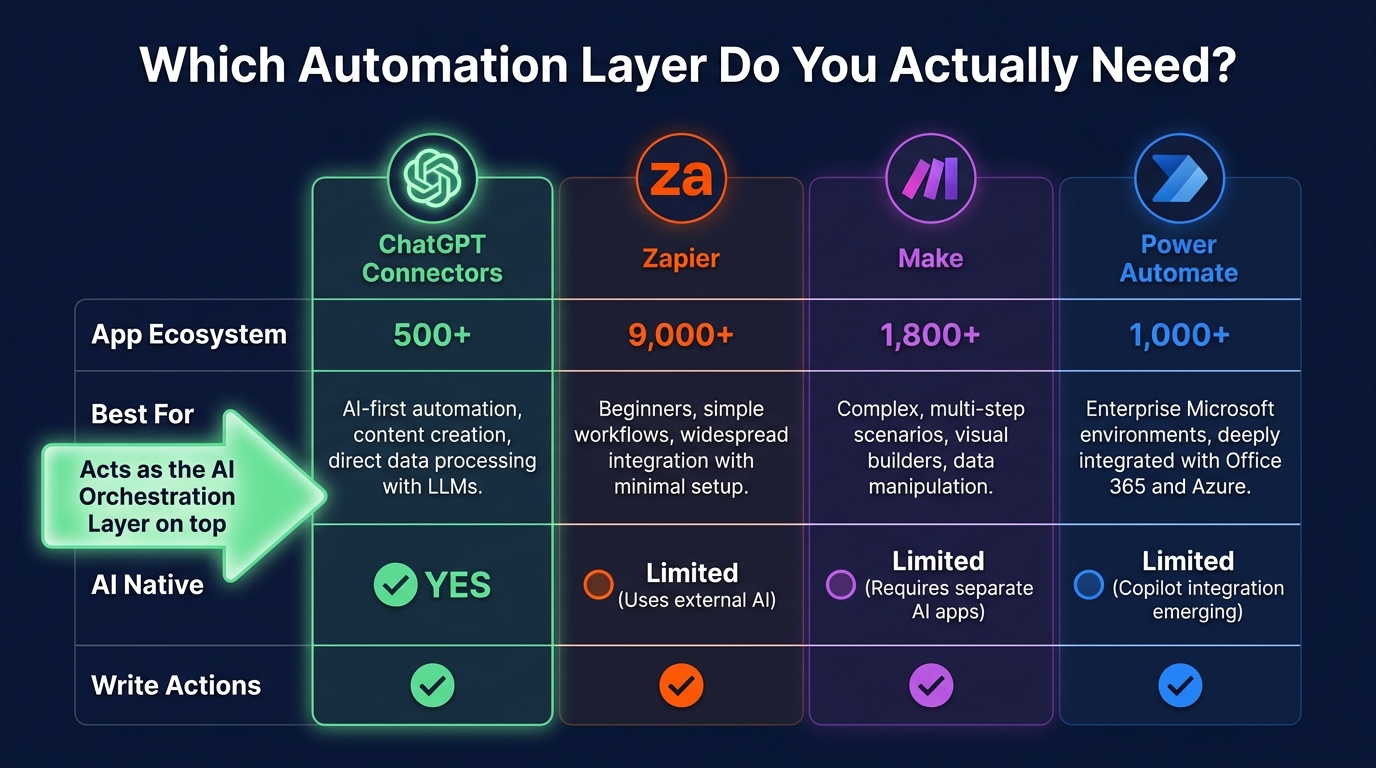
This comparison comes up in almost every conversation about deploying ChatGPT Connectors at scale, and it is usually framed as a competition — which platform should you use? The more useful framing in 2026 is about layers: these tools are not competing for the same function, and the most effective workflow architectures often use more than one of them simultaneously.
What Each Platform Is Actually Good At
Zapier leads the automation platforms on breadth. With over 9,000 connected apps, the fastest setup for non-technical users, and AI-assisted workflow design, Zapier is the right choice when the priority is connecting the widest possible range of tools with minimum engineering effort. If your workflow involves an app that is not in ChatGPT’s native connector catalogue, Zapier probably has it. The limitation is cost at high-volume automation scenarios and the relative complexity of multi-step, conditional logic-heavy workflows.
Make (formerly Integromat) is the strongest option for complex, high-volume automation with sophisticated conditional logic. Its visual workflow builder handles branching, looping, and error handling more elegantly than Zapier for multi-step workflows, and its pricing model is more favourable for high-operation-count scenarios. Teams with custom, non-standard workflow logic that would require a Zapier “Paths” configuration with multiple nested conditions typically find Make more maintainable.
Power Automate is the native choice for Microsoft 365-centric enterprises and any organisation with significant governance and compliance requirements. Its deep integration with the Microsoft stack — Teams, SharePoint, Dynamics, Azure — makes it the obvious default for organisations that have standardised on Microsoft. Its AI Builder component is increasingly capable, and its governance controls are more mature than the other options for regulated industries.
ChatGPT Connectors are not a replacement for any of these. They are the AI reasoning and orchestration layer that sits on top of them. When you connect ChatGPT to Zapier, you are using ChatGPT’s language understanding to decide what Zapier should execute. When you connect ChatGPT to Power Automate, you are adding natural language control and synthesis capability to workflows that Power Automate runs. The most powerful implementations in 2026 use ChatGPT as the intelligent interface layer while relying on dedicated automation platforms for the actual cross-system execution at scale.
When ChatGPT Connectors Alone Are Sufficient
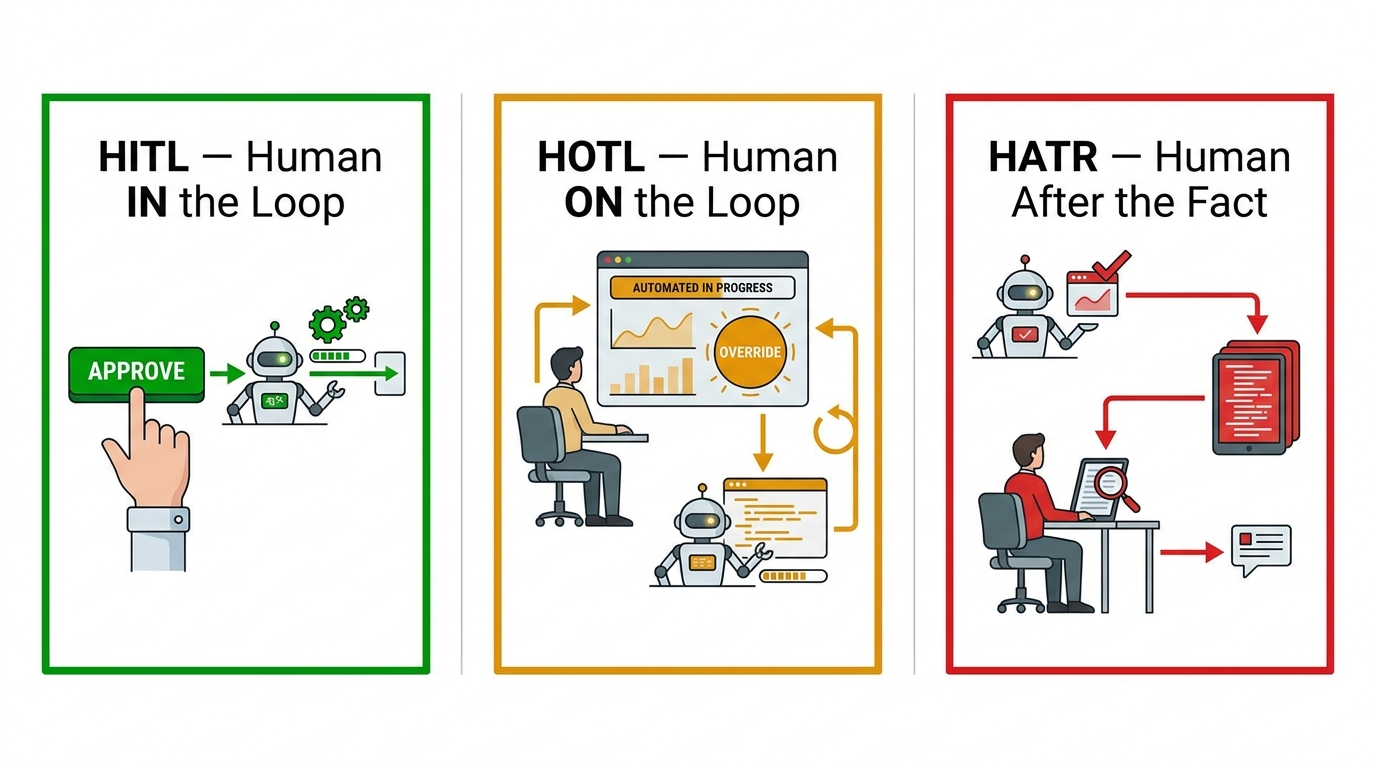
There is a class of workflow where ChatGPT Connectors alone — without an underlying automation platform — are the right and sufficient choice. These tend to share three characteristics: they are human-in-the-loop (a person is reviewing and approving at each step), they are moderate volume (not thousands of operations per day), and they benefit significantly from natural language generation in the output (not just data transfer).
The sales pipeline review, meeting brief generation, and knowledge base query workflows described earlier all fit this profile. They are tasks where a human is present in the workflow, the volume is manageable, and the quality of the synthesised language output matters. Automated lead routing that processes 500 inbound leads per day does not fit this profile — it needs an automation platform underneath it.
The Layered Architecture That Sophisticated Teams Are Using
The architecture that is emerging among the most sophisticated connector deployments in 2026 uses three layers: the automation platform (Zapier, Make, or Power Automate) as the backbone that handles trigger logic, conditional routing, and high-volume execution; ChatGPT with Connectors as the reasoning and synthesis layer that generates outputs, makes decisions based on context, and interacts with humans in natural language; and MCP custom connectors as the bridge to internal systems that neither ChatGPT nor the automation platform natively supports.
Building all three layers is not necessary for every workflow — start with the simplest configuration that solves the problem, and add layers only when you hit a ceiling that a simpler setup cannot clear. But understanding that this three-layer architecture exists, and which layer is responsible for what, saves teams from trying to make ChatGPT Connectors alone do jobs that require an automation platform, or building expensive MCP custom connectors for apps that already have mature native integration.
The Workflow Wins Worth Prioritising This Week
The honest conclusion about ChatGPT Connectors in mid-2026 is that the platform is more capable than most teams are using it for, more limited than some promotional coverage suggests, and more strategic in the decisions it requires than a simple feature checklist reveals.
The wins are real. Teams are saving 40 to 60 minutes per worker per day on search and synthesis tasks. Sales operations teams are recovering deals that used to fall through the cracks and seeing measurable conversion improvements. Engineering teams are compressing onboarding timelines. Knowledge workers are accessing institutional memory that used to be effectively invisible. These are not theoretical gains — they are happening in production, in identifiable workflow categories, through specific connector configurations.
The limitations are equally real. Read-only by default. Inconsistent multi-source query behaviour in standard chat mode. Plan-tier governance that genuinely matters for sensitive data. Prompt injection as a non-trivial threat surface. Regional availability constraints that affect enterprise deployments in certain geographies.
The Four Workflows to Start With
If you are deciding where to begin — or where to expand — these four workflows have the clearest ROI track record and the most manageable setup complexity:
- Pipeline hygiene review: Connect your CRM (HubSpot natively, Salesforce via MCP) and run a weekly stalled-deal review with automated outreach drafts. Setup time: two to four hours. Time saved: two to four hours per week per ops person.
- Meeting brief generation: Connect CRM plus Gmail plus web search. Pre-call research brief on demand. Setup time: one to two hours. Time saved: 20 to 40 minutes per call per sales rep.
- Internal knowledge query: Index your Notion or Confluence workspace via the connector and provide the team with a natural language interface for internal documentation. Setup time: four to six hours including index configuration. Context-switching reduction: significant and immediate for research-heavy roles.
- Status report drafting: Connect your project management tool (Notion, GitHub, Asana) and automate weekly status update drafts. Setup time: two to three hours. Time saved: 45 minutes to two hours per project manager per week.
What to Audit Before You Build
Before deploying any connector workflow that touches business-sensitive data, run through this checklist: confirm your team is on Business or Enterprise plan (not Plus or Pro); review which data sources the connector needs access to and configure the minimum required scope; document the data types being processed and check them against your organisation’s data classification policy; identify any write actions in the workflow and confirm the confirmation/approval step is functioning as expected; and if you are building a custom MCP connector, ensure input validation and audit logging are in place before connecting to production systems.
The Bigger Picture
What the Connectors trajectory in 2026 signals is a shift in what ChatGPT is fundamentally for. It is not settling into a role as a writing assistant or a question-answering tool, though it can still do both. It is becoming the intelligent interface layer on top of the applications and data sources that organisations already run — a place where natural language queries produce synthesised, contextualised, actionable outputs that no single source system could generate on its own.
That is not where it arrived — it is where it is heading, measurably and week over week. The teams positioned to benefit the most from that trajectory are not the ones waiting for the platform to mature further. They are the ones building now, in the workflow categories where the ROI is clear, with governance configurations that will not bite them when the capabilities expand further. The wins this week are real. The infrastructure you build around them is what determines whether those wins compound.