The pitch is compelling enough that almost everyone buys it the first time: build AI automation that can detect its own failures and fix them — without a human in the loop. You deploy it. Something breaks. The system, as advertised, “heals” itself. Your dashboard stays green. Everybody relaxes.
Then, six weeks later, you discover that the automation has been quietly re-routing a class of transactions to a fallback path, and those transactions haven’t actually been completing. They’ve been disappearing. The system healed itself so efficiently that nobody noticed the underlying process was failing thousands of times a day.
This is the central paradox of self-healing AI automation in 2026: the systems that are best at recovering from failures are also the best at hiding them. A green dashboard built on top of an improperly designed self-healing layer is more dangerous than a red one, because at least a red dashboard prompts someone to look.
This post is not an argument against self-healing automation — it genuinely works, it genuinely reduces downtime, and teams that implement it well report detection accuracy improvements from 67% to 94%, and auto-resolution rates reaching 80% of all production incidents. But “implementing it well” requires understanding what self-healing is actually supposed to fix, how the feedback loop should be structured, and — critically — which failure modes it will make worse if you design it carelessly.
Here is the full architecture: the failure taxonomy, the control loop, the resilience layers, the governance model, and the anti-patterns that turn self-healing systems into sophisticated liability generators.
The Five Failure Classes Self-Healing Must Actually Address
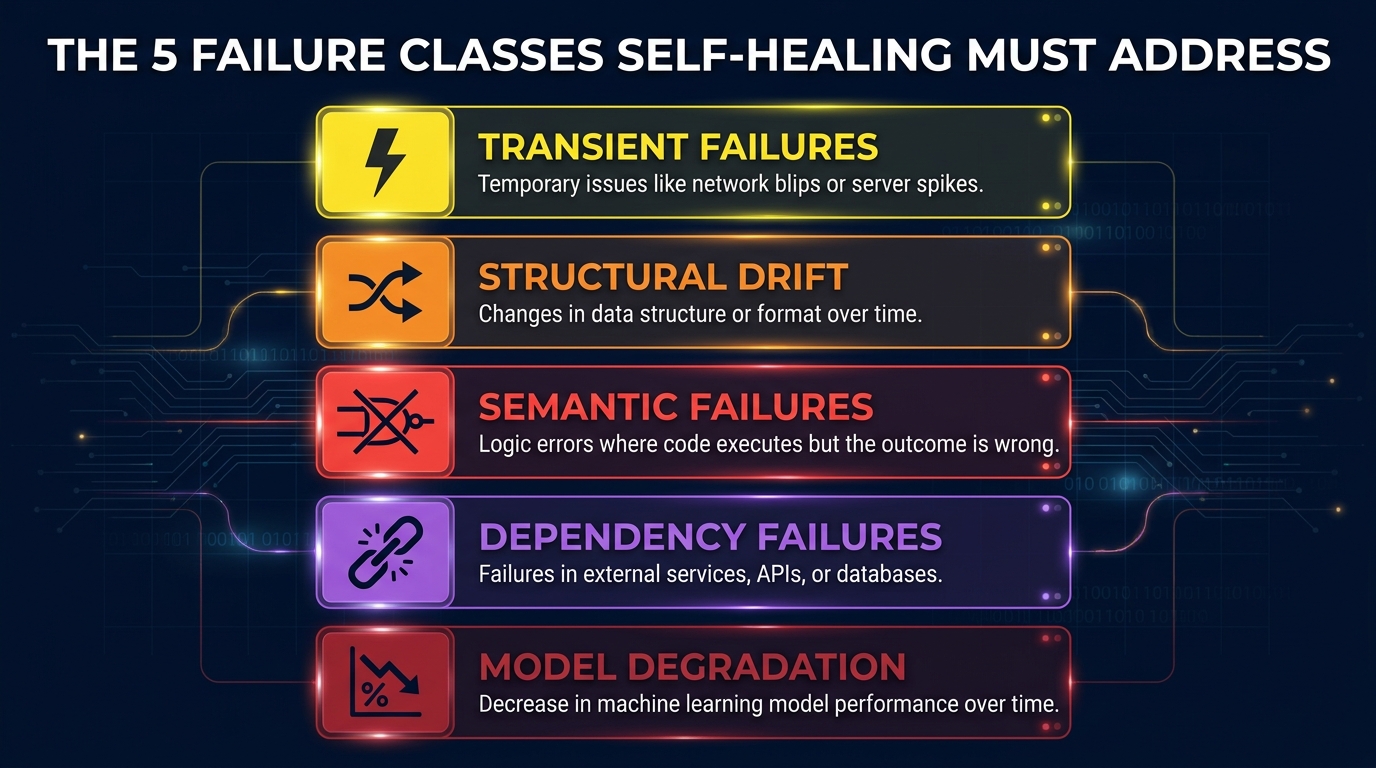
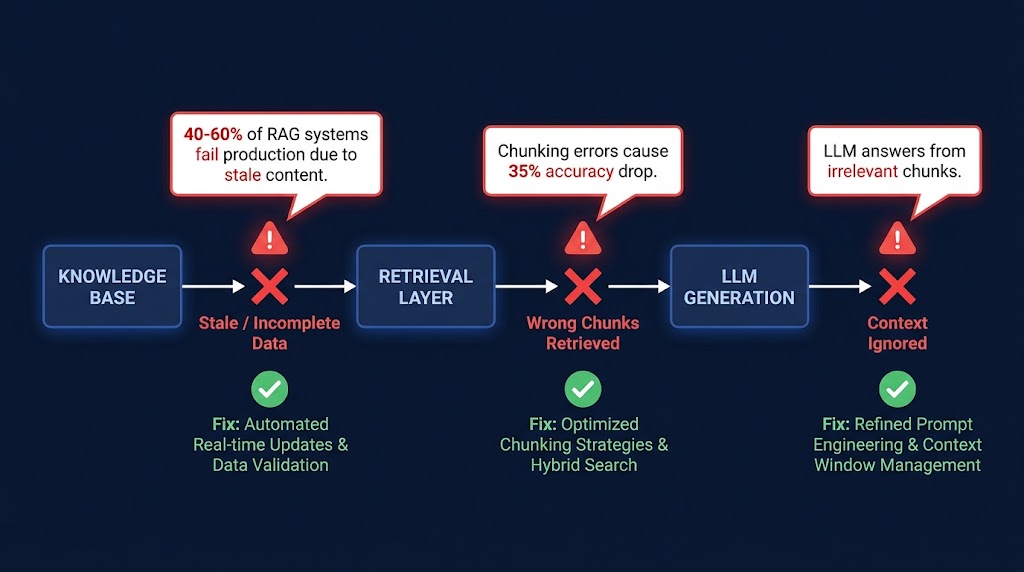
The first mistake most teams make is treating all automation failures as the same category of problem. They build a single “self-healing” mechanism — usually retry logic or a simple restart trigger — and apply it everywhere. This works for one type of failure. It makes four others worse.
Before you design any self-healing system, you need a failure taxonomy. These are the five distinct classes your automation will encounter, and they require fundamentally different remediation strategies.
1. Transient Failures
These are the failures that resolve themselves if you wait. A network timeout. A downstream API rate-limit response. A temporary database lock. They’re caused by conditions that are inherently unstable and time-bound, and they account for a large percentage of what automation systems report as failures on a given day. Retry logic with exponential backoff is the correct and sufficient response. Applying anything more sophisticated — AI diagnosis, human escalation, re-routing logic — to transient failures is wasted complexity that slows your system down and pollutes your incident logs with noise.
2. Structural Drift
Structural drift is what happens when the environment the automation was built for has changed in a way that breaks the automation’s assumptions. In test automation, this is the classic locator problem: a UI element gets a new ID, and the test script can no longer find it. In RPA, it’s a desktop application that updated its layout. In data pipelines, it’s a source API that added required parameters. These failures are not transient — they will happen again every single run until someone fixes the underlying cause. Self-healing automation in this class means detecting the structural change, finding an alternative selector or mapping, applying the fix, and logging the change for human review. The AI component here is useful and well-established. Studies from RPA deployments report 70–90% reductions in UI-change-related failures when this class of healing is properly applied.
3. Semantic Failures
Semantic failures are the hardest class to automate remediation for, and the most dangerous to get wrong. This is when the automation runs successfully by every technical measure, but does the wrong thing. An AI classification model routes invoices to the wrong approval queue. A sentiment analysis step misreads a customer complaint as neutral. An extraction automation pulls the right field from the wrong version of a document. Semantic failures don’t throw errors. They produce outputs that look valid. The self-healing logic for this class must include output validation — comparing results against expected distributions, flagging statistical outliers, and routing to human review when confidence drops below a defined threshold. Attempting to auto-remediate semantic failures without human review is where systems create the kind of invisible damage described in this post’s opening paragraph.
4. Dependency Failures
These occur when a component your automation depends on — an upstream service, a third-party API, a data feed — fails independently of your system. The correct self-healing strategy here is circuit breaking: detecting that a dependency is unhealthy, stopping outbound requests to protect both your system and the failing dependency, and initiating a controlled degradation path. This might mean switching to a cached data source, queuing work for later processing, or switching to an alternative provider. The AI component in dependency failure remediation is primarily in predicting which dependencies are likely to fail before they do, based on latency trends and error rate patterns — so you can pre-warm alternatives rather than scrambling during an outage.
5. Model Degradation
For automation systems that include AI models, model degradation is its own failure class. The model doesn’t break — it just gets progressively worse. Training data becomes stale. The real-world distribution of inputs drifts away from the distribution the model was trained on. A model that was 94% accurate when deployed might be making decisions at 71% accuracy six months later, without any single failure event that would trigger a conventional alarm. Self-healing for model degradation requires continuous monitoring of output distributions, accuracy proxies, and feature statistics, with automated retraining triggers when drift crosses defined thresholds. This is covered in depth later in this post.
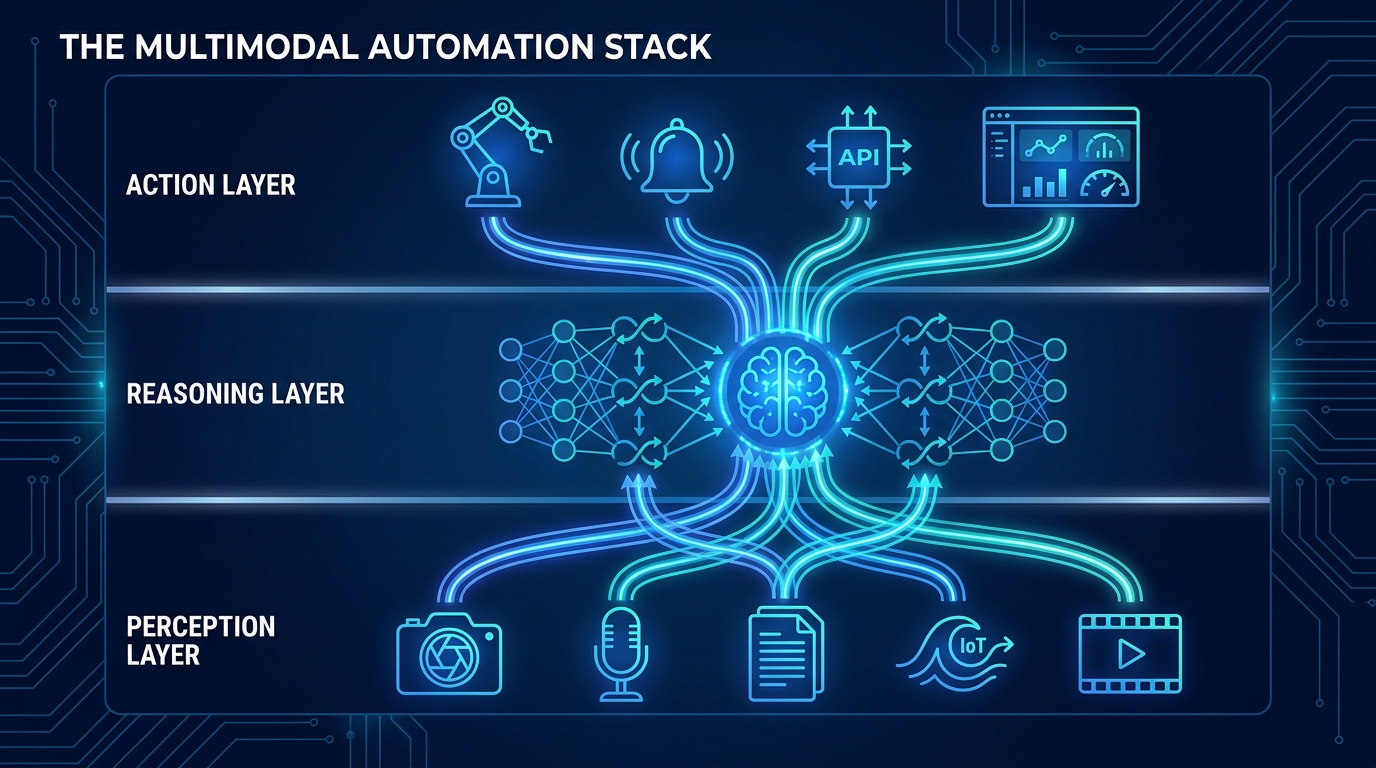
The ODDAL Loop: The Architecture That Makes Healing Systematic
Most self-healing implementations are reactive: something breaks, a recovery script fires, the system tries to continue. This architecture works for transient failures and nothing else. For all other failure classes, you need a proactive control loop that treats observability as a first-class design primitive rather than an afterthought bolted on after deployment.
The loop has five phases. Getting the sequence right is non-negotiable — skipping or conflating any phase is the single most reliable way to produce a system that heals the wrong thing.
Phase 1 — Observe
Observability in the context of self-healing is not the same as logging. Logging records what happened. Observability gives you the telemetry — metrics, traces, structured events, model output statistics — needed to detect anomalies before they become failures. The critical design decision here is instrumenting for the right signals. For infrastructure, this means latency percentiles and error rates. For data pipelines, it means row counts, null rates, and distribution statistics on key fields. For ML components, it means tracking prediction confidence scores, output distributions, and a rolling sample of predictions versus ground-truth labels where available. Teams that skip this phase try to build self-healing on top of reactive error logs, which means they only see failures after they’ve already caused damage.
Phase 2 — Diagnose
Once an anomaly is detected, the system needs to classify it correctly before deciding what to do. This is where AI earns its place in the loop — not as the thing that fixes failures, but as the thing that correctly identifies what kind of failure it is. An LLM-based diagnosis agent can parse logs, compare the anomaly signature against a catalog of known failure patterns, assess blast radius, and produce a structured failure classification with a confidence score. The output of the diagnosis phase should be: failure class (using your taxonomy), estimated root cause, confidence level, and recommended remediation action. It should explicitly not be an autonomous fix — that comes next, with governance.
Phase 3 — Decide
The decide phase is where most self-healing systems either get too aggressive or not aggressive enough. Too aggressive: any diagnosed failure triggers immediate auto-remediation, regardless of confidence or impact. Not aggressive enough: everything gets escalated to humans, defeating the point of automation entirely. The correct model is a tiered confidence and risk framework, covered in detail in a later section. The key design principle is that the decide phase must be explicitly modeled — it should not be an implicit consequence of the diagnosis. Every possible remediation action should have a documented threshold for when it fires automatically, when it fires with notification, and when it requires explicit human approval.
Phase 4 — Act
The act phase executes the chosen remediation. Good remediation actions share four properties: they are idempotent (running them twice doesn’t make things worse), reversible (there is a rollback path), scoped (they affect the smallest possible part of the system), and observable (they produce a log entry that confirms the action was taken and what changed). Actions that fail any of these four tests should not be automated. A restart of a failed service is idempotent, reversible, scoped, and observable. A bulk data correction across a production database is probably none of those things and should require explicit human approval regardless of diagnosis confidence.
Phase 5 — Learn
The learn phase is what separates a self-healing system from a self-recovering one. Self-recovery handles the incident. Self-healing permanently reduces the probability of that incident happening again. Learning means feeding the outcome of each incident — what was diagnosed, what action was taken, whether it worked — back into the diagnosis model, the playbook catalog, and the threshold configuration. Over time, a well-designed learn phase produces a system whose auto-resolution rate increases, whose false-positive alert rate decreases, and whose diagnosis accuracy improves. The case study data showing detection accuracy jumping from 67% to 94% over three months reflects exactly this dynamic — the system was learning from each resolved incident.
Layered Resilience: Where Classic Patterns Meet AI-Driven Repair
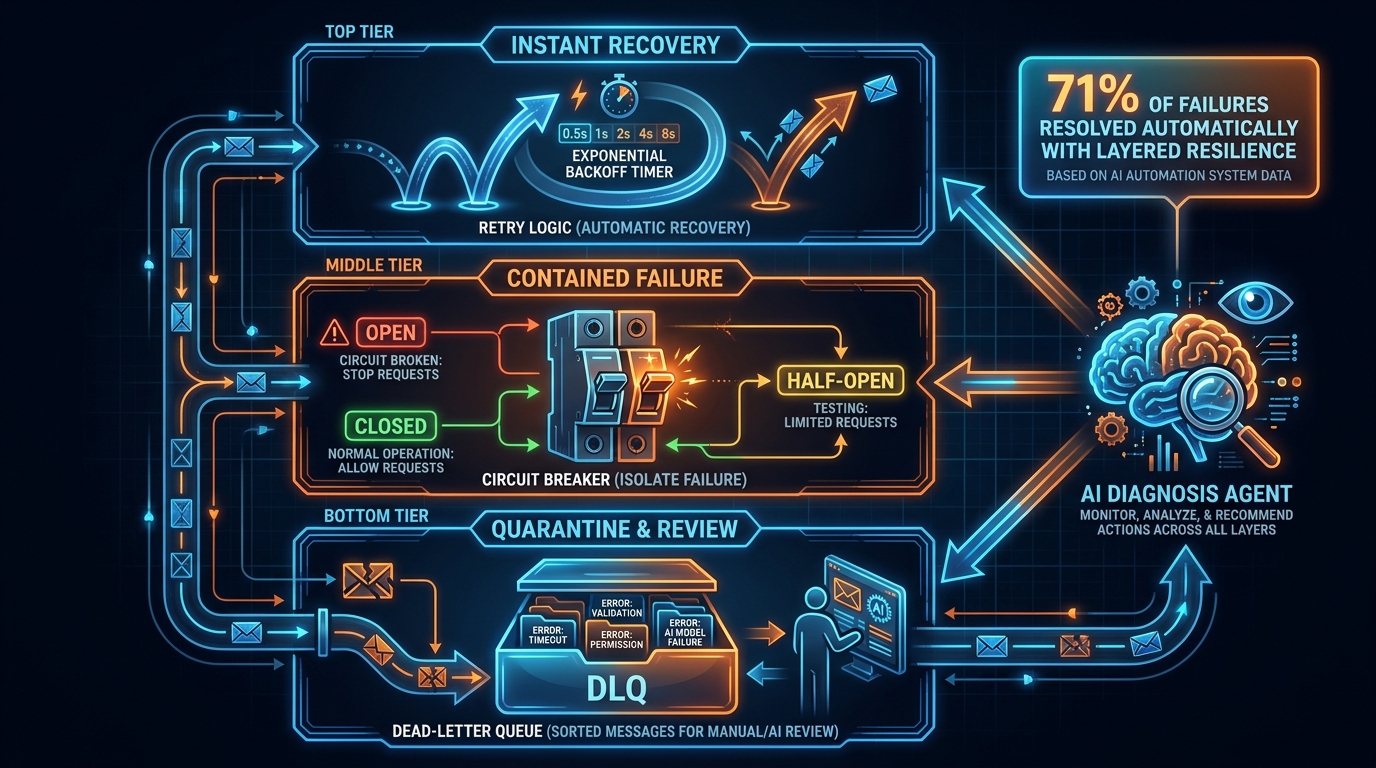
Self-healing is not a replacement for classic resilience engineering patterns. It is an extension of them. Teams that try to build AI-native self-healing from scratch without the underlying resilience primitives in place are skipping steps that have decades of production validation behind them. The right architecture layers AI-driven healing on top of — not instead of — circuit breakers, retry logic, and dead-letter queues.
Layer 1: Retry Logic with Exponential Backoff
This is the baseline. Every network call, every API integration, every external dependency interaction should be wrapped in retry logic that uses exponential backoff with jitter. “Jitter” — randomizing the wait time slightly on each retry — prevents the thundering-herd problem where thousands of simultaneous retries hit a recovering service at the exact same moment and knock it back down. The right configuration for most production systems is three attempts, starting at 100ms, doubling each time, with a maximum wait of around 30 seconds. Retries are appropriate only for transient failures — idempotent operations where re-executing the same request cannot cause duplicate state changes. Write operations that are not idempotent need idempotency keys or sequence numbers before retry logic applies safely.
Layer 2: Circuit Breakers
When retries keep failing — when a dependency isn’t just slow but structurally broken — you need a circuit breaker. The pattern has three states: closed (normal operation, all requests pass through), open (dependency marked as unhealthy, all requests fail fast without attempting the call), and half-open (a probe state where a small number of requests are allowed through to test whether the dependency has recovered). Circuit breakers protect your system from cascading failures by preventing resource exhaustion on calls that will fail anyway. They also protect struggling downstream services from being hammered by retry storms. The AI addition to this layer is predictive circuit breaking — using latency trend data and error rate patterns to open the circuit before failure rate crosses the threshold, rather than after.
Layer 3: Dead-Letter Queues
Some failures can’t be handled immediately, but they also can’t be discarded. A dead-letter queue (DLQ) is a holding area for messages or tasks that have exhausted their retry budget. Items in the DLQ are preserved rather than lost, and they become the target of both automated and manual remediation efforts. A well-designed DLQ integration does three things beyond simple storage: it categorizes items by failure type upon entry (so the AI diagnosis agent doesn’t have to re-process cold data), it sets an expiration policy that’s appropriate to the business context, and it surfaces volume metrics to an alerting system so that a spike in DLQ depth triggers review before items expire. In business-process automation, the DLQ is where semantic failures typically land — they weren’t technically invalid, but something about them didn’t meet validation thresholds, and a human needs to make the call.
Where AI-Driven Repair Fits in the Stack
AI-driven repair sits above all three classic layers, not below them. Its job is to handle the failures that Layer 1, 2, and 3 have captured but not resolved — those that require contextual diagnosis, adaptive remediation, or structural change to fix. An AI diagnosis agent reading DLQ contents and classifying failure types is a force multiplier on the classic stack. An AI agent attempting to replace Layer 1 retry logic is a performance liability and a governance nightmare.
Confidence Thresholds and the Human-in-the-Loop Gate Model
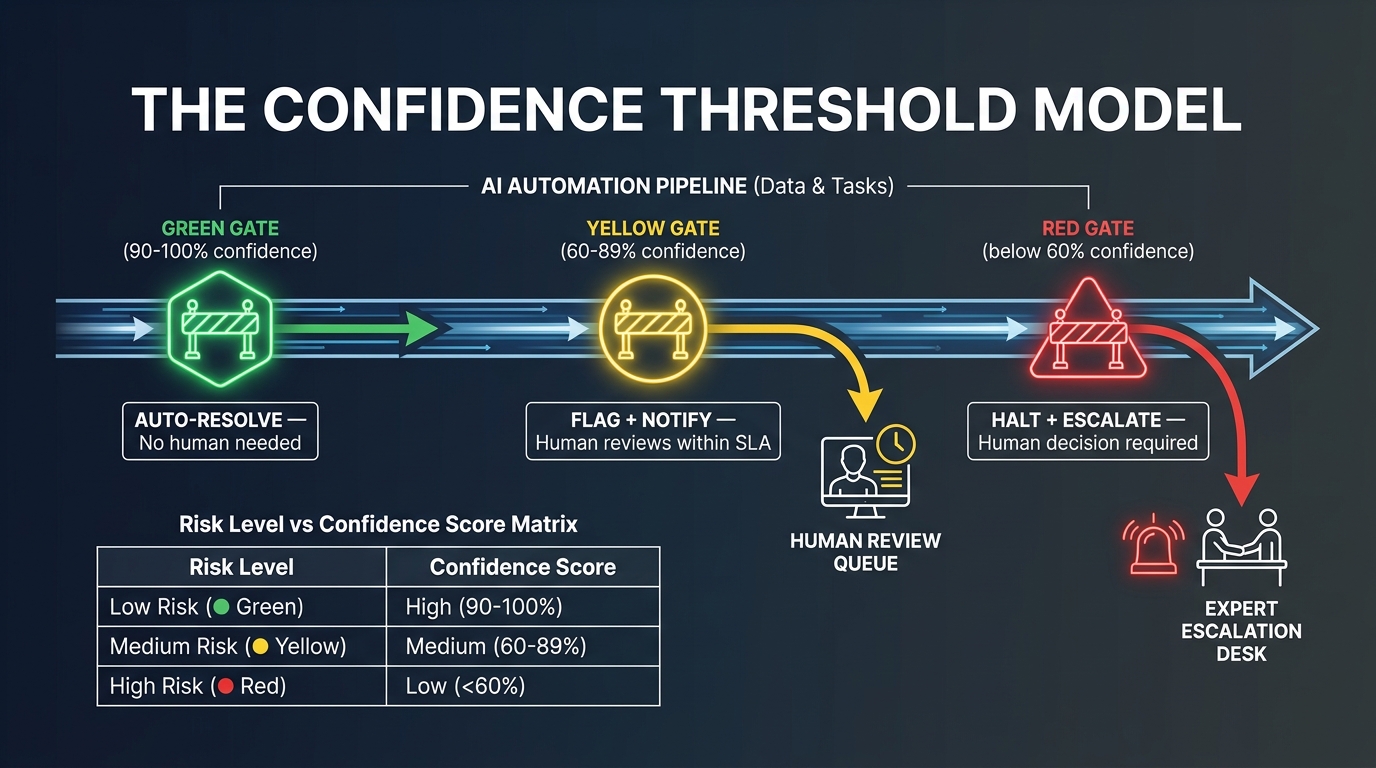
The most consequential design decision in a self-healing system is not the detection algorithm or the remediation playbook. It is the threshold model that determines when the system acts autonomously, when it notifies a human and proceeds, and when it stops and waits for explicit approval. Get this wrong in either direction and you’ve built a system that’s either useless or dangerous.
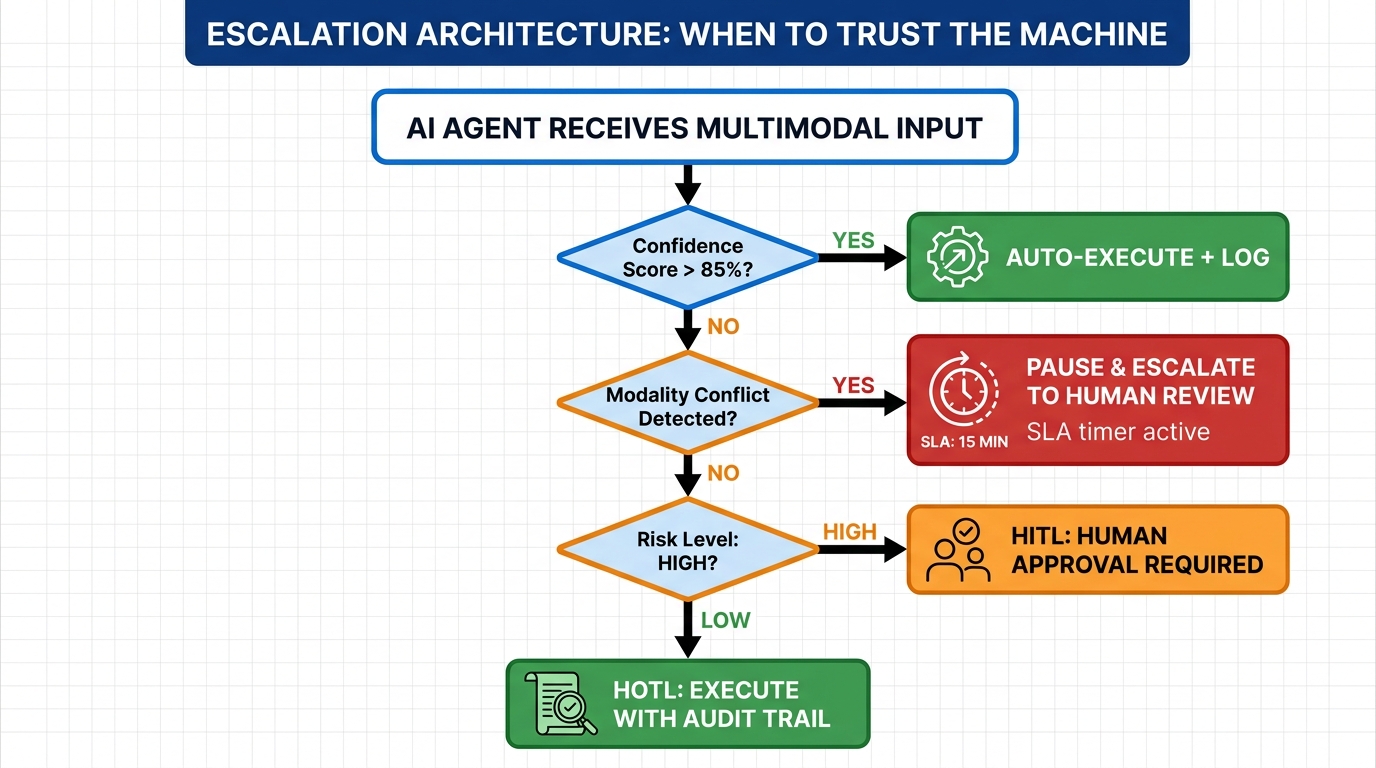
The Three-Gate Model
A practical, field-tested threshold model uses three gates based on a combination of diagnosis confidence score and estimated impact of the remediation action.
Gate 1 — Auto-Resolve (High confidence + Low impact): Confidence score above 90%, remediation action is reversible and scoped. The system acts autonomously, logs the action with full detail, and sends a low-priority notification to the owning team. No human approval required. Example: retry a failed API call, restart a hung worker process, re-route traffic from an unhealthy pod.
Gate 2 — Flag and Notify (Medium confidence or Medium impact): Confidence score between 60–89%, or remediation action affects more than a single component. The system proposes a specific remediation, notifies the on-call engineer with full diagnosis context, and proceeds with the action after a defined window (typically 15–30 minutes) unless the engineer overrides. This preserves velocity while ensuring a human sees high-frequency healing events before they compound. Example: update an API authentication credential that has rotated, apply a schema migration to bring a downstream consumer back in sync.
Gate 3 — Halt and Escalate (Low confidence or High impact): Confidence score below 60%, or the remediation action could affect data integrity, financial transactions, or production databases. The system halts the affected workflow, fires a high-priority alert, and presents the diagnosis and candidate remediation options to the on-call engineer for explicit approval. Example: any bulk data operation, any action affecting a payment processing pipeline, any remediation that modifies a core configuration file.
Setting Thresholds Is Not a One-Time Decision
Threshold calibration is an ongoing operational task, not a deployment setting. Teams that set thresholds at deployment and never revisit them end up with systems that were calibrated against early failure patterns and are operating on stale assumptions six months later. A governance practice that reviews threshold performance monthly — measuring auto-resolution correctness rate, false-positive escalation rate, and missed-escalation incidents — is what keeps the model well-calibrated over time. The target metrics: auto-resolved actions should have a post-validation pass rate above 95%; escalations should have a confirmation rate below 20% (meaning most human reviews confirm the system’s diagnosis was correct and the escalation was appropriate, not that the system was wrong).
Regulated Environments Require Stricter Default Thresholds
In financial services, healthcare, and other regulated verticals, the gate model needs additional constraints beyond confidence and impact. Some remediation actions may be prohibited from automation entirely under regulatory frameworks, regardless of confidence score. Others require a documented audit trail before they can be replicated. Before deploying a self-healing layer in a regulated context, the compliance team needs to review the full remediation playbook and flag which actions have regulatory implications — and those actions should be moved to Gate 3 by policy, independent of the AI’s confidence assessment.
Drift, Schema Change, and Model Degradation: The Slow Failures Nobody Notices
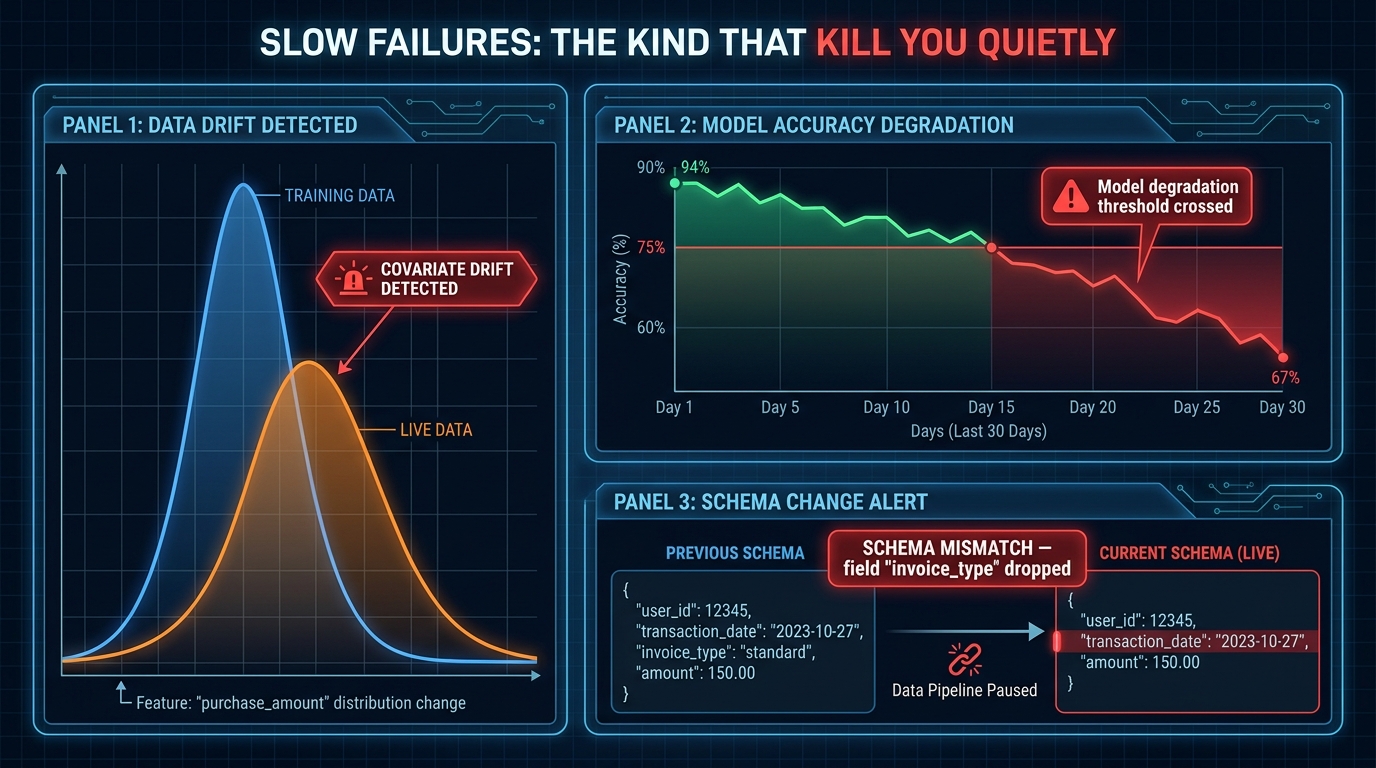
Fast failures are comparatively easy to handle. They produce errors, they trigger alerts, they have clear timestamps. Slow failures — the ones that degrade over weeks or months — are the ones that destroy confidence in automation systems, because they’re often discovered not by the system’s own monitoring, but by a downstream stakeholder who notices that something seems off.
There are three categories of slow failure that self-healing architectures must address specifically, with their own detection and remediation strategies.
Covariate Drift: When the World Stops Matching the Training Data
Covariate drift occurs when the statistical distribution of inputs to an AI model shifts away from the distribution the model was trained on, without the outputs immediately showing obvious errors. A fraud detection model trained on transaction patterns from 2024 may be systematically underflagging a new class of fraud that emerged in late 2026. A document extraction model trained on a specific invoice template may silently degrade as suppliers update their templates. The distribution of inputs has changed; the model’s weights haven’t.
Detecting covariate drift requires monitoring feature statistics — mean, variance, and distribution shape of key input fields — in the live environment and comparing them against baseline statistics captured at training time. Statistical tests like the Kolmogorov-Smirnov test or Population Stability Index (PSI) can be run as scheduled pipeline steps and used to trigger alerts when drift exceeds a defined threshold. The remediation — automated or human-approved — is typically a retraining trigger that pulls recent production data into the training set and re-validates the model before deploying the update.
Schema Change: When Upstream Data Stops Matching Expectations
Schema changes are among the most common causes of silent data pipeline failures. An upstream team renames a column, drops a field, changes a data type from string to integer, or starts populating a previously null field. The pipeline downstream doesn’t break loudly — it either throws a handled exception and continues with nulls, or misinterprets the changed field and produces subtly wrong outputs. One industry estimate puts the annual cost of data downtime at $3.6 million per organization, and schema change is one of the primary contributors.
Self-healing for schema change requires schema registry integration and contract testing at pipeline ingestion points. When a new batch of data arrives, the pipeline should validate it against the expected schema before processing. On mismatch, the detection should classify the type of change — additive (new fields added, generally safe), breaking (fields renamed or dropped, requires remediation), or type-changing (field type altered, requires explicit validation logic). Additive changes can often be handled automatically with conservative defaults. Breaking changes should route to Gate 2 or Gate 3, depending on the affected pipeline’s downstream impact.
Model Degradation: Measuring What You Can’t Directly Observe
The hardest slow-failure class to detect is model degradation in cases where you don’t have ground-truth labels available in real time. A model making predictions about customer churn won’t have its predictions validated for 30, 60, or 90 days — by the time you know whether the prediction was right, the model has made thousands more decisions without feedback. Two proxy approaches bridge this gap: output distribution monitoring (tracking whether the distribution of predicted classes or scores is shifting over time relative to the baseline) and confidence score monitoring (tracking whether the model’s own internal confidence scores are trending downward, which often precedes measurable accuracy degradation).
When either proxy metric triggers an alert, the self-healing response is calibrated: first, flag recent predictions that fell in the degraded confidence range for human spot-check review; second, accelerate the ground-truth collection timeline where possible (which might mean sampling a subset of predictions for manual validation); third, trigger a candidate retraining run in a shadow environment and hold it for evaluation before any production deployment. The decision to swap the degraded model for the retrained candidate should always be a Gate 2 or Gate 3 action — the cost of deploying a worse model than the one it replaces is typically higher than the cost of a short review delay.
Anti-Patterns: How Self-Healing Creates New Fragility

Every pattern introduced to reduce fragility has a failure mode of its own. Self-healing is no exception. The following are the anti-patterns most commonly observed in production deployments — not theoretical edge cases, but patterns that teams have shipped, regretted, and had to retrofit out of live systems.
Silent Healing: The “Green Dashboard” Trap
This is the anti-pattern described in the introduction. The self-healing system recovers from failures without surfacing them, resulting in a monitoring dashboard that looks healthy while the underlying system is in a degraded state. Every healing action should generate a visible log entry, categorized by failure class and remediation applied. Healing event volume should be tracked as its own metric — and a spike in healing frequency should trigger an alert, because it means the system is working harder than normal to maintain normal-looking outputs. A system that is healing five times per hour is not operating normally; it is compensating for something that needs a structural fix.
Over-Healing: Masking Real Defects
In test automation, this is the phenomenon where self-healing tools keep test suites green by automatically adapting to UI changes — including changes that represent genuine defects in the product under test. The tests pass; the product is broken. The same failure mode exists in production automation: a self-healing system that automatically routes failing tasks around a broken downstream component may be hiding the fact that the downstream component has a data quality problem that’s been growing for weeks. Self-healing logic should escalate on healing frequency, not just on healing failure. If the same type of failure is being healed repeatedly, that pattern itself is an alert condition requiring root cause investigation.
Confidence Theater
This anti-pattern occurs when teams implement confidence scoring in their diagnosis layer but set all the thresholds so permissively that the confidence score never actually gates an action. Everything routes to Gate 1. The confidence score becomes a number that appears in logs but doesn’t influence behavior. This is worse than not having confidence scoring at all, because it gives the appearance of governance without the substance — a situation that tends to surface badly in post-incident reviews or audits. Threshold calibration should be treated as a security-review-grade design decision, with explicit documentation of why specific thresholds were chosen and what evidence supports them.
Feedback Loop Neglect
The learn phase of the ODDAL loop is the first thing cut when teams are under delivery pressure. The system detects, diagnoses, and acts — but the outcomes never feed back into the diagnosis model. Over time, the diagnosis model becomes stale. Failure patterns that have been resolved at the root cause level still generate alerts. New failure patterns that weren’t in the original training set get misclassified. The system’s auto-resolution rate plateaus or starts declining. Teams that skip the learn phase end up with a self-healing system that requires more and more manual reconfiguration to stay accurate — gradually converging back on the same maintenance burden it was supposed to eliminate.
Scope Creep in Remediation Actions
Remediation playbooks have a natural tendency to expand. An action that started as “restart the failed service” gets amended over time to “restart the failed service and also clear the cache and also reset the connection pool.” Each amendment makes intuitive sense when it’s added, but the cumulative effect is a remediation action that is no longer idempotent, no longer reversible in a single step, and much harder to audit when something goes wrong. Each remediation action in the playbook should have an explicit scope contract — what it changes, what it does not change, and what validation step confirms the action succeeded. Any amendment to a playbook action should go through the same review process as a code change.
Governance, Audit Trails, and the Accountability Gap
When a human makes a bad decision, there is accountability: a person who made the call, a reasoning chain that can be reviewed, and an organizational process for learning from the error. When an automated system makes a bad decision, the accountability structure often doesn’t exist unless it was deliberately designed in from the start. This gap is not hypothetical — it is the central complaint of every compliance and audit team that has reviewed an AI automation deployment.
What an Audit Trail Must Capture
Every automated action taken by a self-healing system should generate an immutable audit record containing: the timestamp and unique identifier of the incident; the raw telemetry that triggered the alert; the diagnosis output, including failure class, confidence score, and the evidence used to reach that diagnosis; the remediation action selected and the gate level it fell into; whether the action was autonomous or required human approval and — if human-approved — who approved it and when; and the post-remediation validation result confirming whether the action succeeded. This record needs to be stored somewhere that the self-healing system itself cannot modify — either an append-only log store or an external audit system.
Role Clarity: Who Owns the System’s Decisions
In organizations that haven’t explicitly assigned ownership of self-healing automation decisions, audit questions produce paralysis. “Who approved this change?” gets answered with “the system did it automatically” — which is not a satisfactory answer for a regulator, a post-incident review board, or a customer whose data was affected. The governance model should define: a system owner responsible for threshold configuration and playbook review; a review board (at minimum one engineer and one process owner) that approves playbook changes; and an escalation owner who is paged when Gate 3 actions occur. These are not roles that need to be full-time dedicated positions — but they need to be named, documented, and actively maintained.
Review Cadences That Keep Governance Real
Governance that exists only on paper is worse than no governance — it creates the illusion of oversight without the substance. Three review cadences keep self-healing governance meaningful in practice: a weekly review of healing event volume and Gate 1/2/3 distribution (to catch threshold drift early), a monthly review of diagnosis accuracy and false-positive rate (to calibrate the learn phase), and a quarterly full playbook review (to retire stale remediation actions, add new ones for emerging failure patterns, and re-validate scope contracts). Each review should produce a written record — even a brief one — that confirms the review occurred and notes any threshold or playbook changes made as a result.
Building the Feedback Loop That Actually Learns
The learn phase is where self-healing automation creates durable value rather than temporary convenience. Without it, you have a system that responds to failures. With it, you have a system that progressively encounters fewer failures over time — because each incident makes the system smarter about both detecting and preventing the next one. Building this loop in practice requires four specific components that many implementations omit.
Component 1: Outcome Labeling
For the diagnosis model to learn, it needs labeled outcomes: did the remediation action actually resolve the failure, or did the failure recur? This sounds obvious but is frequently absent. Many systems log that an action was taken but not whether it worked. Outcome labeling requires a post-remediation validation step — a check that runs some defined interval after the action to confirm the target system is operating normally and that the same failure signature hasn’t re-appeared. The validation result becomes the ground-truth label that trains the next iteration of the diagnosis model.
Component 2: Pattern Immunization
When a failure pattern has been resolved at root cause — not just remediated at symptom level — the system should update its detection rules to recognize that the pattern has been fixed and should no longer trigger that specific remediation path. This prevents the system from continuing to alert on conditions that no longer exist, which is a major source of alert fatigue in mature deployments. Pattern immunization is the automation equivalent of a doctor updating a patient’s treatment history: “this was a problem, it’s been fixed, don’t keep treating it.”
Component 3: Counterfactual Logging
Counterfactual logging tracks cases where the system would have taken an action but didn’t — either because confidence was too low, or because a human overrode the proposed remediation. These cases are at least as valuable as successful resolutions for training the diagnosis model. A high rate of human overrides on a specific failure class tells you that your diagnosis model is wrong about that class and needs more training data. A high rate of Gate 3 escalations that humans approve without modification tells you the threshold is set too conservatively and could be moved to Gate 2.
Component 4: Replay Testing
Any change to the diagnosis model, remediation playbooks, or confidence thresholds should be validated against a historical dataset of real incidents before it goes to production. Replay testing re-runs past incidents through the updated system and compares the proposed actions against the documented correct resolutions. This catches regressions — cases where a change that improves handling of a new failure pattern inadvertently degrades handling of an existing one. It’s the equivalent of a unit test suite for the self-healing system itself.
Implementation Sequence: Where to Start and What to Instrument First
For teams that are building self-healing automation for the first time, or retrofitting it onto existing pipelines, the sequencing of implementation matters considerably. Teams that try to build all five ODDAL phases simultaneously produce systems that are over-engineered, hard to debug, and often abandoned. The right sequence builds foundation before capability.
Phase 0 (Weeks 1–2): Failure Inventory
Before writing any self-healing code, spend two weeks doing a structured failure inventory of your existing automation. Collect every failure that occurred in the past 90 days, classify it by the five-category taxonomy above, and measure its frequency and resolution time. This inventory tells you where to aim first. In most organizations, this analysis reveals that 60–70% of automation failures fall into the transient and structural drift categories — the two classes that have the most mature self-healing tooling available and where quick wins are achievable.
Phase 1 (Weeks 3–6): Baseline Resilience
Implement the classic resilience stack: retry logic with exponential backoff on all external calls, circuit breakers on high-traffic dependency integrations, and a dead-letter queue for all message-based workflows. Instrument all three layers with metrics. This phase should reduce your overall failure rate by 40–60% before any AI-driven healing is introduced, and it establishes the telemetry baseline the AI diagnosis layer will need.
Phase 2 (Weeks 7–12): Observe and Diagnose
Build the observability layer and the AI diagnosis agent. Start with a narrow failure taxonomy — two or three of the most frequent failure classes identified in your inventory — and train the diagnosis model on historical incident data. Instrument the DLQ to feed the diagnosis agent automatically. At this stage, the agent should produce diagnoses and confidence scores but not take autonomous action yet. This “diagnostic shadow mode” validates accuracy before you give the system any power to act.
Phase 3 (Weeks 13–18): Gate 1 Automation
Enable Gate 1 autonomous actions only — those with high confidence and low impact. This is typically retry-class and service-restart-class remediations. Run for four weeks with close monitoring of healing event volume, auto-resolution correctness, and false-positive rate. Calibrate thresholds based on live performance. Only expand to Gate 2 automation once Gate 1 performance metrics are stable and the audit trail is confirmed to be complete.
Phase 4 (Ongoing): Learn, Expand, and Govern
Introduce Gate 2 actions, activate the learn phase with outcome labeling and replay testing, and establish the three review cadences. Gradually expand the failure taxonomy coverage as the diagnosis model accumulates training data. Treat every human override and every Gate 3 escalation as a learning event, not an operational interruption. Over a well-governed 12-month deployment, teams following this sequence consistently report auto-resolution rates reaching 70–80% of all incidents, with detection accuracy above 90% — numbers that are genuinely transformational for operational teams, but only achievable when the foundation is built correctly.
What Genuine Self-Healing Looks Like at Scale
A few observable characteristics separate systems that are genuinely self-healing from those that are merely self-recovering with a more sophisticated dashboard.
Genuine self-healing systems have a declining incident rate over time. The number of incidents per thousand automation runs decreases month over month, because each resolved incident feeds back into detection and prevention. Systems that are only self-recovering have a flat or rising incident rate — the system handles failures efficiently, but it doesn’t prevent them.
They have traceable healing histories. For any production failure, you can trace the full resolution chain: what was detected, what was diagnosed, what confidence score applied, what action was taken, what validation confirmed the fix. This traceability is not just a governance asset — it’s a diagnostic asset. When something unexpected happens, the audit trail is the fastest path to root cause.
They have improving diagnosis models. The accuracy of failure classification goes up over time, not just at deployment. Teams can point to the training data added from real incidents and show how it changed the model’s behavior on specific failure classes. This is the evidence that the learn phase is actually working rather than being a checkbox.
And they have shrinking human review queues. Gate 2 and Gate 3 escalations decrease in volume as the system learns which actions are safe to automate, and the humans who review escalations report that the system’s proposed remediations are correct and actionable more often than not. Human reviewers stop treating the escalation queue as a source of unexpected surprises and start treating it as a quality-control step for genuinely complex cases — which is exactly what the design intended.
Conclusion: The Discipline Behind the Automation
Self-healing AI automation is a genuine operational capability, not a vendor feature flag. But it is a capability that requires architectural discipline to deliver on its promise — because the same properties that make it effective at handling failures also make it effective at hiding them, if the design is careless.
The framing that tends to produce the best outcomes is this: self-healing automation is not a way to reduce the need for operational vigilance. It is a way to direct operational vigilance toward the failures that actually matter — the complex, ambiguous, structurally significant ones that require human judgment — while handling the high-volume, well-understood failures autonomously. The goal is not to eliminate human attention; it is to make human attention more valuable by focusing it correctly.
The teams that get this right share a common characteristic: they treat the self-healing layer as a first-class engineering concern, not an operational convenience. They invest in the failure taxonomy. They build the observability layer before the healing layer. They set and govern confidence thresholds with the same rigor they apply to security policies. They run the learn phase as a continuous process, not a post-deployment afterthought.
Done right, the numbers are compelling: auto-resolution rates in the 70–80% range, detection accuracy above 90%, MTTR reductions of 30–60%, and — crucially — a declining failure rate that compounds over time as the system accumulates operational history. Done wrong, it produces a very confident-looking system making the same mistakes repeatedly, behind a dashboard that always shows green.
The difference between those two outcomes is almost entirely in the design decisions made before the first line of code is written.
Key Takeaways:
- Classify failures into five distinct types before designing any remediation. Each type needs a different strategy.
- Build the classic resilience stack (retries, circuit breakers, DLQs) first. AI-driven healing augments it — it doesn’t replace it.
- Use a three-gate confidence threshold model to decide when to act autonomously, notify-and-proceed, or halt-and-escalate.
- Monitor for slow failures — drift, schema changes, and model degradation — with specific detection pipelines, not just generic alerting.
- Treat healing event frequency as an alert condition. A spike in healing volume is a signal that something structural needs fixing.
- Build the learn phase from day one. Outcome labeling, pattern immunization, counterfactual logging, and replay testing are what turn self-recovery into genuine self-healing.
- Audit trails are not optional. Every autonomous action needs an immutable record with full context.